 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelating Variational Autoencoders Natively For Multi-View Imputation
Nov 05, 2024
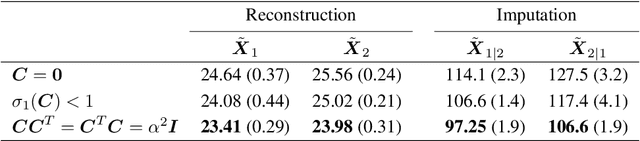
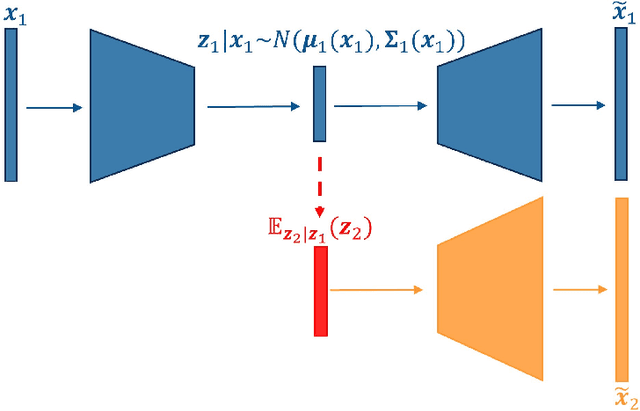
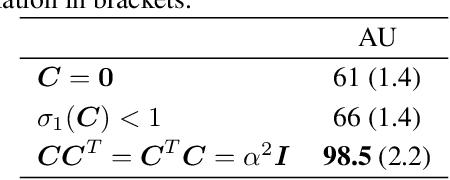
Multi-view data from the same source often exhibit correlation. This is mirrored in correlation between the latent spaces of separate variational autoencoders (VAEs) trained on each data-view. A multi-view VAE approach is proposed that incorporates a joint prior with a non-zero correlation structure between the latent spaces of the VAEs. By enforcing such correlation structure, more strongly correlated latent spaces are uncovered. Using conditional distributions to move between these latent spaces, missing views can be imputed and used for downstream analysis. Learning this correlation structure involves maintaining validity of the prior distribution, as well as a successful parameterization that allows end-to-end learning.
Bridging the Human-AI Knowledge Gap: Concept Discovery and Transfer in AlphaZero
Oct 25, 2023Artificial Intelligence (AI) systems have made remarkable progress, attaining super-human performance across various domains. This presents us with an opportunity to further human knowledge and improve human expert performance by leveraging the hidden knowledge encoded within these highly performant AI systems. Yet, this knowledge is often hard to extract, and may be hard to understand or learn from. Here, we show that this is possible by proposing a new method that allows us to extract new chess concepts in AlphaZero, an AI system that mastered the game of chess via self-play without human supervision. Our analysis indicates that AlphaZero may encode knowledge that extends beyond the existing human knowledge, but knowledge that is ultimately not beyond human grasp, and can be successfully learned from. In a human study, we show that these concepts are learnable by top human experts, as four top chess grandmasters show improvements in solving the presented concept prototype positions. This marks an important first milestone in advancing the frontier of human knowledge by leveraging AI; a development that could bear profound implications and help us shape how we interact with AI systems across many AI applications.
Role of Human-AI Interaction in Selective Prediction
Dec 13, 2021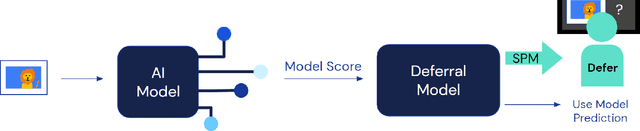
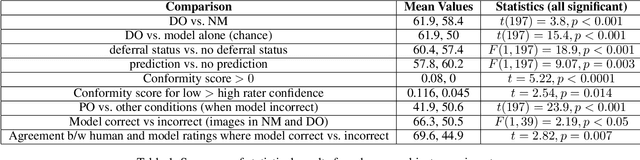

Recent work has shown the potential benefit of selective prediction systems that can learn to defer to a human when the predictions of the AI are unreliable, particularly to improve the reliability of AI systems in high-stakes applications like healthcare or conservation. However, most prior work assumes that human behavior remains unchanged when they solve a prediction task as part of a human-AI team as opposed to by themselves. We show that this is not the case by performing experiments to quantify human-AI interaction in the context of selective prediction. In particular, we study the impact of communicating different types of information to humans about the AI system's decision to defer. Using real-world conservation data and a selective prediction system that improves expected accuracy over that of the human or AI system working individually, we show that this messaging has a significant impact on the accuracy of human judgements. Our results study two components of the messaging strategy: 1) Whether humans are informed about the prediction of the AI system and 2) Whether they are informed about the decision of the selective prediction system to defer. By manipulating these messaging components, we show that it is possible to significantly boost human performance by informing the human of the decision to defer, but not revealing the prediction of the AI. We therefore show that it is vital to consider how the decision to defer is communicated to a human when designing selective prediction systems, and that the composite accuracy of a human-AI team must be carefully evaluated using a human-in-the-loop framework.
