 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVAC: Learned Volumetric Attribute Compression for Point Clouds using Coordinate Based Networks
Nov 17, 2021
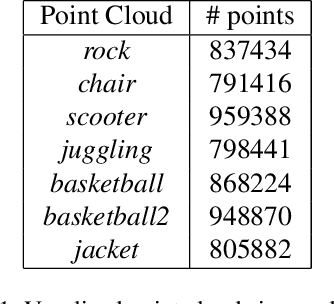
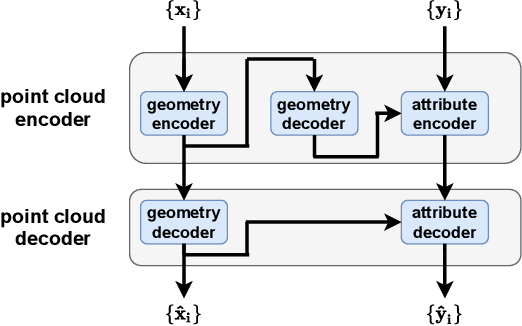
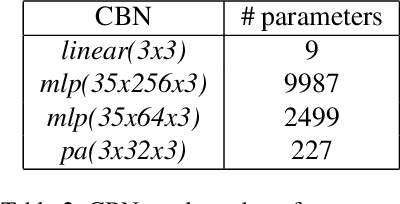
We consider the attributes of a point cloud as samples of a vector-valued volumetric function at discrete positions. To compress the attributes given the positions, we compress the parameters of the volumetric function. We model the volumetric function by tiling space into blocks, and representing the function over each block by shifts of a coordinate-based, or implicit, neural network. Inputs to the network include both spatial coordinates and a latent vector per block. We represent the latent vectors using coefficients of the region-adaptive hierarchical transform (RAHT) used in the MPEG geometry-based point cloud codec G-PCC. The coefficients, which are highly compressible, are rate-distortion optimized by back-propagation through a rate-distortion Lagrangian loss in an auto-decoder configuration. The result outperforms RAHT by 2--4 dB. This is the first work to compress volumetric functions represented by local coordinate-based neural networks. As such, we expect it to be applicable beyond point clouds, for example to compression of high-resolution neural radiance fields.
Towards a Semantic Perceptual Image Metric
Aug 01, 2018
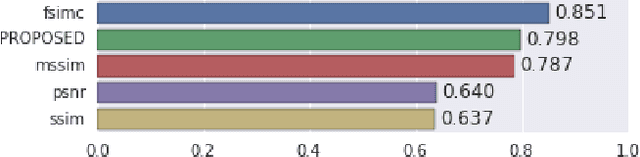
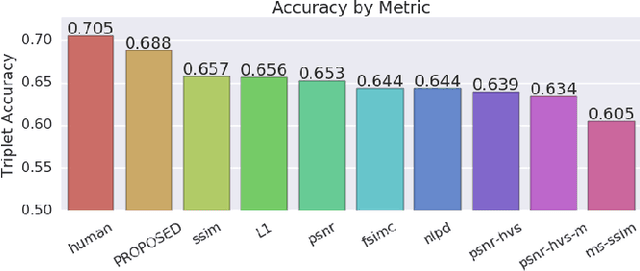

We present a full reference, perceptual image metric based on VGG-16, an artificial neural network trained on object classification. We fit the metric to a new database based on 140k unique images annotated with ground truth by human raters who received minimal instruction. The resulting metric shows competitive performance on TID 2013, a database widely used to assess image quality assessments methods. More interestingly, it shows strong responses to objects potentially carrying semantic relevance such as faces and text, which we demonstrate using a visualization technique and ablation experiments. In effect, the metric appears to model a higher influence of semantic context on judgments, which we observe particularly in untrained raters. As the vast majority of users of image processing systems are unfamiliar with Image Quality Assessment (IQA) tasks, these findings may have significant impact on real-world applications of perceptual metrics.
