 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Compound AI Systems via System-level DPO
Feb 24, 2025Compound AI systems, comprising multiple interacting components such as LLM agents and external tools, demonstrate state-of-the-art results across diverse tasks. It is hence crucial to align components within the system to produce consistent results that match human expectations. However, conventional alignment methods, such as Direct Preference Optimization (DPO), are not directly applicable to compound AI systems. These challenges include the non-differentiable interactions between components, making end-to-end gradient optimization infeasible. Additionally, system-level preferences cannot be directly translated into component-level preferences, further complicating alignment. We address the issues by formulating compound AI systems as Directed Acyclic Graphs (DAGs), capturing the connections between agents and the data generation processes. We propose a system-level DPO (SysDPO) to jointly align compound systems by adapting the DPO to operate on these DAGs. We study the joint alignment of an LLM and a diffusion model to demonstrate the effectiveness of our approach. Our exploration provides insights into the alignment of compound AI systems and lays a foundation for future advancements.
On Fairness of Low-Rank Adaptation of Large Models
May 27, 2024Low-rank adaptation of large models, particularly LoRA, has gained traction due to its computational efficiency. This efficiency, contrasted with the prohibitive costs of full-model fine-tuning, means that practitioners often turn to LoRA and sometimes without a complete understanding of its ramifications. In this study, we focus on fairness and ask whether LoRA has an unexamined impact on utility, calibration, and resistance to membership inference across different subgroups (e.g., genders, races, religions) compared to a full-model fine-tuning baseline. We present extensive experiments across vision and language domains and across classification and generation tasks using ViT-Base, Swin-v2-Large, Llama-2 7B, and Mistral 7B. Intriguingly, experiments suggest that while one can isolate cases where LoRA exacerbates model bias across subgroups, the pattern is inconsistent -- in many cases, LoRA has equivalent or even improved fairness compared to the base model or its full fine-tuning baseline. We also examine the complications of evaluating fine-tuning fairness relating to task design and model token bias, calling for more careful fairness evaluations in future work.
DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection
Apr 01, 2023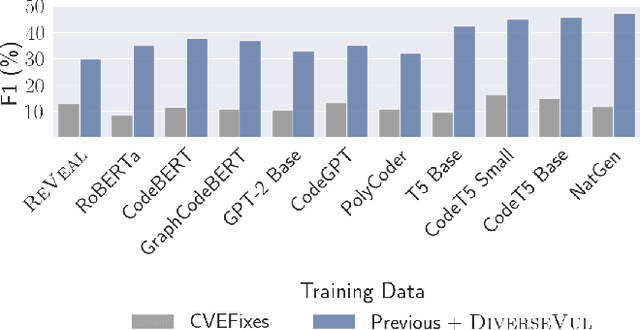
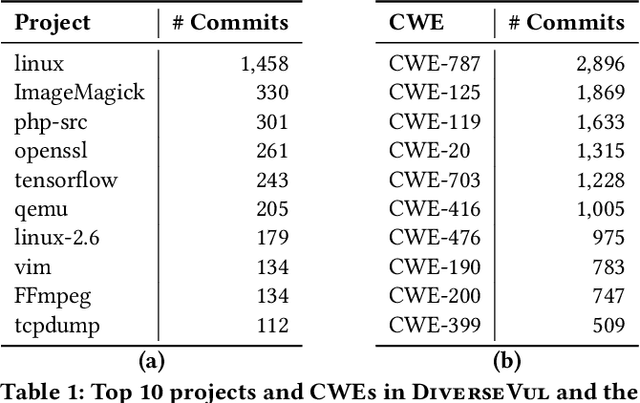

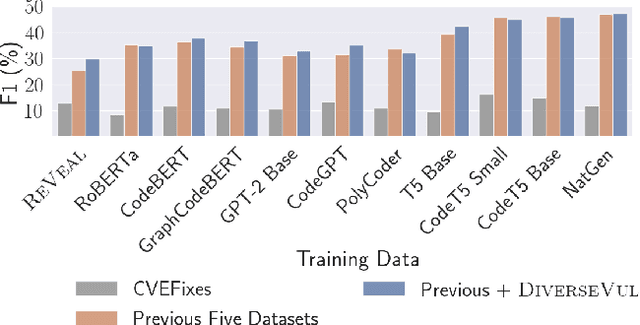
We propose and release a new vulnerable source code dataset. We curate the dataset by crawling security issue websites, extracting vulnerability-fixing commits and source codes from the corresponding projects. Our new dataset contains 150 CWEs, 26,635 vulnerable functions, and 352,606 non-vulnerable functions extracted from 7,861 commits. Our dataset covers 305 more projects than all previous datasets combined. We show that increasing the diversity and volume of training data improves the performance of deep learning models for vulnerability detection. Combining our new dataset with previous datasets, we present an analysis of the challenges and promising research directions of using deep learning for detecting software vulnerabilities. We study 11 model architectures belonging to 4 families. Our results show that deep learning is still not ready for vulnerability detection, due to high false positive rate, low F1 score, and difficulty of detecting hard CWEs. In particular, we demonstrate an important generalization challenge for the deployment of deep learning-based models. However, we also identify hopeful future research directions. We demonstrate that large language models (LLMs) are the future for vulnerability detection, outperforming Graph Neural Networks (GNNs) with manual feature engineering. Moreover, developing source code specific pre-training objectives is a promising research direction to improve the vulnerability detection performance.
