 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Artifacts from Art History to Text-to-Image Generation
Jun 04, 2026Artistic styles are rooted in specific socio-historical contexts that encode social hierarchies, including distinct constructions of gender. Yet in AI research, style has long been treated as a surface-level visual property: a filter of color, brushstroke, and texture applied to otherwise content-neutral scenes. We introduce the first dataset to investigate the interplay between gender representation and style in both historical and generated images. StyleGender comprises 74k images spanning 19 artistic styles, comprising art historical images with style and gender annotations, T2I-generated images under controlled style and gender prompts, and a semantically aligned set enabling direct art history-to-generation comparison. By proposing two Set Gender Artifact (SGA) metrics (PixelSGA and MaskSGA), capturing gender signals at the pixel level and in compositional structure, we show that (1) gender representation shapes visual features across artistic styles, (2) style keywords carry these patterns into T2I generation, and (3) generative models tend to amplify gender artifacts beyond what is observed in historical sources.
Reconsidering Fairness Through Unawareness from the Perspective of Model Multiplicity
May 22, 2025



Fairness through Unawareness (FtU) describes the idea that discrimination against demographic groups can be avoided by not considering group membership in the decisions or predictions. This idea has long been criticized in the machine learning literature as not being sufficient to ensure fairness. In addition, the use of additional features is typically thought to increase the accuracy of the predictions for all groups, so that FtU is sometimes thought to be detrimental to all groups. In this paper, we show both theoretically and empirically that FtU can reduce algorithmic discrimination without necessarily reducing accuracy. We connect this insight with the literature on Model Multiplicity, to which we contribute with novel theoretical and empirical results. Furthermore, we illustrate how, in a real-life application, FtU can contribute to the deployment of more equitable policies without losing efficacy. Our findings suggest that FtU is worth considering in practical applications, particularly in high-risk scenarios, and that the use of protected attributes such as gender in predictive models should be accompanied by a clear and well-founded justification.
Five reasons against assuming a data-generating distribution in Machine Learning
Jul 24, 2024Machine Learning research, as most of Statistics, heavily relies on the concept of a data-generating probability distribution. As data points are thought to be sampled from such a distribution, we can learn from observed data about this distribution and, thus, predict future data points drawn from it (with some probability of success). Drawing on scholarship across disciplines, we here argue that this framework is not always a good model. Not only do such true probability distributions not exist; the framework can also be misleading and obscure both the choices made and the goals pursued in machine learning practice. We suggest an alternative framework that focuses on finite populations rather than abstract distributions; while classical learning theory can be left almost unchanged, it opens new opportunities, especially to model sampling. We compile these considerations into five reasons for modelling machine learning -- in some settings -- with finite distributions rather than generative distributions, both to be more faithful to practice and to provide novel theoretical insights.
Causal modelling without counterfactuals and individualised effects
Jul 24, 2024
The most common approach to causal modelling is the potential outcomes framework due to Neyman and Rubin. In this framework, outcomes of counterfactual treatments are assumed to be well-defined. This metaphysical assumption is often thought to be problematic yet indispensable. The conventional approach relies not only on counterfactuals, but also on abstract notions of distributions and assumptions of independence that are not directly testable. In this paper, we construe causal inference as treatment-wise predictions for finite populations where all assumptions are testable; this means that one can not only test predictions themselves (without any fundamental problem), but also investigate sources of error when they fail. The new framework highlights the model-dependence of causal claims as well as the difference between statistical and scientific inference.
On the Richness of Calibration
Feb 08, 2023
Probabilistic predictions can be evaluated through comparisons with observed label frequencies, that is, through the lens of calibration. Recent scholarship on algorithmic fairness has started to look at a growing variety of calibration-based objectives under the name of multi-calibration but has still remained fairly restricted. In this paper, we explore and analyse forms of evaluation through calibration by making explicit the choices involved in designing calibration scores. We organise these into three grouping choices and a choice concerning the agglomeration of group errors. This provides a framework for comparing previously proposed calibration scores and helps to formulate novel ones with desirable mathematical properties. In particular, we explore the possibility of grouping datapoints based on their input features rather than on predictions and formally demonstrate advantages of such approaches. We also characterise the space of suitable agglomeration functions for group errors, generalising previously proposed calibration scores. Complementary to such population-level scores, we explore calibration scores at the individual level and analyse their relationship to choices of grouping. We draw on these insights to introduce and axiomatise fairness deviation measures for population-level scores. We demonstrate that with appropriate choices of grouping, these novel global fairness scores can provide notions of (sub-)group or individual fairness.
Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
Jun 16, 2022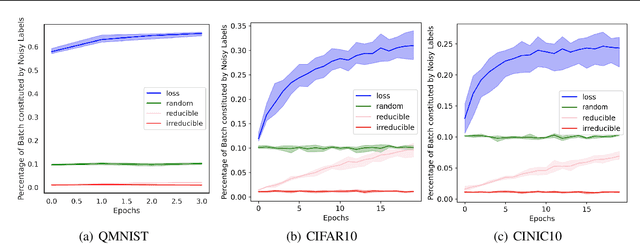
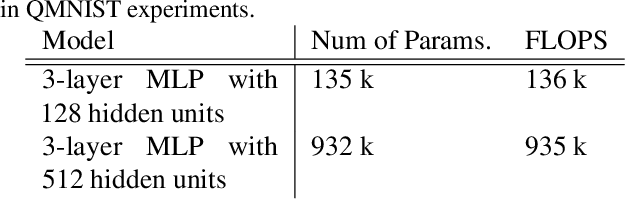
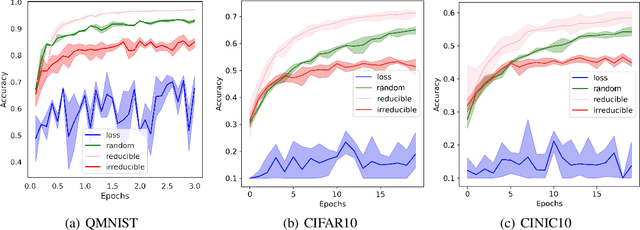
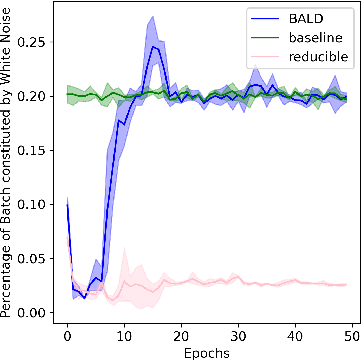
Training on web-scale data can take months. But most computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes 'easy' points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs, and BERT). On the large web-scraped image dataset Clothing-1M, RHO-LOSS trains in 18x fewer steps and reaches 2% higher final accuracy than uniform data shuffling.
DeDUCE: Generating Counterfactual Explanations Efficiently
Nov 29, 2021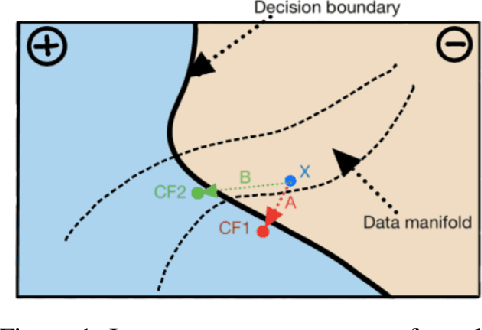