Image-Dependent Local Entropy Models for Learned Image Compression
May 31, 2018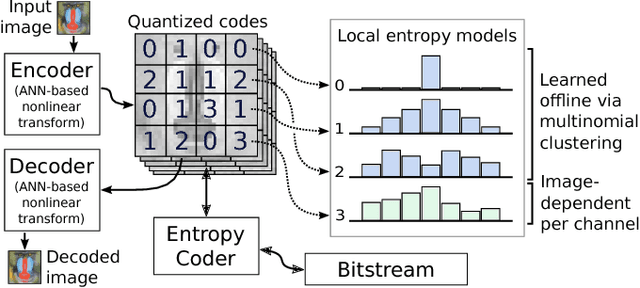

The leading approach for image compression with artificial neural networks (ANNs) is to learn a nonlinear transform and a fixed entropy model that are optimized for rate-distortion performance. We show that this approach can be significantly improved by incorporating spatially local, image-dependent entropy models. The key insight is that existing ANN-based methods learn an entropy model that is shared between the encoder and decoder, but they do not transmit any side information that would allow the model to adapt to the structure of a specific image. We present a method for augmenting ANN-based image coders with image-dependent side information that leads to a 17.8% rate reduction over a state-of-the-art ANN-based baseline model on a standard evaluation set, and 70-98% reductions on images with low visual complexity that are poorly captured by a fixed, global entropy model.
Spatially adaptive image compression using a tiled deep network
Feb 07, 2018
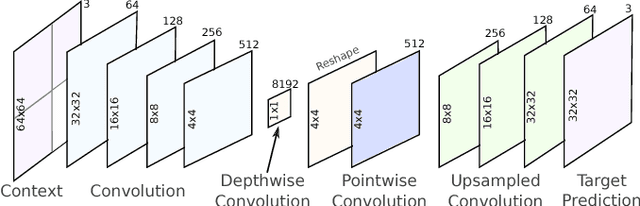

Deep neural networks represent a powerful class of function approximators that can learn to compress and reconstruct images. Existing image compression algorithms based on neural networks learn quantized representations with a constant spatial bit rate across each image. While entropy coding introduces some spatial variation, traditional codecs have benefited significantly by explicitly adapting the bit rate based on local image complexity and visual saliency. This paper introduces an algorithm that combines deep neural networks with quality-sensitive bit rate adaptation using a tiled network. We demonstrate the importance of spatial context prediction and show improved quantitative (PSNR) and qualitative (subjective rater assessment) results compared to a non-adaptive baseline and a recently published image compression model based on fully-convolutional neural networks.
