 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandard compliant video coding using low complexity, switchable neural wrappers
Jul 10, 2024The proliferation of high resolution videos posts great storage and bandwidth pressure on cloud video services, driving the development of next-generation video codecs. Despite great progress made in neural video coding, existing approaches are still far from economical deployment considering the complexity and rate-distortion performance tradeoff. To clear the roadblocks for neural video coding, in this paper we propose a new framework featuring standard compatibility, high performance, and low decoding complexity. We employ a set of jointly optimized neural pre- and post-processors, wrapping a standard video codec, to encode videos at different resolutions. The rate-distorion optimal downsampling ratio is signaled to the decoder at the per-sequence level for each target rate. We design a low complexity neural post-processor architecture that can handle different upsampling ratios. The change of resolution exploits the spatial redundancy in high-resolution videos, while the neural wrapper further achieves rate-distortion performance improvement through end-to-end optimization with a codec proxy. Our light-weight post-processor architecture has a complexity of 516 MACs / pixel, and achieves 9.3% BD-Rate reduction over VVC on the UVG dataset, and 6.4% on AOM CTC Class A1. Our approach has the potential to further advance the performance of the latest video coding standards using neural processing with minimal added complexity.
One-Click Upgrade from 2D to 3D: Sandwiched RGB-D Video Compression for Stereoscopic Teleconferencing
Apr 15, 2024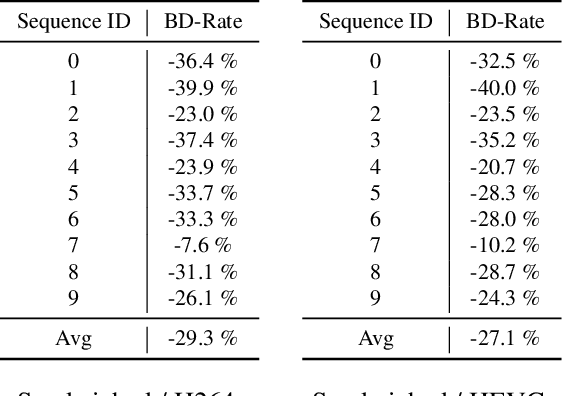
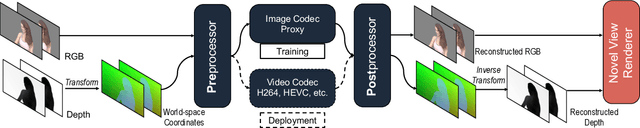
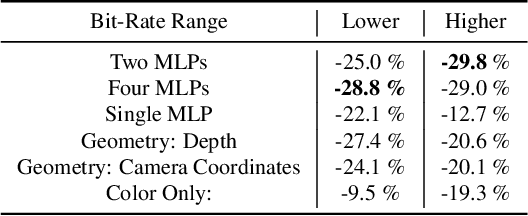
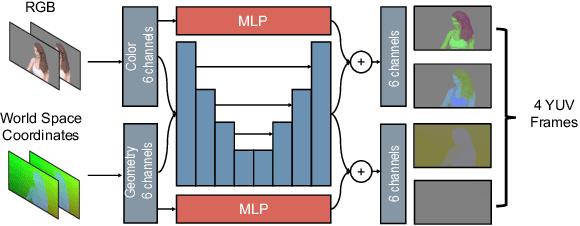
Stereoscopic video conferencing is still challenging due to the need to compress stereo RGB-D video in real-time. Though hardware implementations of standard video codecs such as H.264 / AVC and HEVC are widely available, they are not designed for stereoscopic videos and suffer from reduced quality and performance. Specific multiview or 3D extensions of these codecs are complex and lack efficient implementations. In this paper, we propose a new approach to upgrade a 2D video codec to support stereo RGB-D video compression, by wrapping it with a neural pre- and post-processor pair. The neural networks are end-to-end trained with an image codec proxy, and shown to work with a more sophisticated video codec. We also propose a geometry-aware loss function to improve rendering quality. We train the neural pre- and post-processors on a synthetic 4D people dataset, and evaluate it on both synthetic and real-captured stereo RGB-D videos. Experimental results show that the neural networks generalize well to unseen data and work out-of-box with various video codecs. Our approach saves about 30% bit-rate compared to a conventional video coding scheme and MV-HEVC at the same level of rendering quality from a novel view, without the need of a task-specific hardware upgrade.
