 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Interpretable Counterfactual Explanations By Implicit Minimisation of Epistemic and Aleatoric Uncertainties
Mar 16, 2021
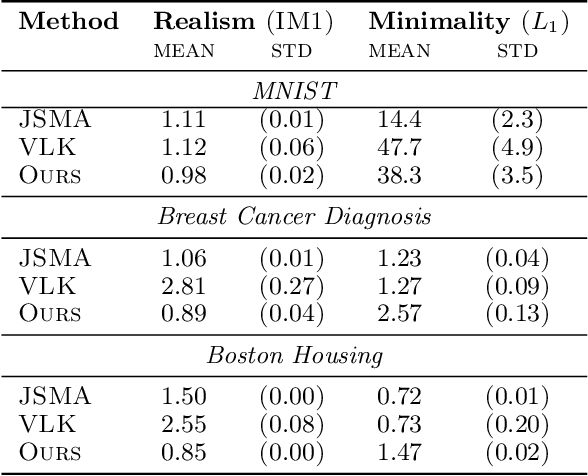


Counterfactual explanations (CEs) are a practical tool for demonstrating why machine learning classifiers make particular decisions. For CEs to be useful, it is important that they are easy for users to interpret. Existing methods for generating interpretable CEs rely on auxiliary generative models, which may not be suitable for complex datasets, and incur engineering overhead. We introduce a simple and fast method for generating interpretable CEs in a white-box setting without an auxiliary model, by using the predictive uncertainty of the classifier. Our experiments show that our proposed algorithm generates more interpretable CEs, according to IM1 scores, than existing methods. Additionally, our approach allows us to estimate the uncertainty of a CE, which may be important in safety-critical applications, such as those in the medical domain.
* 21 pages, 13 Figures