Acquisition of Chess Knowledge in AlphaZero
Nov 27, 2021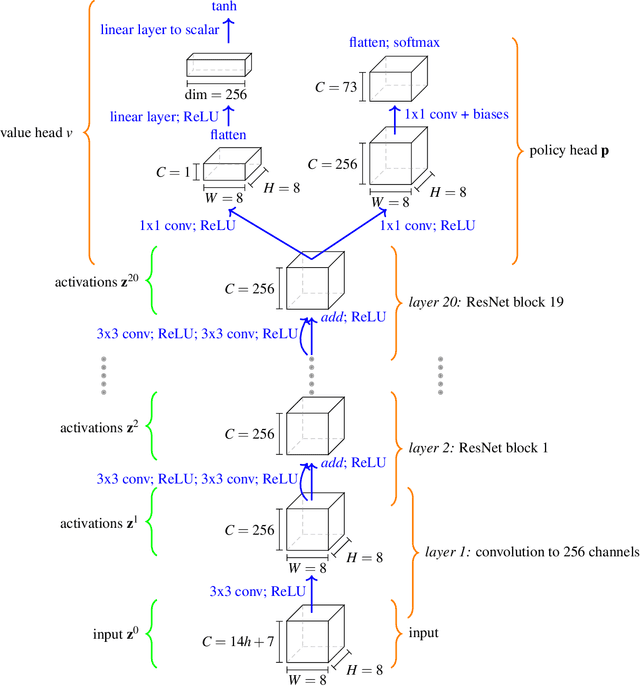

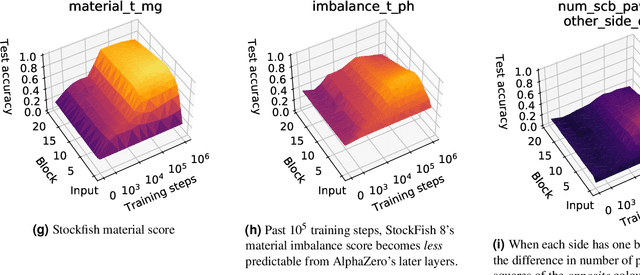
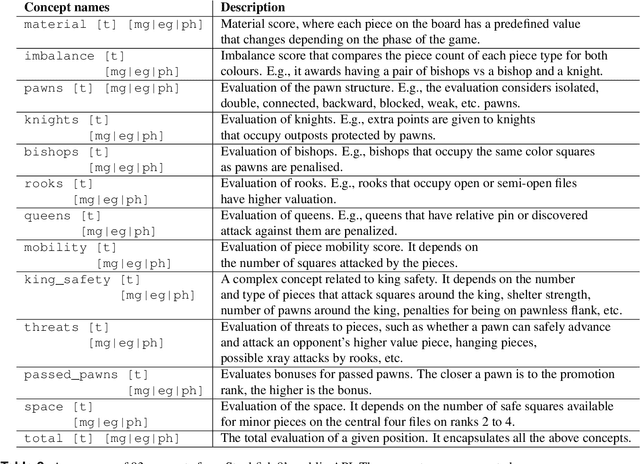
What is learned by sophisticated neural network agents such as AlphaZero? This question is of both scientific and practical interest. If the representations of strong neural networks bear no resemblance to human concepts, our ability to understand faithful explanations of their decisions will be restricted, ultimately limiting what we can achieve with neural network interpretability. In this work we provide evidence that human knowledge is acquired by the AlphaZero neural network as it trains on the game of chess. By probing for a broad range of human chess concepts we show when and where these concepts are represented in the AlphaZero network. We also provide a behavioural analysis focusing on opening play, including qualitative analysis from chess Grandmaster Vladimir Kramnik. Finally, we carry out a preliminary investigation looking at the low-level details of AlphaZero's representations, and make the resulting behavioural and representational analyses available online.
