 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchored Preference Optimization and Contrastive Revisions: Addressing Underspecification in Alignment
Aug 12, 2024



Large Language Models (LLMs) are often aligned using contrastive alignment objectives and preference pair datasets. The interaction between model, paired data, and objective makes alignment a complicated procedure, sometimes producing subpar results. We study this and find that (i) preference data gives a better learning signal when the underlying responses are contrastive, and (ii) alignment objectives lead to better performance when they specify more control over the model during training. Based on these insights, we introduce Contrastive Learning from AI Revisions (CLAIR), a data-creation method which leads to more contrastive preference pairs, and Anchored Preference Optimization (APO), a controllable and more stable alignment objective. We align Llama-3-8B-Instruct using various comparable datasets and alignment objectives and measure MixEval-Hard scores, which correlate highly with human judgments. The CLAIR preferences lead to the strongest performance out of all datasets, and APO consistently outperforms less controllable objectives. Our best model, trained on 32K CLAIR preferences with APO, improves Llama-3-8B-Instruct by 7.65%, closing the gap with GPT4-turbo by 45%. Our code is available at https://github.com/ContextualAI/CLAIR_and_APO.
KTO: Model Alignment as Prospect Theoretic Optimization
Feb 02, 2024



Kahneman & Tversky's $\textit{prospect theory}$ tells us that humans perceive random variables in a biased but well-defined manner; for example, humans are famously loss-averse. We show that objectives for aligning LLMs with human feedback implicitly incorporate many of these biases -- the success of these objectives (e.g., DPO) over cross-entropy minimization can partly be ascribed to them being $\textit{human-aware loss functions}$ (HALOs). However, the utility functions these methods attribute to humans still differ from those in the prospect theory literature. Using a Kahneman-Tversky model of human utility, we propose a HALO that directly maximizes the utility of generations instead of maximizing the log-likelihood of preferences, as current methods do. We call this approach Kahneman-Tversky Optimization (KTO), and it matches or exceeds the performance of preference-based methods at scales from 1B to 30B. Crucially, KTO does not need preferences -- only a binary signal of whether an output is desirable or undesirable for a given input. This makes it far easier to use in the real world, where preference data is scarce and expensive.
Neural Functional Transformers
May 22, 2023
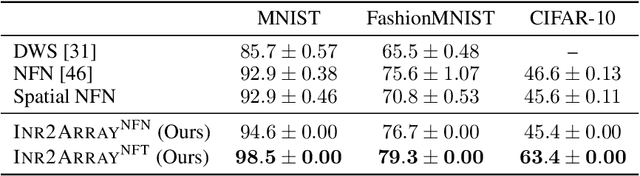
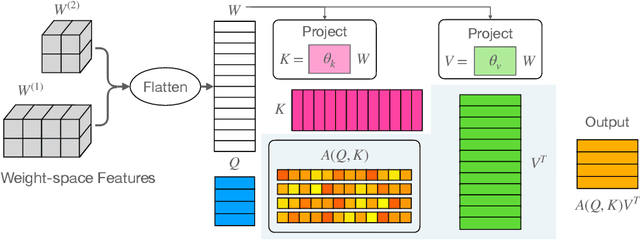

The recent success of neural networks as implicit representation of data has driven growing interest in neural functionals: models that can process other neural networks as input by operating directly over their weight spaces. Nevertheless, constructing expressive and efficient neural functional architectures that can handle high-dimensional weight-space objects remains challenging. This paper uses the attention mechanism to define a novel set of permutation equivariant weight-space layers and composes them into deep equivariant models called neural functional Transformers (NFTs). NFTs respect weight-space permutation symmetries while incorporating the advantages of attention, which have exhibited remarkable success across multiple domains. In experiments processing the weights of feedforward MLPs and CNNs, we find that NFTs match or exceed the performance of prior weight-space methods. We also leverage NFTs to develop Inr2Array, a novel method for computing permutation invariant latent representations from the weights of implicit neural representations (INRs). Our proposed method improves INR classification accuracy by up to $+17\%$ over existing methods. We provide an implementation of our layers at https://github.com/AllanYangZhou/nfn.
