 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
General-purpose, long-context autoregressive modeling with Perceiver AR
Feb 15, 2022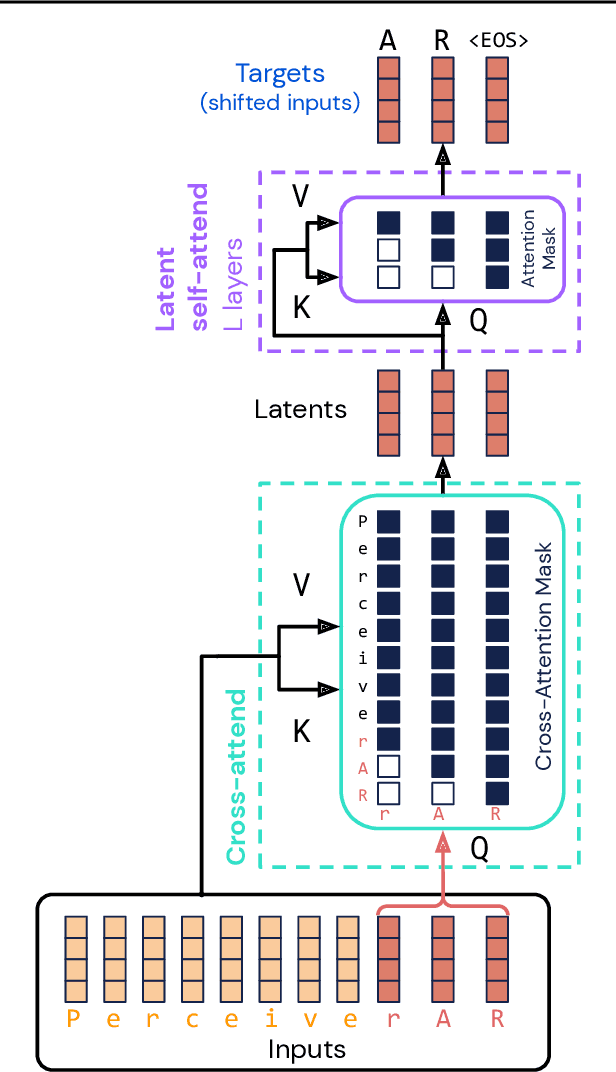
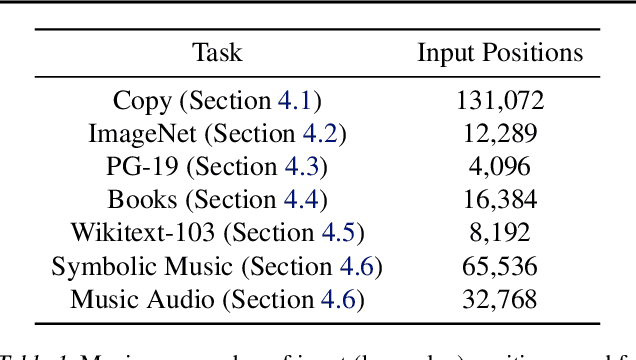
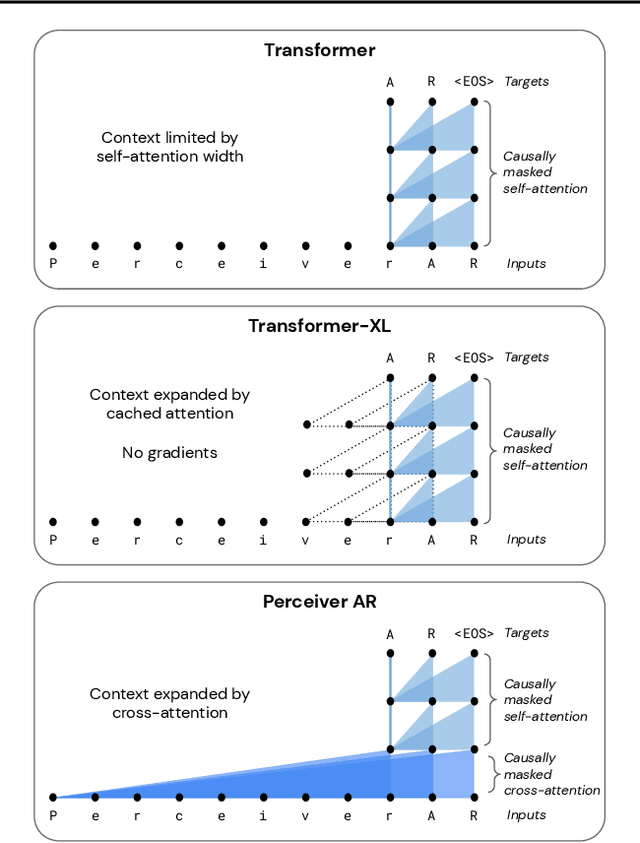
Real-world data is high-dimensional: a book, image, or musical performance can easily contain hundreds of thousands of elements even after compression. However, the most commonly used autoregressive models, Transformers, are prohibitively expensive to scale to the number of inputs and layers needed to capture this long-range structure. We develop Perceiver AR, an autoregressive, modality-agnostic architecture which uses cross-attention to map long-range inputs to a small number of latents while also maintaining end-to-end causal masking. Perceiver AR can directly attend to over a hundred thousand tokens, enabling practical long-context density estimation without the need for hand-crafted sparsity patterns or memory mechanisms. When trained on images or music, Perceiver AR generates outputs with clear long-term coherence and structure. Our architecture also obtains state-of-the-art likelihood on long-sequence benchmarks, including 64 x 64 ImageNet images and PG-19 books.
Role of Human-AI Interaction in Selective Prediction
Dec 13, 2021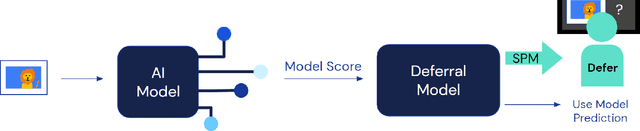
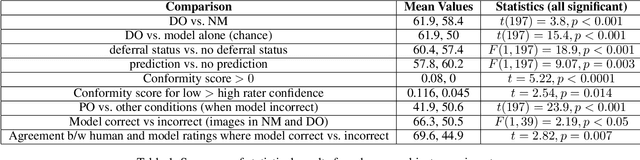

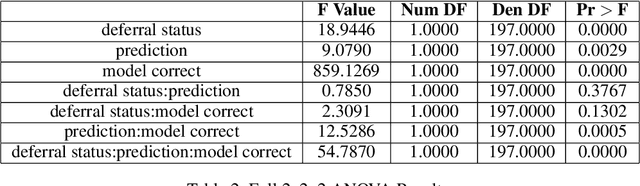
Recent work has shown the potential benefit of selective prediction systems that can learn to defer to a human when the predictions of the AI are unreliable, particularly to improve the reliability of AI systems in high-stakes applications like healthcare or conservation. However, most prior work assumes that human behavior remains unchanged when they solve a prediction task as part of a human-AI team as opposed to by themselves. We show that this is not the case by performing experiments to quantify human-AI interaction in the context of selective prediction. In particular, we study the impact of communicating different types of information to humans about the AI system's decision to defer. Using real-world conservation data and a selective prediction system that improves expected accuracy over that of the human or AI system working individually, we show that this messaging has a significant impact on the accuracy of human judgements. Our results study two components of the messaging strategy: 1) Whether humans are informed about the prediction of the AI system and 2) Whether they are informed about the decision of the selective prediction system to defer. By manipulating these messaging components, we show that it is possible to significantly boost human performance by informing the human of the decision to defer, but not revealing the prediction of the AI. We therefore show that it is vital to consider how the decision to defer is communicated to a human when designing selective prediction systems, and that the composite accuracy of a human-AI team must be carefully evaluated using a human-in-the-loop framework.