Assessing Game Balance with AlphaZero: Exploring Alternative Rule Sets in Chess
Sep 15, 2020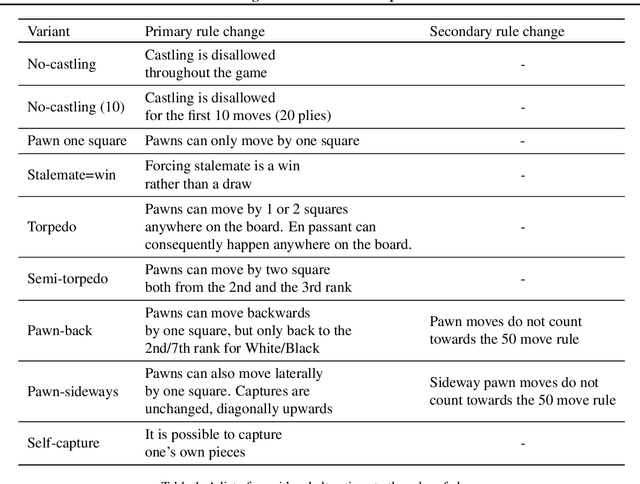


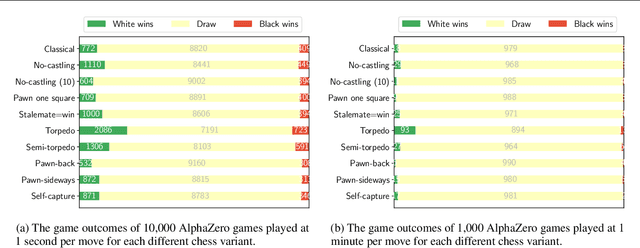
It is non-trivial to design engaging and balanced sets of game rules. Modern chess has evolved over centuries, but without a similar recourse to history, the consequences of rule changes to game dynamics are difficult to predict. AlphaZero provides an alternative in silico means of game balance assessment. It is a system that can learn near-optimal strategies for any rule set from scratch, without any human supervision, by continually learning from its own experience. In this study we use AlphaZero to creatively explore and design new chess variants. There is growing interest in chess variants like Fischer Random Chess, because of classical chess's voluminous opening theory, the high percentage of draws in professional play, and the non-negligible number of games that end while both players are still in their home preparation. We compare nine other variants that involve atomic changes to the rules of chess. The changes allow for novel strategic and tactical patterns to emerge, while keeping the games close to the original. By learning near-optimal strategies for each variant with AlphaZero, we determine what games between strong human players might look like if these variants were adopted. Qualitatively, several variants are very dynamic. An analytic comparison show that pieces are valued differently between variants, and that some variants are more decisive than classical chess. Our findings demonstrate the rich possibilities that lie beyond the rules of modern chess.