Full Resolution Image Compression with Recurrent Neural Networks
Jul 07, 2017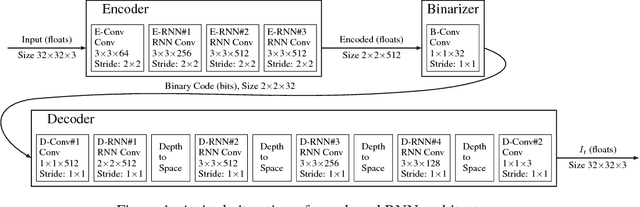
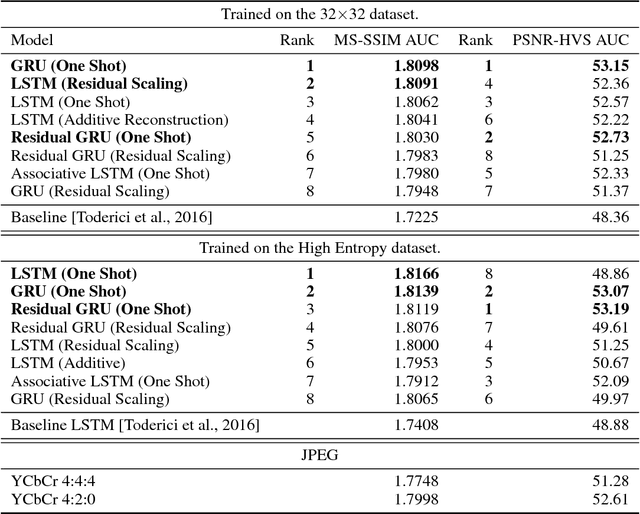
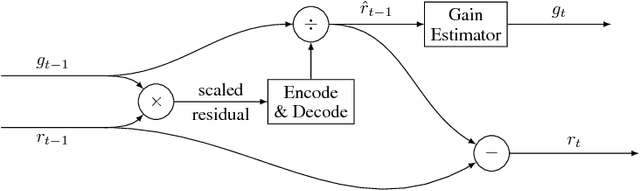
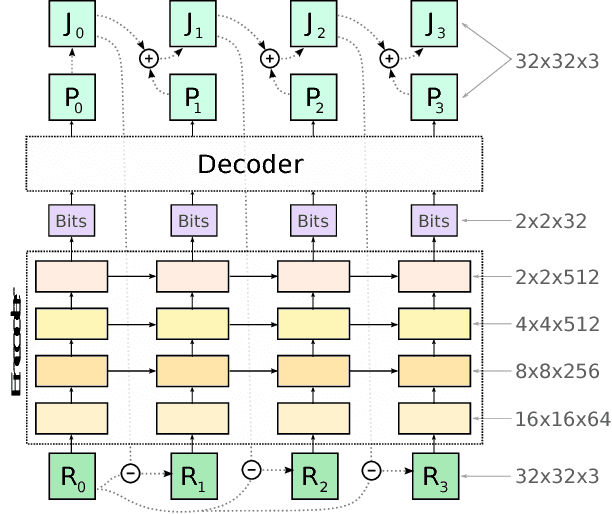
This paper presents a set of full-resolution lossy image compression methods based on neural networks. Each of the architectures we describe can provide variable compression rates during deployment without requiring retraining of the network: each network need only be trained once. All of our architectures consist of a recurrent neural network (RNN)-based encoder and decoder, a binarizer, and a neural network for entropy coding. We compare RNN types (LSTM, associative LSTM) and introduce a new hybrid of GRU and ResNet. We also study "one-shot" versus additive reconstruction architectures and introduce a new scaled-additive framework. We compare to previous work, showing improvements of 4.3%-8.8% AUC (area under the rate-distortion curve), depending on the perceptual metric used. As far as we know, this is the first neural network architecture that is able to outperform JPEG at image compression across most bitrates on the rate-distortion curve on the Kodak dataset images, with and without the aid of entropy coding.
Target-Quality Image Compression with Recurrent, Convolutional Neural Networks
May 18, 2017
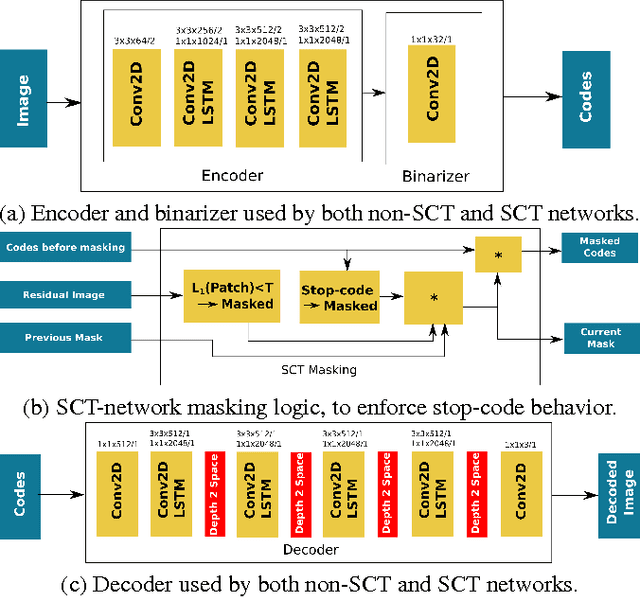
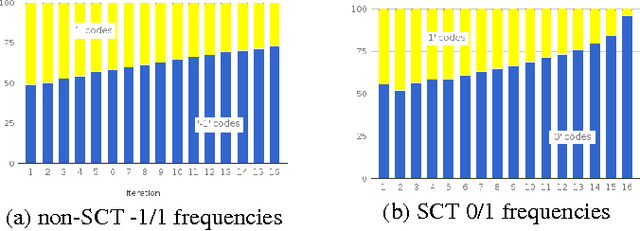

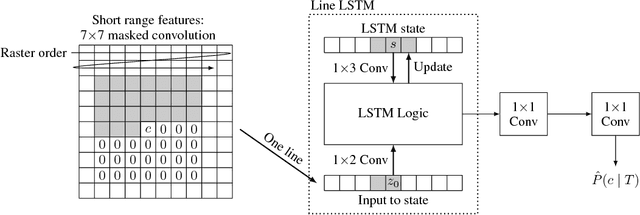