Continuous Learning for Android Malware Detection
Feb 08, 2023
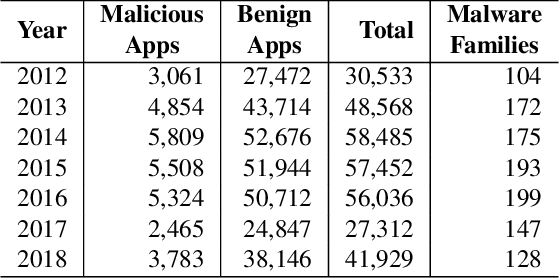
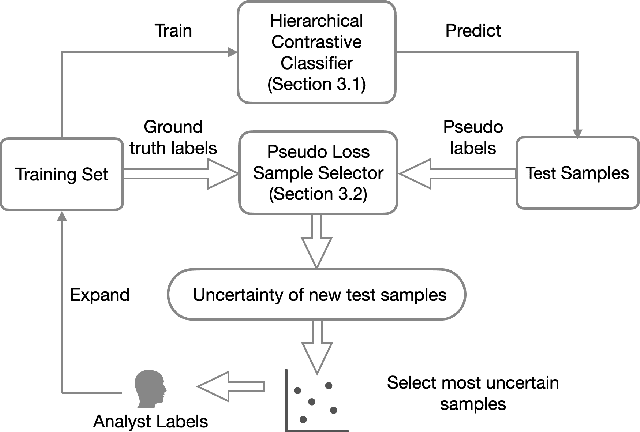
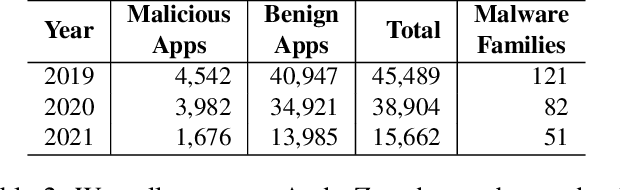
Machine learning methods can detect Android malware with very high accuracy. However, these classifiers have an Achilles heel, concept drift: they rapidly become out of date and ineffective, due to the evolution of malware apps and benign apps. Our research finds that, after training an Android malware classifier on one year's worth of data, the F1 score quickly dropped from 0.99 to 0.76 after 6 months of deployment on new test samples. In this paper, we propose new methods to combat the concept drift problem of Android malware classifiers. Since machine learning technique needs to be continuously deployed, we use active learning: we select new samples for analysts to label, and then add the labeled samples to the training set to retrain the classifier. Our key idea is, similarity-based uncertainty is more robust against concept drift. Therefore, we combine contrastive learning with active learning. We propose a new hierarchical contrastive learning scheme, and a new sample selection technique to continuously train the Android malware classifier. Our evaluation shows that this leads to significant improvements, compared to previously published methods for active learning. Our approach reduces the false negative rate from 16% (for the best baseline) to 10%, while maintaining the same false positive rate (0.6%). Also, our approach maintains more consistent performance across a seven-year time period than past methods.