 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisyMix: Boosting Robustness by Combining Data Augmentations, Stability Training, and Noise Injections
Feb 02, 2022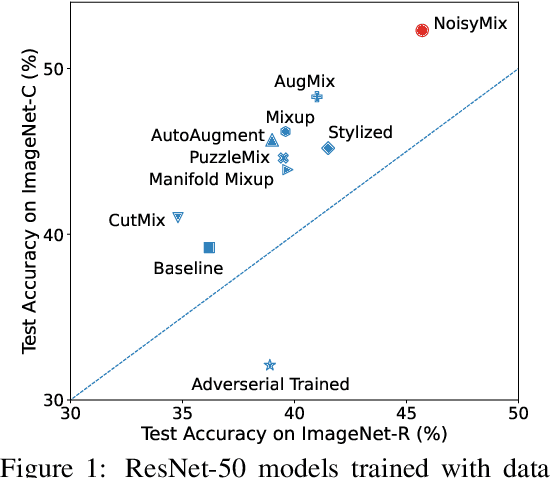
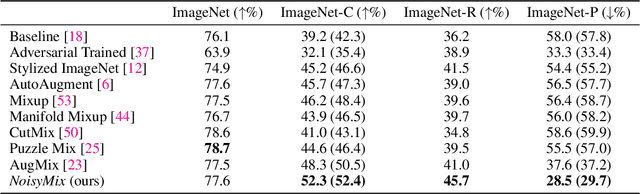
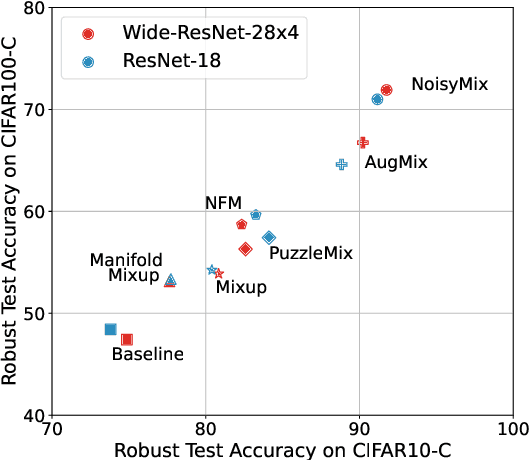
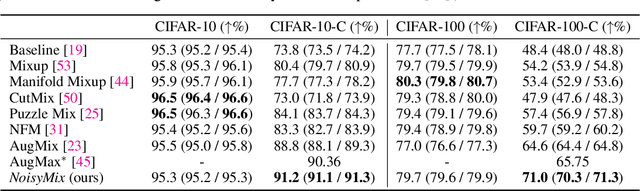
For many real-world applications, obtaining stable and robust statistical performance is more important than simply achieving state-of-the-art predictive test accuracy, and thus robustness of neural networks is an increasingly important topic. Relatedly, data augmentation schemes have been shown to improve robustness with respect to input perturbations and domain shifts. Motivated by this, we introduce NoisyMix, a training scheme that combines data augmentations with stability training and noise injections to improve both model robustness and in-domain accuracy. This combination promotes models that are consistently more robust and that provide well-calibrated estimates of class membership probabilities. We demonstrate the benefits of NoisyMix on a range of benchmark datasets, including ImageNet-C, ImageNet-R, and ImageNet-P. Moreover, we provide theory to understand implicit regularization and robustness of NoisyMix.
Noisy Feature Mixup
Oct 05, 2021
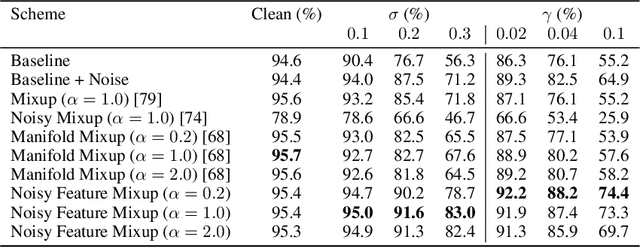
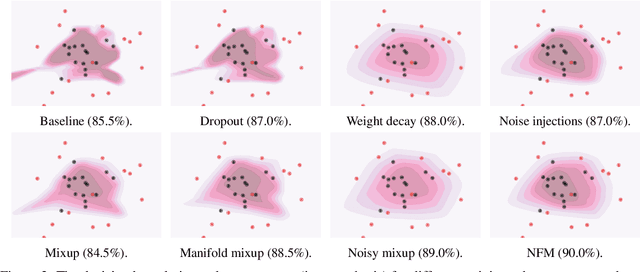
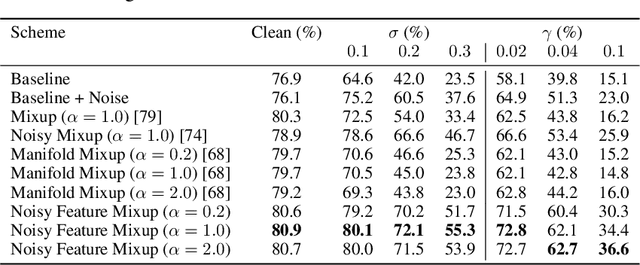
We introduce Noisy Feature Mixup (NFM), an inexpensive yet effective method for data augmentation that combines the best of interpolation based training and noise injection schemes. Rather than training with convex combinations of pairs of examples and their labels, we use noise-perturbed convex combinations of pairs of data points in both input and feature space. This method includes mixup and manifold mixup as special cases, but it has additional advantages, including better smoothing of decision boundaries and enabling improved model robustness. We provide theory to understand this as well as the implicit regularization effects of NFM. Our theory is supported by empirical results, demonstrating the advantage of NFM, as compared to mixup and manifold mixup. We show that residual networks and vision transformers trained with NFM have favorable trade-offs between predictive accuracy on clean data and robustness with respect to various types of data perturbation across a range of computer vision benchmark datasets.
Adversarially-Trained Deep Nets Transfer Better
Jul 11, 2020

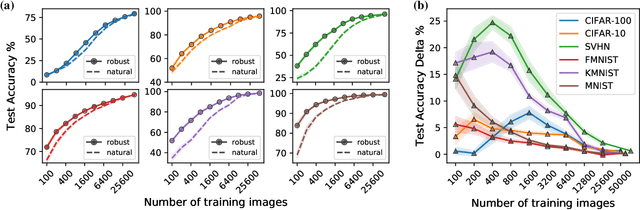
Transfer learning has emerged as a powerful methodology for adapting pre-trained deep neural networks to new domains. This process consists of taking a neural network pre-trained on a large feature-rich source dataset, freezing the early layers that encode essential generic image properties, and then fine-tuning the last few layers in order to capture specific information related to the target situation. This approach is particularly useful when only limited or weakly labelled data are available for the new task. In this work, we demonstrate that adversarially-trained models transfer better across new domains than naturally-trained models, even though it's known that these models do not generalize as well as naturally-trained models on the source domain. We show that this behavior results from a bias, introduced by the adversarial training, that pushes the learned inner layers to more natural image representations, which in turn enables better transfer.