Unsupervised Separation of Dynamics from Pixels
Jul 20, 2019
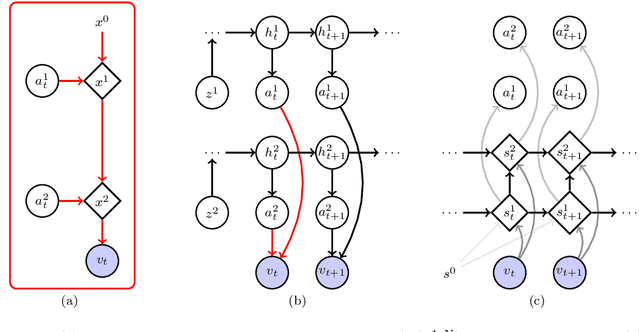
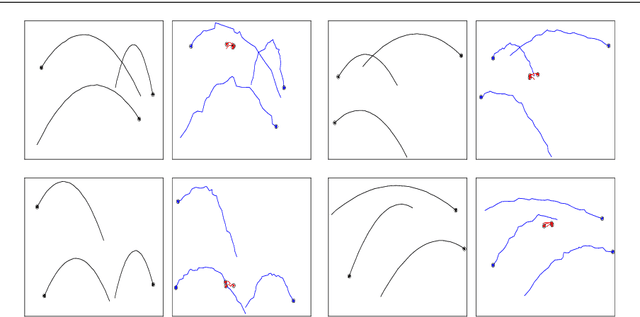
We present an approach to learn the dynamics of multiple objects from image sequences in an unsupervised way. We introduce a probabilistic model that first generate noisy positions for each object through a separate linear state-space model, and then renders the positions of all objects in the same image through a highly non-linear process. Such a linear representation of the dynamics enables us to propose an inference method that uses exact and efficient inference tools and that can be deployed to query the model in different ways without retraining.
A Factorial Mixture Prior for Compositional Deep Generative Models
Dec 18, 2018

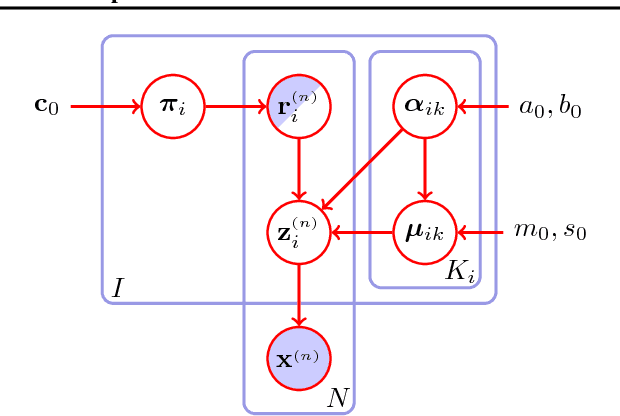
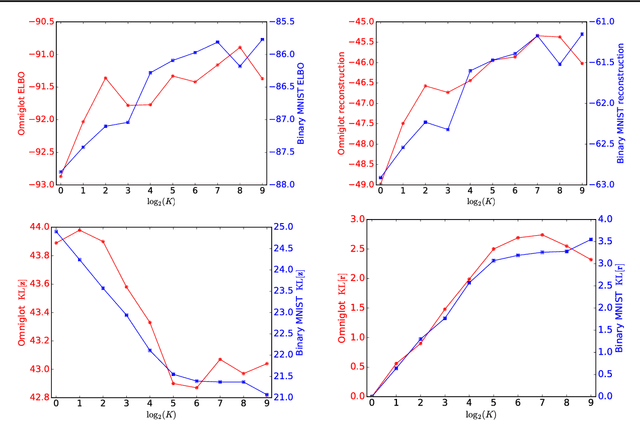
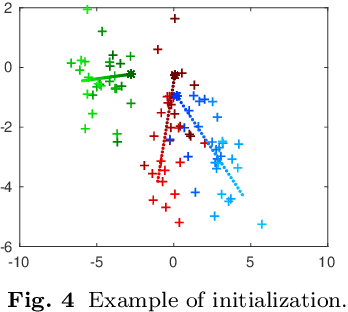
We assume that a high-dimensional datum, like an image, is a compositional expression of a set of properties, with a complicated non-linear relationship between the datum and its properties. This paper proposes a factorial mixture prior for capturing latent properties, thereby adding structured compositionality to deep generative models. The prior treats a latent vector as belonging to Cartesian product of subspaces, each of which is quantized separately with a Gaussian mixture model. Some mixture components can be set to represent properties as observed random variables whenever labeled properties are present. Through a combination of stochastic variational inference and gradient descent, a method for learning how to infer discrete properties in an unsupervised or semi-supervised way is outlined and empirically evaluated.