We introduce a stop-code tolerant (SCT) approach to training recurrent convolutional neural networks for lossy image compression. Our methods introduce a multi-pass training method to combine the training goals of high-quality reconstructions in areas around stop-code masking as well as in highly-detailed areas. These methods lead to lower true bitrates for a given recursion count, both pre- and post-entropy coding, even using unstructured LZ77 code compression. The pre-LZ77 gains are achieved by trimming stop codes. The post-LZ77 gains are due to the highly unequal distributions of 0/1 codes from the SCT architectures. With these code compressions, the SCT architecture maintains or exceeds the image quality at all compression rates compared to JPEG and to RNN auto-encoders across the Kodak dataset. In addition, the SCT coding results in lower variance in image quality across the extent of the image, a characteristic that has been shown to be important in human ratings of image quality
Improved Lossy Image Compression with Priming and Spatially Adaptive Bit Rates for Recurrent Networks
Mar 29, 2017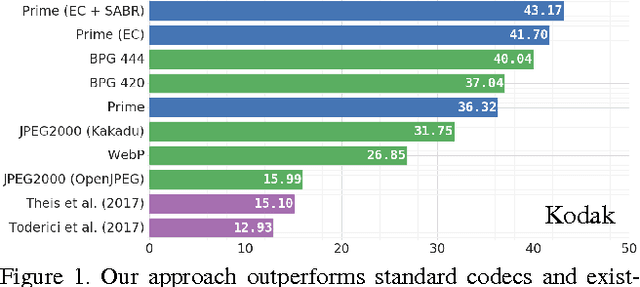
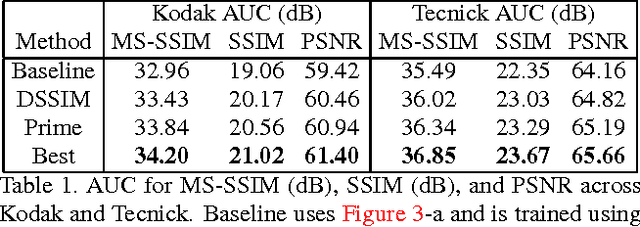
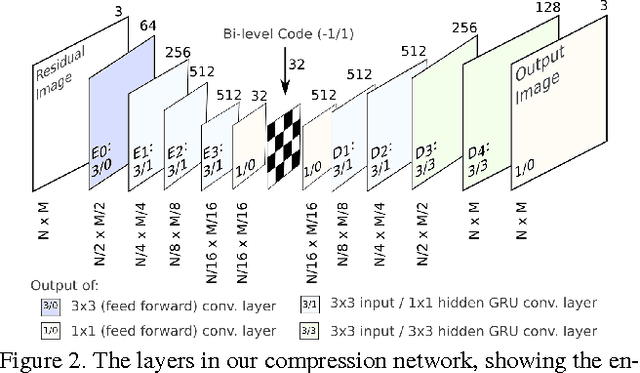
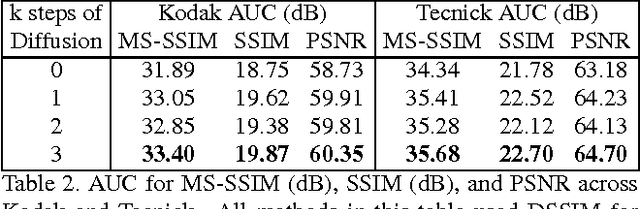
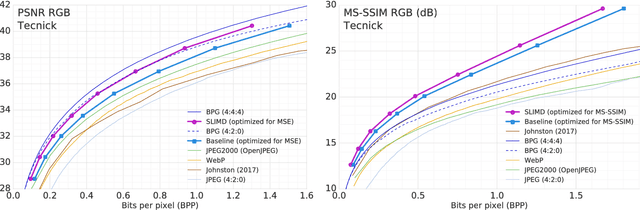
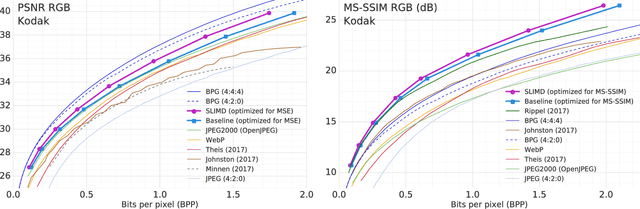
We propose a method for lossy image compression based on recurrent, convolutional neural networks that outperforms BPG (4:2:0 ), WebP, JPEG2000, and JPEG as measured by MS-SSIM. We introduce three improvements over previous research that lead to this state-of-the-art result. First, we show that training with a pixel-wise loss weighted by SSIM increases reconstruction quality according to several metrics. Second, we modify the recurrent architecture to improve spatial diffusion, which allows the network to more effectively capture and propagate image information through the network's hidden state. Finally, in addition to lossless entropy coding, we use a spatially adaptive bit allocation algorithm to more efficiently use the limited number of bits to encode visually complex image regions. We evaluate our method on the Kodak and Tecnick image sets and compare against standard codecs as well recently published methods based on deep neural networks.