Sandwiched Compression: Repurposing Standard Codecs with Neural Network Wrappers
Feb 08, 2024
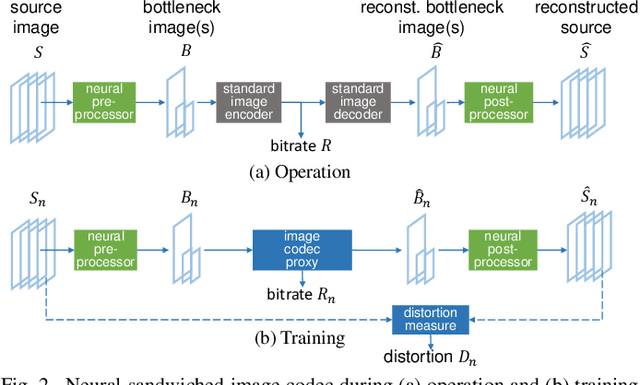
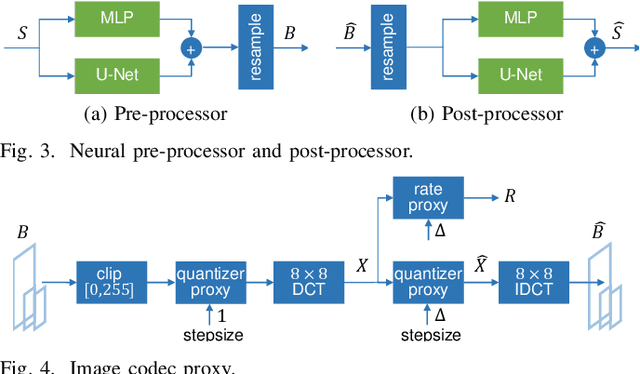
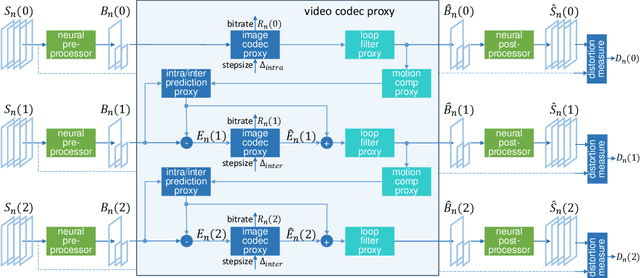
We propose sandwiching standard image and video codecs between pre- and post-processing neural networks. The networks are jointly trained through a differentiable codec proxy to minimize a given rate-distortion loss. This sandwich architecture not only improves the standard codec's performance on its intended content, it can effectively adapt the codec to other types of image/video content and to other distortion measures. Essentially, the sandwich learns to transmit ``neural code images'' that optimize overall rate-distortion performance even when the overall problem is well outside the scope of the codec's design. Through a variety of examples, we apply the sandwich architecture to sources with different numbers of channels, higher resolution, higher dynamic range, and perceptual distortion measures. The results demonstrate substantial improvements (up to 9 dB gains or up to 30\% bitrate reductions) compared to alternative adaptations. We derive VQ equivalents for the sandwich, establish optimality properties, and design differentiable codec proxies approximating current standard codecs. We further analyze model complexity, visual quality under perceptual metrics, as well as sandwich configurations that offer interesting potentials in image/video compression and streaming.
