 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Magic Correlations: Understanding Knowledge Transfer from Pretraining to Supervised Fine-Tuning
Feb 11, 2026Understanding how language model capabilities transfer from pretraining to supervised fine-tuning (SFT) is fundamental to efficient model development and data curation. In this work, we investigate four core questions: RQ1. To what extent do accuracy and confidence rankings established during pretraining persist after SFT? RQ2. Which benchmarks serve as robust cross-stage predictors and which are unreliable? RQ3. How do transfer dynamics shift with model scale? RQ4. How well does model confidence align with accuracy, as a measure of calibration quality? Does this alignment pattern transfer across training stages? We address these questions through a suite of correlation protocols applied to accuracy and confidence metrics across diverse data mixtures and model scales. Our experiments reveal that transfer reliability varies dramatically across capability categories, benchmarks, and scales -- with accuracy and confidence exhibiting distinct, sometimes opposing, scaling dynamics. These findings shed light on the complex interplay between pretraining decisions and downstream outcomes, providing actionable guidance for benchmark selection, data curation, and efficient model development.
Successive Halving with Learning Curve Prediction via Latent Kronecker Gaussian Processes
Aug 20, 2025Successive Halving is a popular algorithm for hyperparameter optimization which allocates exponentially more resources to promising candidates. However, the algorithm typically relies on intermediate performance values to make resource allocation decisions, which can cause it to prematurely prune slow starters that would eventually become the best candidate. We investigate whether guiding Successive Halving with learning curve predictions based on Latent Kronecker Gaussian Processes can overcome this limitation. In a large-scale empirical study involving different neural network architectures and a click prediction dataset, we compare this predictive approach to the standard approach based on current performance values. Our experiments show that, although the predictive approach achieves competitive performance, it is not Pareto optimal compared to investing more resources into the standard approach, because it requires fully observed learning curves as training data. However, this downside could be mitigated by leveraging existing learning curve data.
Leveraging Per-Instance Privacy for Machine Unlearning
May 24, 2025We present a principled, per-instance approach to quantifying the difficulty of unlearning via fine-tuning. We begin by sharpening an analysis of noisy gradient descent for unlearning (Chien et al., 2024), obtaining a better utility-unlearning tradeoff by replacing worst-case privacy loss bounds with per-instance privacy losses (Thudi et al., 2024), each of which bounds the (Renyi) divergence to retraining without an individual data point. To demonstrate the practical applicability of our theory, we present empirical results showing that our theoretical predictions are born out both for Stochastic Gradient Langevin Dynamics (SGLD) as well as for standard fine-tuning without explicit noise. We further demonstrate that per-instance privacy losses correlate well with several existing data difficulty metrics, while also identifying harder groups of data points, and introduce novel evaluation methods based on loss barriers. All together, our findings provide a foundation for more efficient and adaptive unlearning strategies tailored to the unique properties of individual data points.
Differentially Private Adaptation of Diffusion Models via Noisy Aggregated Embeddings
Nov 22, 2024

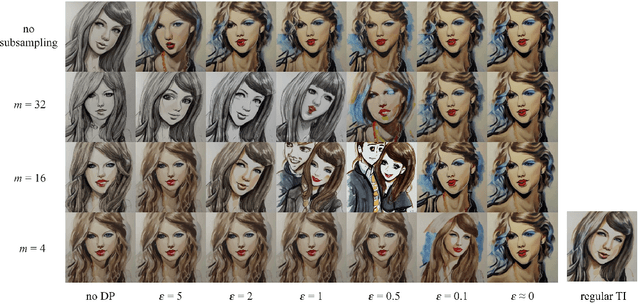
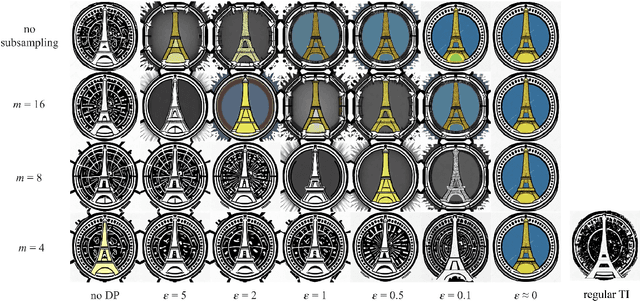
We introduce novel methods for adapting diffusion models under differential privacy (DP) constraints, enabling privacy-preserving style and content transfer without fine-tuning. Traditional approaches to private adaptation, such as DP-SGD, incur significant computational overhead and degrade model performance when applied to large, complex models. Our approach instead leverages embedding-based techniques: Universal Guidance and Textual Inversion (TI), adapted with differentially private mechanisms. We apply these methods to Stable Diffusion for style adaptation using two private datasets: a collection of artworks by a single artist and pictograms from the Paris 2024 Olympics. Experimental results show that the TI-based adaptation achieves superior fidelity in style transfer, even under strong privacy guarantees, while both methods maintain high privacy resilience by employing calibrated noise and subsampling strategies. Our findings demonstrate a feasible and efficient pathway for privacy-preserving diffusion model adaptation, balancing data protection with the fidelity of generated images, and offer insights into embedding-driven methods for DP in generative AI applications.
