 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection
Paper and Code
Apr 01, 2023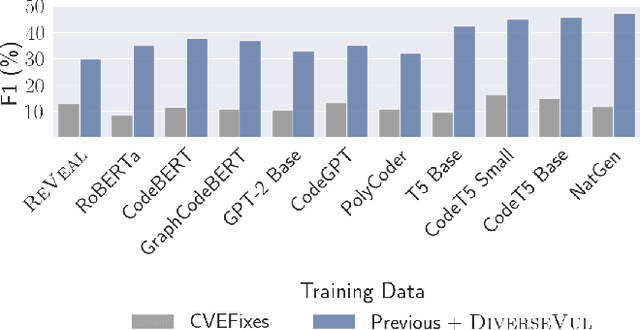
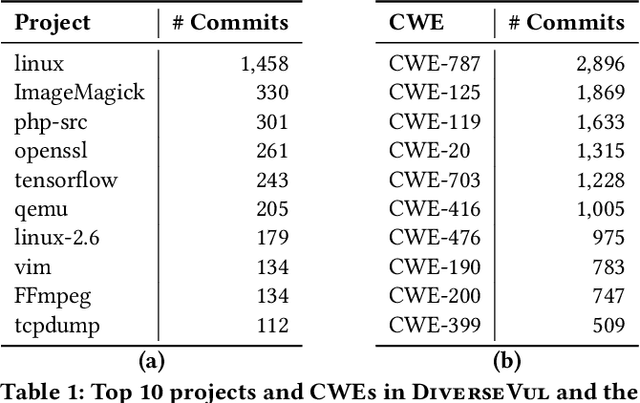

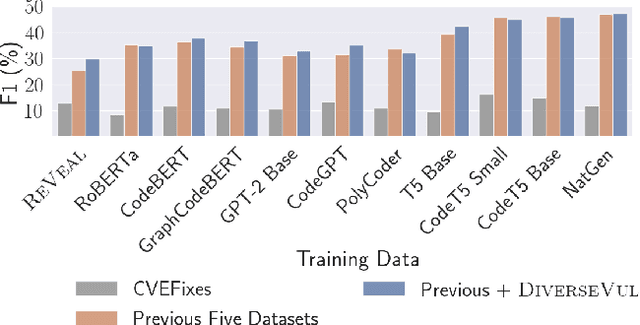
We propose and release a new vulnerable source code dataset. We curate the dataset by crawling security issue websites, extracting vulnerability-fixing commits and source codes from the corresponding projects. Our new dataset contains 150 CWEs, 26,635 vulnerable functions, and 352,606 non-vulnerable functions extracted from 7,861 commits. Our dataset covers 305 more projects than all previous datasets combined. We show that increasing the diversity and volume of training data improves the performance of deep learning models for vulnerability detection. Combining our new dataset with previous datasets, we present an analysis of the challenges and promising research directions of using deep learning for detecting software vulnerabilities. We study 11 model architectures belonging to 4 families. Our results show that deep learning is still not ready for vulnerability detection, due to high false positive rate, low F1 score, and difficulty of detecting hard CWEs. In particular, we demonstrate an important generalization challenge for the deployment of deep learning-based models. However, we also identify hopeful future research directions. We demonstrate that large language models (LLMs) are the future for vulnerability detection, outperforming Graph Neural Networks (GNNs) with manual feature engineering. Moreover, developing source code specific pre-training objectives is a promising research direction to improve the vulnerability detection performance.