Sandwiched Video Compression: Efficiently Extending the Reach of Standard Codecs with Neural Wrappers
Mar 20, 2023
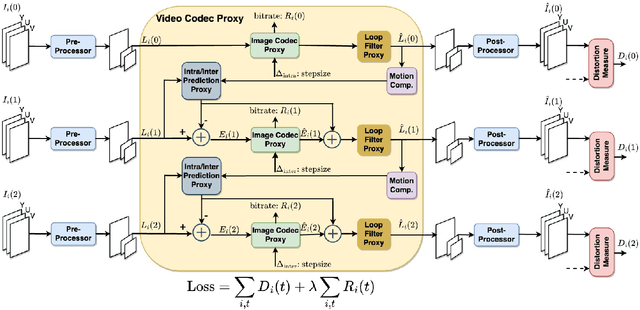

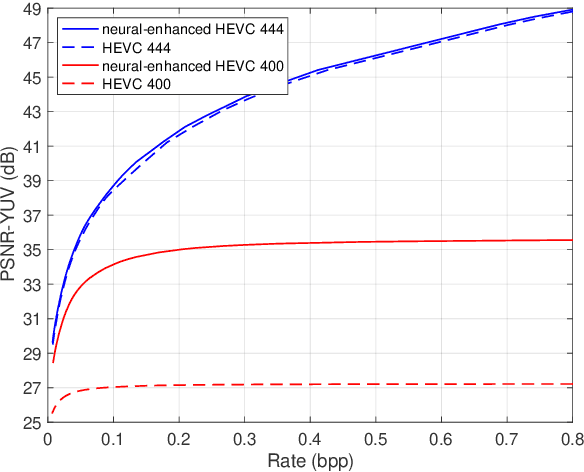
We propose sandwiched video compression -- a video compression system that wraps neural networks around a standard video codec. The sandwich framework consists of a neural pre- and post-processor with a standard video codec between them. The networks are trained jointly to optimize a rate-distortion loss function with the goal of significantly improving over the standard codec in various compression scenarios. End-to-end training in this setting requires a differentiable proxy for the standard video codec, which incorporates temporal processing with motion compensation, inter/intra mode decisions, and in-loop filtering. We propose differentiable approximations to key video codec components and demonstrate that the neural codes of the sandwich lead to significantly better rate-distortion performance compared to compressing the original frames of the input video in two important scenarios. When transporting high-resolution video via low-resolution HEVC, the sandwich system obtains 6.5 dB improvements over standard HEVC. More importantly, using the well-known perceptual similarity metric, LPIPS, we observe $~30 \%$ improvements in rate at the same quality over HEVC. Last but not least we show that pre- and post-processors formed by very modestly-parameterized, light-weight networks can closely approximate these results.
Deep Implicit Volume Compression
May 18, 2020

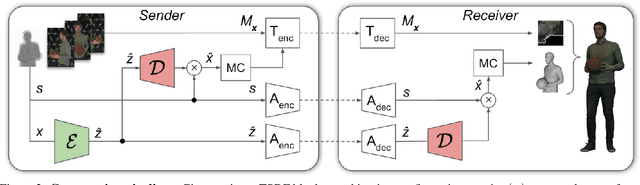
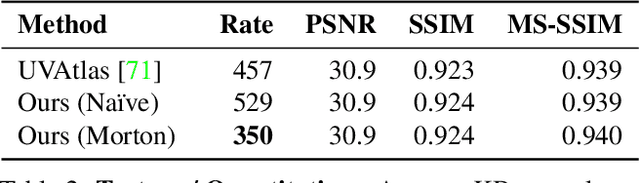
We describe a novel approach for compressing truncated signed distance fields (TSDF) stored in 3D voxel grids, and their corresponding textures. To compress the TSDF, our method relies on a block-based neural network architecture trained end-to-end, achieving state-of-the-art rate-distortion trade-off. To prevent topological errors, we losslessly compress the signs of the TSDF, which also upper bounds the reconstruction error by the voxel size. To compress the corresponding texture, we designed a fast block-based UV parameterization, generating coherent texture maps that can be effectively compressed using existing video compression algorithms. We demonstrate the performance of our algorithms on two 4D performance capture datasets, reducing bitrate by 66% for the same distortion, or alternatively reducing the distortion by 50% for the same bitrate, compared to the state-of-the-art.