Lottery Ticket Adaptation: Mitigating Destructive Interference in LLMs
Jun 25, 2024



Existing methods for adapting large language models (LLMs) to new tasks are not suited to multi-task adaptation because they modify all the model weights -- causing destructive interference between tasks. The resulting effects, such as catastrophic forgetting of earlier tasks, make it challenging to obtain good performance on multiple tasks at the same time. To mitigate this, we propose Lottery Ticket Adaptation (LoTA), a sparse adaptation method that identifies and optimizes only a sparse subnetwork of the model. We evaluate LoTA on a wide range of challenging tasks such as instruction following, reasoning, math, and summarization. LoTA obtains better performance than full fine-tuning and low-rank adaptation (LoRA), and maintains good performance even after training on other tasks -- thus, avoiding catastrophic forgetting. By extracting and fine-tuning over lottery tickets (or sparse task vectors), LoTA also enables model merging over highly dissimilar tasks. Our code is made publicly available at https://github.com/kiddyboots216/lottery-ticket-adaptation.
Towards an Improved Understanding and Utilization of Maximum Manifold Capacity Representations
Jun 13, 2024Maximum Manifold Capacity Representations (MMCR) is a recent multi-view self-supervised learning (MVSSL) method that matches or surpasses other leading MVSSL methods. MMCR is intriguing because it does not fit neatly into any of the commonplace MVSSL lineages, instead originating from a statistical mechanical perspective on the linear separability of data manifolds. In this paper, we seek to improve our understanding and our utilization of MMCR. To better understand MMCR, we leverage tools from high dimensional probability to demonstrate that MMCR incentivizes alignment and uniformity of learned embeddings. We then leverage tools from information theory to show that such embeddings maximize a well-known lower bound on mutual information between views, thereby connecting the geometric perspective of MMCR to the information-theoretic perspective commonly discussed in MVSSL. To better utilize MMCR, we mathematically predict and experimentally confirm non-monotonic changes in the pretraining loss akin to double descent but with respect to atypical hyperparameters. We also discover compute scaling laws that enable predicting the pretraining loss as a function of gradients steps, batch size, embedding dimension and number of views. We then show that MMCR, originally applied to image data, is performant on multimodal image-text data. By more deeply understanding the theoretical and empirical behavior of MMCR, our work reveals insights on improving MVSSL methods.
On Fairness of Low-Rank Adaptation of Large Models
May 27, 2024Low-rank adaptation of large models, particularly LoRA, has gained traction due to its computational efficiency. This efficiency, contrasted with the prohibitive costs of full-model fine-tuning, means that practitioners often turn to LoRA and sometimes without a complete understanding of its ramifications. In this study, we focus on fairness and ask whether LoRA has an unexamined impact on utility, calibration, and resistance to membership inference across different subgroups (e.g., genders, races, religions) compared to a full-model fine-tuning baseline. We present extensive experiments across vision and language domains and across classification and generation tasks using ViT-Base, Swin-v2-Large, Llama-2 7B, and Mistral 7B. Intriguingly, experiments suggest that while one can isolate cases where LoRA exacerbates model bias across subgroups, the pattern is inconsistent -- in many cases, LoRA has equivalent or even improved fairness compared to the base model or its full fine-tuning baseline. We also examine the complications of evaluating fine-tuning fairness relating to task design and model token bias, calling for more careful fairness evaluations in future work.
Improved Communication-Privacy Trade-offs in $L_2$ Mean Estimation under Streaming Differential Privacy
May 02, 2024



We study $L_2$ mean estimation under central differential privacy and communication constraints, and address two key challenges: firstly, existing mean estimation schemes that simultaneously handle both constraints are usually optimized for $L_\infty$ geometry and rely on random rotation or Kashin's representation to adapt to $L_2$ geometry, resulting in suboptimal leading constants in mean square errors (MSEs); secondly, schemes achieving order-optimal communication-privacy trade-offs do not extend seamlessly to streaming differential privacy (DP) settings (e.g., tree aggregation or matrix factorization), rendering them incompatible with DP-FTRL type optimizers. In this work, we tackle these issues by introducing a novel privacy accounting method for the sparsified Gaussian mechanism that incorporates the randomness inherent in sparsification into the DP noise. Unlike previous approaches, our accounting algorithm directly operates in $L_2$ geometry, yielding MSEs that fast converge to those of the uncompressed Gaussian mechanism. Additionally, we extend the sparsification scheme to the matrix factorization framework under streaming DP and provide a precise accountant tailored for DP-FTRL type optimizers. Empirically, our method demonstrates at least a 100x improvement of compression for DP-SGD across various FL tasks.