Deep Latent State Space Models for Time-Series Generation
Dec 24, 2022Methods based on ordinary differential equations (ODEs) are widely used to build generative models of time-series. In addition to high computational overhead due to explicitly computing hidden states recurrence, existing ODE-based models fall short in learning sequence data with sharp transitions - common in many real-world systems - due to numerical challenges during optimization. In this work, we propose LS4, a generative model for sequences with latent variables evolving according to a state space ODE to increase modeling capacity. Inspired by recent deep state space models (S4), we achieve speedups by leveraging a convolutional representation of LS4 which bypasses the explicit evaluation of hidden states. We show that LS4 significantly outperforms previous continuous-time generative models in terms of marginal distribution, classification, and prediction scores on real-world datasets in the Monash Forecasting Repository, and is capable of modeling highly stochastic data with sharp temporal transitions. LS4 sets state-of-the-art for continuous-time latent generative models, with significant improvement of mean squared error and tighter variational lower bounds on irregularly-sampled datasets, while also being x100 faster than other baselines on long sequences.
Language Model Cascades
Jul 28, 2022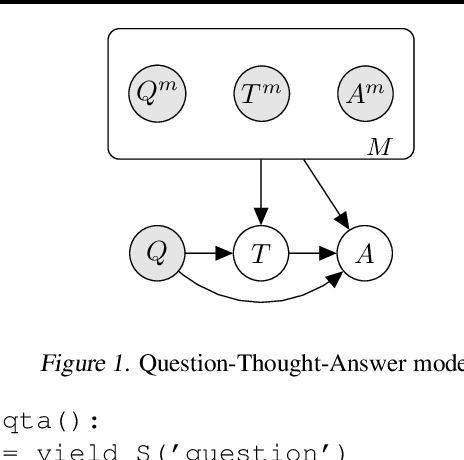
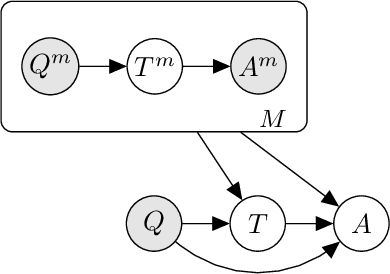
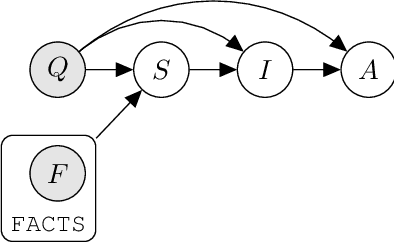
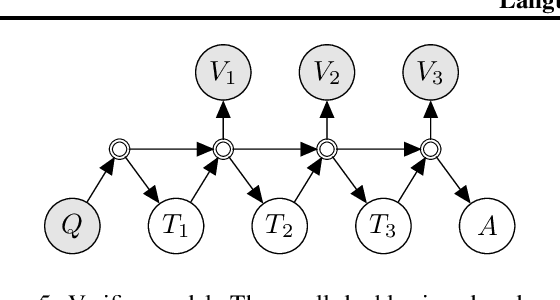
Prompted models have demonstrated impressive few-shot learning abilities. Repeated interactions at test-time with a single model, or the composition of multiple models together, further expands capabilities. These compositions are probabilistic models, and may be expressed in the language of graphical models with random variables whose values are complex data types such as strings. Cases with control flow and dynamic structure require techniques from probabilistic programming, which allow implementing disparate model structures and inference strategies in a unified language. We formalize several existing techniques from this perspective, including scratchpads / chain of thought, verifiers, STaR, selection-inference, and tool use. We refer to the resulting programs as language model cascades.
Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
Jun 16, 2022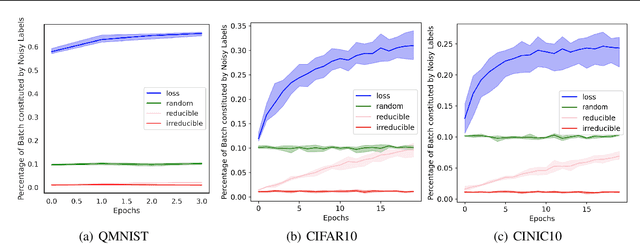
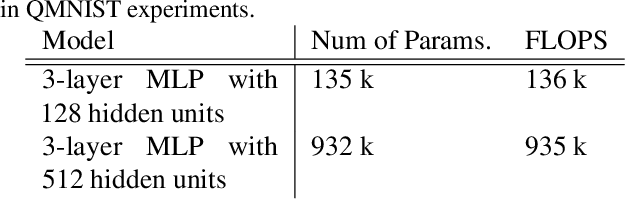
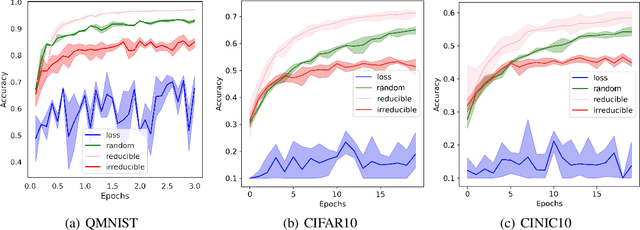
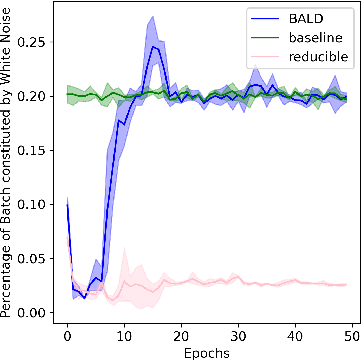
Training on web-scale data can take months. But most computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes 'easy' points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs, and BERT). On the large web-scraped image dataset Clothing-1M, RHO-LOSS trains in 18x fewer steps and reaches 2% higher final accuracy than uniform data shuffling.
Multi-Game Decision Transformers
May 30, 2022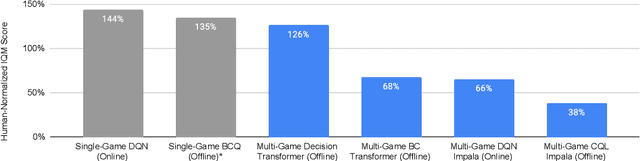

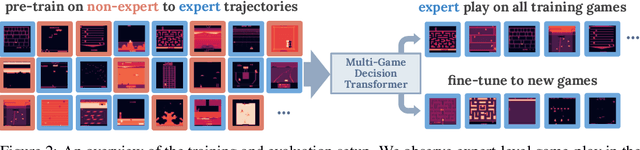
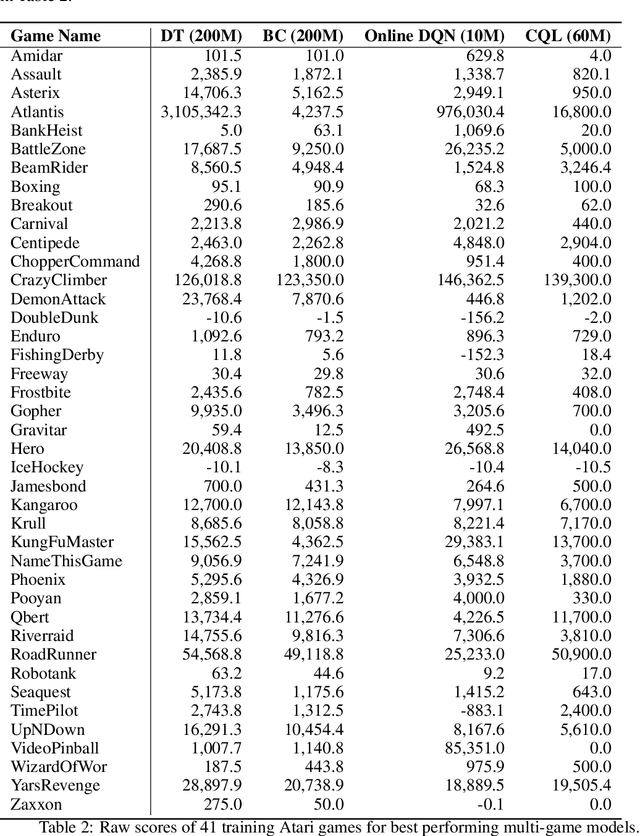
A longstanding goal of the field of AI is a strategy for compiling diverse experience into a highly capable, generalist agent. In the subfields of vision and language, this was largely achieved by scaling up transformer-based models and training them on large, diverse datasets. Motivated by this progress, we investigate whether the same strategy can be used to produce generalist reinforcement learning agents. Specifically, we show that a single transformer-based model - with a single set of weights - trained purely offline can play a suite of up to 46 Atari games simultaneously at close-to-human performance. When trained and evaluated appropriately, we find that the same trends observed in language and vision hold, including scaling of performance with model size and rapid adaptation to new games via fine-tuning. We compare several approaches in this multi-game setting, such as online and offline RL methods and behavioral cloning, and find that our Multi-Game Decision Transformer models offer the best scalability and performance. We release the pre-trained models and code to encourage further research in this direction. Additional information, videos and code can be seen at: sites.google.com/view/multi-game-transformers