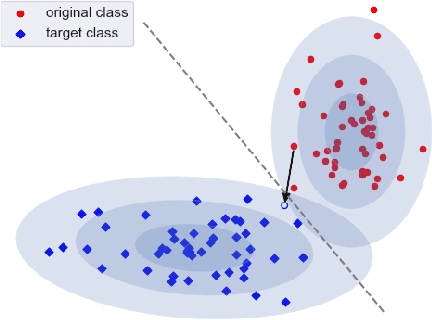

When an image classifier outputs a wrong class label, it can be helpful to see what changes in the image would lead to a correct classification. This is the aim of algorithms generating counterfactual explanations. However, there is no easily scalable method to generate such counterfactuals. We develop a new algorithm providing counterfactual explanations for large image classifiers trained with spectral normalisation at low computational cost. We empirically compare this algorithm against baselines from the literature; our novel algorithm consistently finds counterfactuals that are much closer to the original inputs. At the same time, the realism of these counterfactuals is comparable to the baselines. The code for all experiments is available at https://github.com/benedikthoeltgen/DeDUCE.
Encoding Causal Macrovariables
Nov 29, 2021



In many scientific disciplines, coarse-grained causal models are used to explain and predict the dynamics of more fine-grained systems. Naturally, such models require appropriate macrovariables. Automated procedures to detect suitable variables would be useful to leverage increasingly available high-dimensional observational datasets. This work introduces a novel algorithmic approach that is inspired by a new characterisation of causal macrovariables as information bottlenecks between microstates. Its general form can be adapted to address individual needs of different scientific goals. After a further transformation step, the causal relationships between learned variables can be investigated through additive noise models. Experiments on both simulated data and on a real climate dataset are reported. In a synthetic dataset, the algorithm robustly detects the ground-truth variables and correctly infers the causal relationships between them. In a real climate dataset, the algorithm robustly detects two variables that correspond to the two known variations of the El Nino phenomenon.