 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Per-Instance Privacy for Machine Unlearning
May 24, 2025We present a principled, per-instance approach to quantifying the difficulty of unlearning via fine-tuning. We begin by sharpening an analysis of noisy gradient descent for unlearning (Chien et al., 2024), obtaining a better utility-unlearning tradeoff by replacing worst-case privacy loss bounds with per-instance privacy losses (Thudi et al., 2024), each of which bounds the (Renyi) divergence to retraining without an individual data point. To demonstrate the practical applicability of our theory, we present empirical results showing that our theoretical predictions are born out both for Stochastic Gradient Langevin Dynamics (SGLD) as well as for standard fine-tuning without explicit noise. We further demonstrate that per-instance privacy losses correlate well with several existing data difficulty metrics, while also identifying harder groups of data points, and introduce novel evaluation methods based on loss barriers. All together, our findings provide a foundation for more efficient and adaptive unlearning strategies tailored to the unique properties of individual data points.
Data Selection for Transfer Unlearning
May 16, 2024As deep learning models are becoming larger and data-hungrier, there are growing ethical, legal and technical concerns over use of data: in practice, agreements on data use may change over time, rendering previously-used training data impermissible for training purposes. These issues have driven increased attention to machine unlearning: removing "the influence of" a subset of training data from a trained model. In this work, we advocate for a relaxed definition of unlearning that does not address privacy applications but targets a scenario where a data owner withdraws permission of use of their data for training purposes. In this context, we consider the important problem of \emph{transfer unlearning} where a pretrained model is transferred to a target dataset that contains some "non-static" data that may need to be unlearned in the future. We propose a new method that uses a mechanism for selecting relevant examples from an auxiliary "static" dataset, and finetunes on the selected data instead of "non-static" target data; addressing all unlearning requests ahead of time. We also adapt a recent relaxed definition of unlearning to our problem setting and demonstrate that our approach is an exact transfer unlearner according to it, while being highly efficient (amortized). We find that our method outperforms the gold standard "exact unlearning" (finetuning on only the "static" portion of the target dataset) on several datasets, especially for small "static" sets, sometimes approaching an upper bound for test accuracy. We also analyze factors influencing the accuracy boost obtained by data selection.
HAD-Net: A Hierarchical Adversarial Knowledge Distillation Network for Improved Enhanced Tumour Segmentation Without Post-Contrast Images
Apr 09, 2021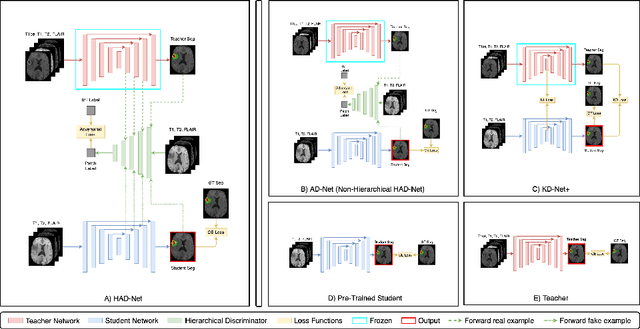

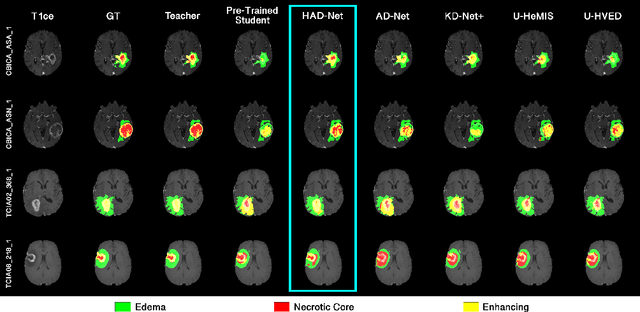

Segmentation of enhancing tumours or lesions from MRI is important for detecting new disease activity in many clinical contexts. However, accurate segmentation requires the inclusion of medical images (e.g., T1 post contrast MRI) acquired after injecting patients with a contrast agent (e.g., Gadolinium), a process no longer thought to be safe. Although a number of modality-agnostic segmentation networks have been developed over the past few years, they have been met with limited success in the context of enhancing pathology segmentation. In this work, we present HAD-Net, a novel offline adversarial knowledge distillation (KD) technique, whereby a pre-trained teacher segmentation network, with access to all MRI sequences, teaches a student network, via hierarchical adversarial training, to better overcome the large domain shift presented when crucial images are absent during inference. In particular, we apply HAD-Net to the challenging task of enhancing tumour segmentation when access to post-contrast imaging is not available. The proposed network is trained and tested on the BraTS 2019 brain tumour segmentation challenge dataset, where it achieves performance improvements in the ranges of 16% - 26% over (a) recent modality-agnostic segmentation methods (U-HeMIS, U-HVED), (b) KD-Net adapted to this problem, (c) the pre-trained student network and (d) a non-hierarchical version of the network (AD-Net), in terms of Dice scores for enhancing tumour (ET). The network also shows improvements in tumour core (TC) Dice scores. Finally, the network outperforms both the baseline student network and AD-Net in terms of uncertainty quantification for enhancing tumour segmentation based on the BraTs 2019 uncertainty challenge metrics. Our code is publicly available at: https://github.com/SaverioVad/HAD_Net