Self-Similarity Priors: Neural Collages as Differentiable Fractal Representations
Apr 15, 2022Many patterns in nature exhibit self-similarity: they can be compactly described via self-referential transformations. Said patterns commonly appear in natural and artificial objects, such as molecules, shorelines, galaxies and even images. In this work, we investigate the role of learning in the automated discovery of self-similarity and in its utilization for downstream tasks. To this end, we design a novel class of implicit operators, Neural Collages, which (1) represent data as the parameters of a self-referential, structured transformation, and (2) employ hypernetworks to amortize the cost of finding these parameters to a single forward pass. We investigate how to leverage the representations produced by Neural Collages in various tasks, including data compression and generation. Neural Collages image compressors are orders of magnitude faster than other self-similarity-based algorithms during encoding and offer compression rates competitive with implicit methods. Finally, we showcase applications of Neural Collages for fractal art and as deep generative models.
NoisyMix: Boosting Robustness by Combining Data Augmentations, Stability Training, and Noise Injections
Feb 02, 2022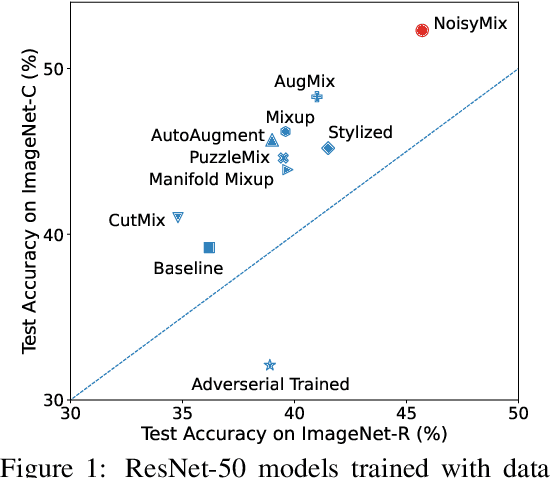
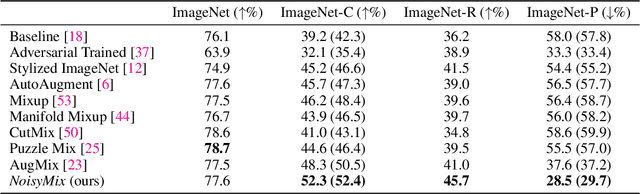
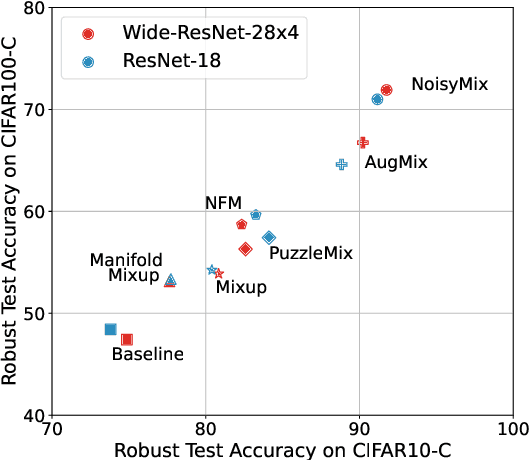
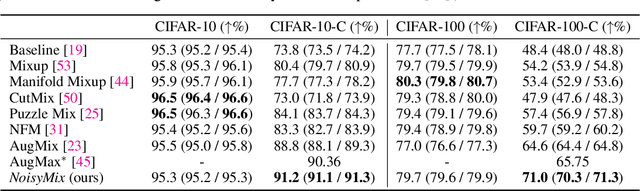
For many real-world applications, obtaining stable and robust statistical performance is more important than simply achieving state-of-the-art predictive test accuracy, and thus robustness of neural networks is an increasingly important topic. Relatedly, data augmentation schemes have been