Variable Rate Image Compression with Recurrent Neural Networks
Mar 01, 2016
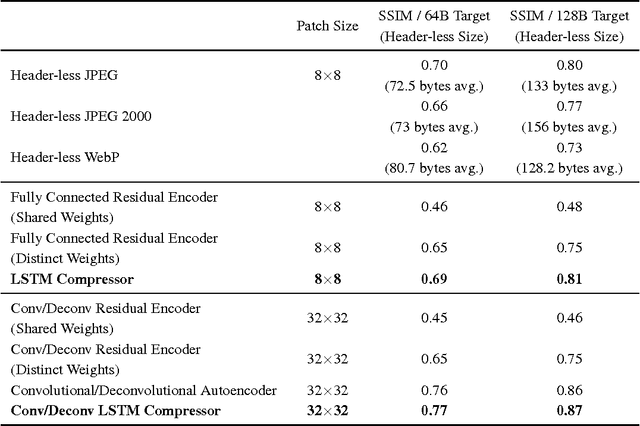
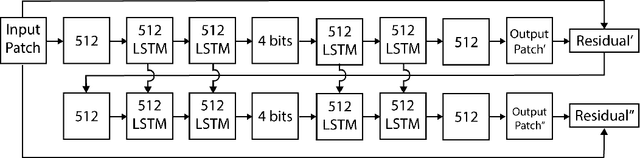

A large fraction of Internet traffic is now driven by requests from mobile devices with relatively small screens and often stringent bandwidth requirements. Due to these factors, it has become the norm for modern graphics-heavy websites to transmit low-resolution, low-bytecount image previews (thumbnails) as part of the initial page load process to improve apparent page responsiveness. Increasing thumbnail compression beyond the capabilities of existing codecs is therefore a current research focus, as any byte savings will significantly enhance the experience of mobile device users. Toward this end, we propose a general framework for variable-rate image compression and a novel architecture based on convolutional and deconvolutional LSTM recurrent networks. Our models address the main issues that have prevented autoencoder neural networks from competing with existing image compression algorithms: (1) our networks only need to be trained once (not per-image), regardless of input image dimensions and the desired compression rate; (2) our networks are progressive, meaning that the more bits are sent, the more accurate the image reconstruction; and (3) the proposed architecture is at least as efficient as a standard purpose-trained autoencoder for a given number of bits. On a large-scale benchmark of 32$\times$32 thumbnails, our LSTM-based approaches provide better visual quality than (headerless) JPEG, JPEG2000 and WebP, with a storage size that is reduced by 10% or more.