An Efficient Implementation of Riemannian Manifold Hamiltonian Monte Carlo for Gaussian Process Models
Oct 28, 2018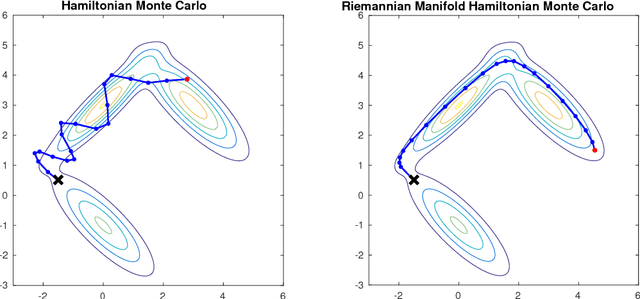
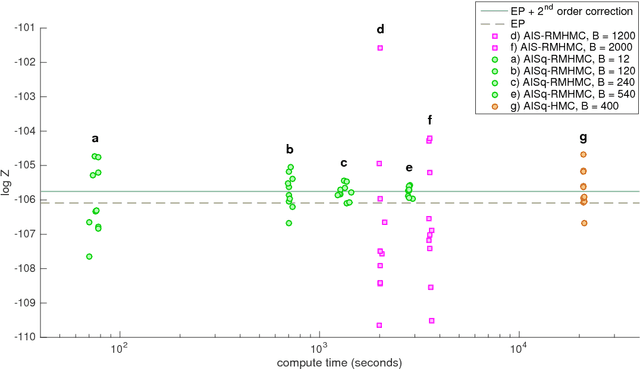
This technical report presents pseudo-code for a Riemannian manifold Hamiltonian Monte Carlo (RMHMC) method to efficiently simulate samples from $N$-dimensional posterior distributions $p(x|y)$, where $x \in R^N$ is drawn from a Gaussian Process (GP) prior, and observations $y_n$ are independent given $x_n$. Sufficient technical and algorithmic details are provided for the implementation of RMHMC for distributions arising from GP priors.
Recurrent Relational Networks
Oct 16, 2018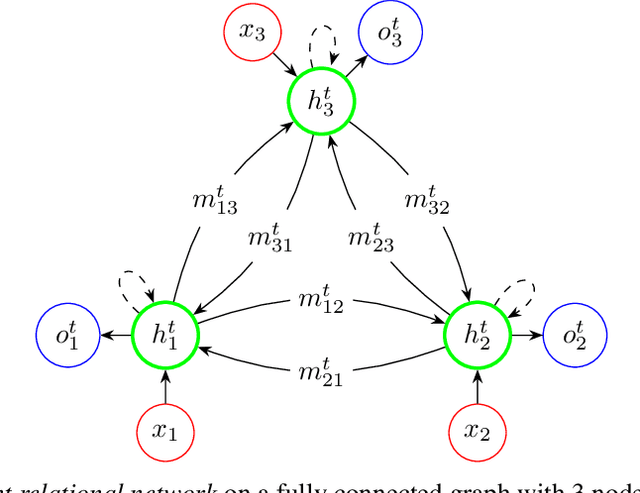
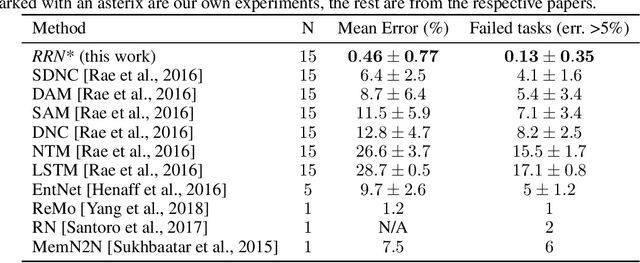
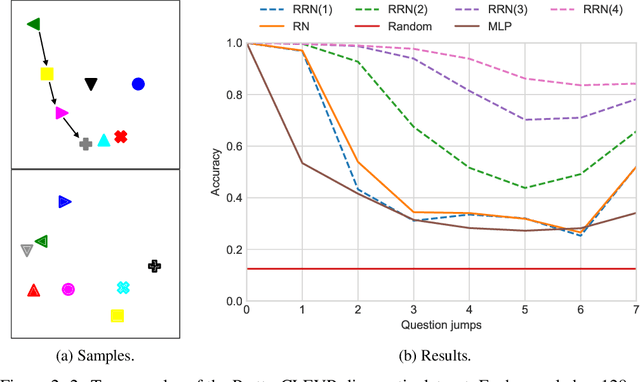

This paper is concerned with learning to solve tasks that require a chain of interdependent steps of relational inference, like answering complex questions about the relationships between objects, or solving puzzles where the smaller elements of a solution mutually constrain each other. We introduce the recurrent relational network, a general purpose module that operates on a graph representation of objects. As a generalization of Santoro et al. [2017]'s relational network, it can augment any neural network model with the capacity to do many-step relational reasoning. We achieve state of the art results on the bAbI textual question-answering dataset with the recurrent relational network, consistently solving 20/20 tasks. As bAbI is not particularly challenging from a relational reasoning point of view, we introduce Pretty-CLEVR, a new diagnostic dataset for relational reasoning. In the Pretty-CLEVR set-up, we can vary the question to control for the number of relational reasoning steps that are required to obtain the answer. Using Pretty-CLEVR, we probe the limitations of multi-layer perceptrons, relational and recurrent relational networks. Finally, we show how recurrent relational networks can learn to solve Sudoku puzzles from supervised training data, a challenging task requiring upwards of 64 steps of relational reasoning. We achieve state-of-the-art results amongst comparable methods by solving 96.6% of the hardest Sudoku puzzles.