shown to improve robustness with respect to input perturbations and domain shifts. Motivated by this, we introduce NoisyMix, a training scheme that combines data augmentations with stability training and noise injections to improve both model robustness and in-domain accuracy. This combination promotes models that are consistently more robust and that provide well-calibrated estimates of class membership probabilities. We demonstrate the benefits of NoisyMix on a range of benchmark datasets, including ImageNet-C, ImageNet-R, and ImageNet-P. Moreover, we provide theory to understand implicit regularization and robustness of NoisyMix.
Noisy Feature Mixup
Oct 05, 2021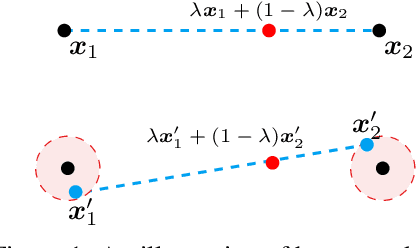
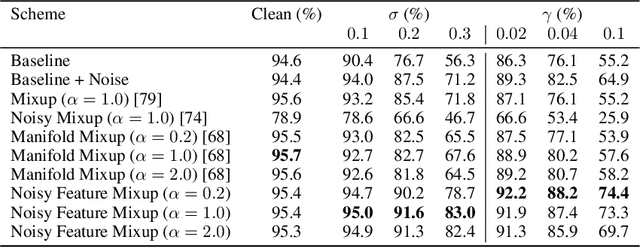
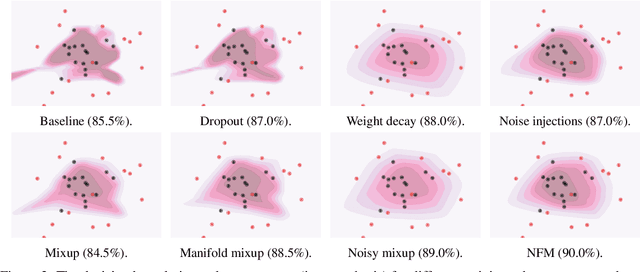
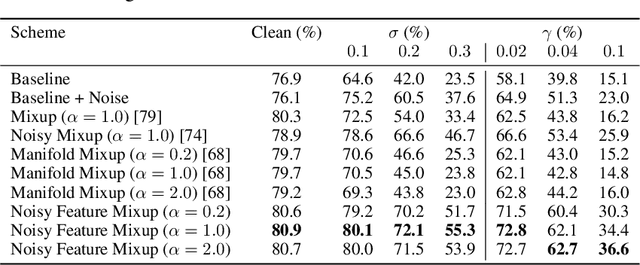
We introduce Noisy Feature Mixup (NFM), an inexpensive yet effective method for data augmentation that combines the best of interpolation based training and noise injection schemes. Rather than training with convex combinations of pairs of examples and their labels, we use noise-perturbed convex combinations of pairs of data points in both input and feature space. This method includes mixup and manifold mixup as special cases, but it has additional advantages, including better smoothing of decision boundaries and enabling improved model robustness. We provide theory to understand this as well as the implicit regularization effects of NFM. Our theory is supported by empirical results, demonstrating the advantage of NFM, as compared to mixup and manifold mixup. We show that residual networks and vision transformers trained with NFM have favorable trade-offs between predictive accuracy on clean data and robustness with respect to various types of data perturbation across a range of computer vision benchmark datasets.