 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Convolutional Ranking for Multilabel Image Annotation
Paper and Code
Apr 14, 2014


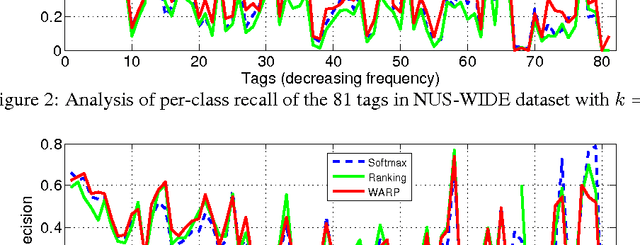
Multilabel image annotation is one of the most important challenges in computer vision with many real-world applications. While existing work usually use conventional visual features for multilabel annotation, features based on Deep Neural Networks have shown potential to significantly boost performance. In this work, we propose to leverage the advantage of such features and analyze key components that lead to better performances. Specifically, we show that a significant performance gain could be obtained by combining convolutional architectures with approximate top-$k$ ranking objectives, as thye naturally fit the multilabel tagging problem. Our experiments on the NUS-WIDE dataset outperforms the conventional visual features by about 10%, obtaining the best reported performance in the literature.