A Disentangled Recognition and Nonlinear Dynamics Model for Unsupervised Learning
Oct 30, 2017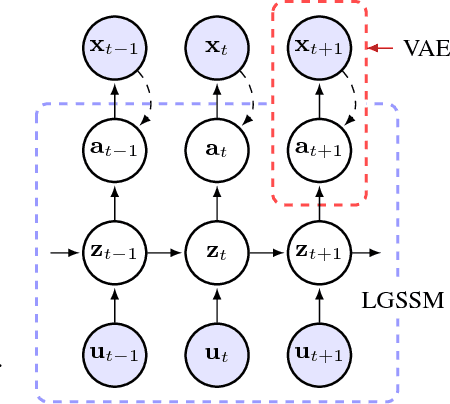
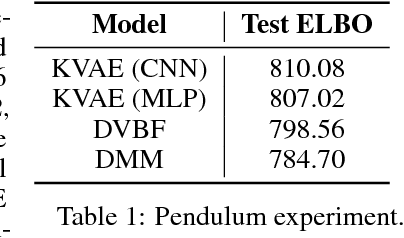
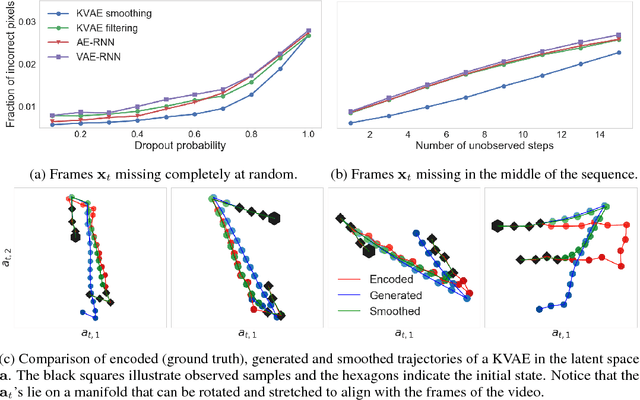
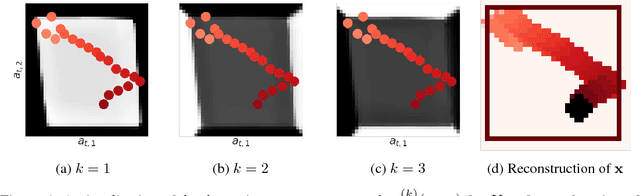
This paper takes a step towards temporal reasoning in a dynamically changing video, not in the pixel space that constitutes its frames, but in a latent space that describes the non-linear dynamics of the objects in its world. We introduce the Kalman variational auto-encoder, a framework for unsupervised learning of sequential data that disentangles two latent representations: an object's representation, coming from a recognition model, and a latent state describing its dynamics. As a result, the evolution of the world can be imagined and missing data imputed, both without the need to generate high dimensional frames at each time step. The model is trained end-to-end on videos of a variety of simulated physical systems, and outperforms competing methods in generative and missing data imputation tasks.