Sandwiched Compression: Repurposing Standard Codecs with Neural Network Wrappers
Feb 08, 2024
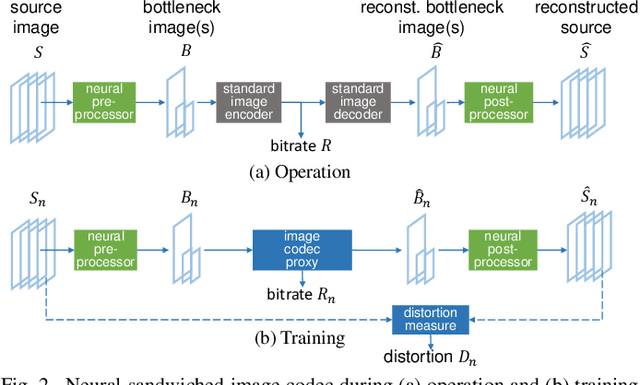
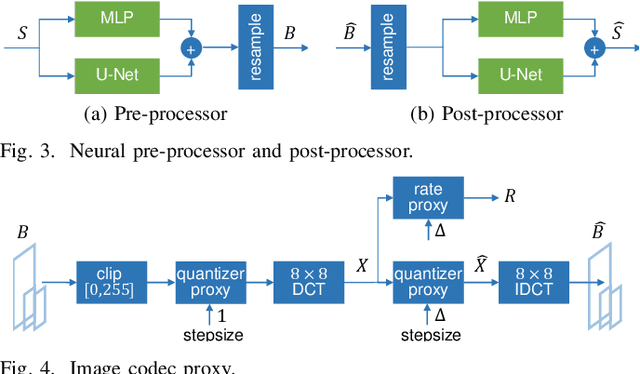
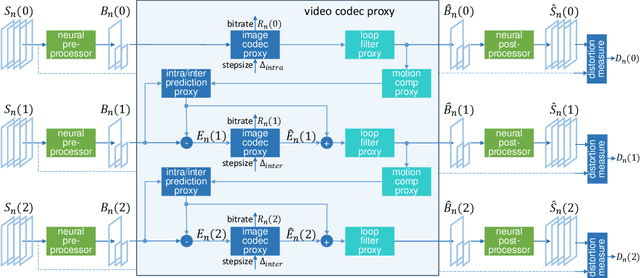
We propose sandwiching standard image and video codecs between pre- and post-processing neural networks. The networks are jointly trained through a differentiable codec proxy to minimize a given rate-distortion loss. This sandwich architecture not only improves the standard codec's performance on its intended content, it can effectively adapt the codec to other types of image/video content and to other distortion measures. Essentially, the sandwich learns to transmit ``neural code images'' that optimize overall rate-distortion performance even when the overall problem is well outside the scope of the codec's design. Through a variety of examples, we apply the sandwich architecture to sources with different numbers of channels, higher resolution, higher dynamic range, and perceptual distortion measures. The results demonstrate substantial improvements (up to 9 dB gains or up to 30\% bitrate reductions) compared to alternative adaptations. We derive VQ equivalents for the sandwich, establish optimality properties, and design differentiable codec proxies approximating current standard codecs. We further analyze model complexity, visual quality under perceptual metrics, as well as sandwich configurations that offer interesting potentials in image/video compression and streaming.
Scaling Laws for Downstream Task Performance of Large Language Models
Feb 06, 2024



Scaling laws provide important insights that can guide the design of large language models (LLMs). Existing work has primarily focused on studying scaling laws for pretraining (upstream) loss. However, in transfer learning settings, in which LLMs are pretrained on an unsupervised dataset and then finetuned on a downstream task, we often also care about the downstream performance. In this work, we study the scaling behavior in a transfer learning setting, where LLMs are finetuned for machine translation tasks. Specifically, we investigate how the choice of the pretraining data and its size affect downstream performance (translation quality) as judged by two metrics: downstream cross-entropy and BLEU score. Our experiments indicate that the size of the finetuning dataset and the distribution alignment between the pretraining and downstream data significantly influence the scaling behavior. With sufficient alignment, both downstream cross-entropy and BLEU score improve monotonically with more pretraining data. In such cases, we show that it is possible to predict the downstream BLEU score with good accuracy using a log-law. However, there are also cases where moderate misalignment causes the BLEU score to fluctuate or get worse with more pretraining, whereas downstream cross-entropy monotonically improves. By analyzing these observations, we provide new practical insights for choosing appropriate pretraining data.