 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous diffusion for categorical data
Dec 15, 2022



Diffusion models have quickly become the go-to paradigm for generative modelling of perceptual signals (such as images and sound) through iterative refinement. Their success hinges on the fact that the underlying physical phenomena are continuous. For inherently discrete and categorical data such as language, various diffusion-inspired alternatives have been proposed. However, the continuous nature of diffusion models conveys many benefits, and in this work we endeavour to preserve it. We propose CDCD, a framework for modelling categorical data with diffusion models that are continuous both in time and input space. We demonstrate its efficacy on several language modelling tasks.
The Chamber Ensemble Generator: Limitless High-Quality MIR Data via Generative Modeling
Sep 28, 2022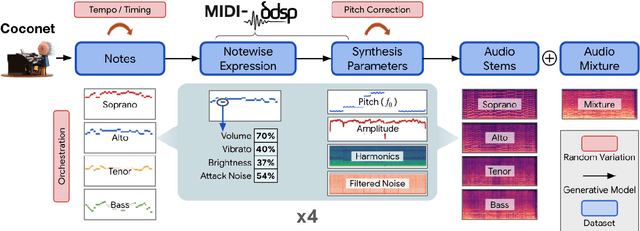
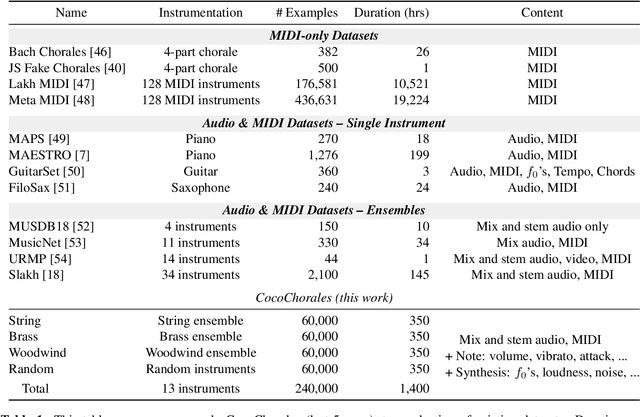
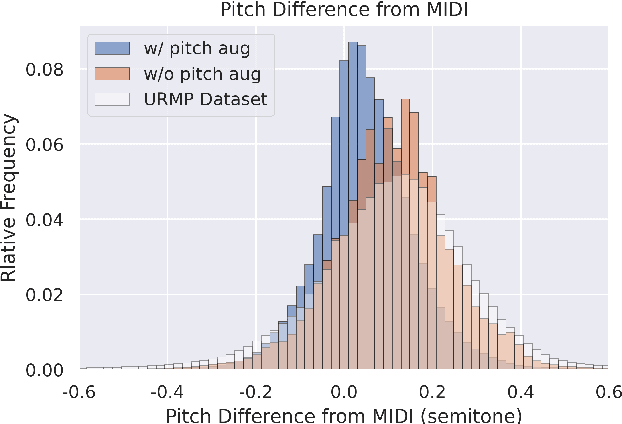
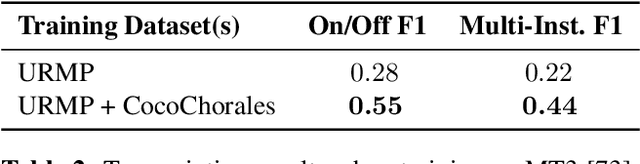
Data is the lifeblood of modern machine learning systems, including for those in Music Information Retrieval (MIR). However, MIR has long been mired by small datasets and unreliable labels. In this work, we propose to break this bottleneck using generative modeling. By pipelining a generative model of notes (Coconet trained on Bach Chorales) with a structured synthesis model of chamber ensembles (MIDI-DDSP trained on URMP), we demonstrate a system capable of producing unlimited amounts of realistic chorale music with rich annotations including mixes, stems, MIDI, note-level performance attributes (staccato, vibrato, etc.), and even fine-grained synthesis parameters (pitch, amplitude, etc.). We call this system the Chamber Ensemble Generator (CEG), and use it to generate a large dataset of chorales from four different chamber ensembles (CocoChorales). We demonstrate that data generated using our approach improves state-of-the-art models for music transcription and source separation, and we release both the system and the dataset as an open-source foundation for future work in the MIR community.
Multi-instrument Music Synthesis with Spectrogram Diffusion
Jun 11, 2022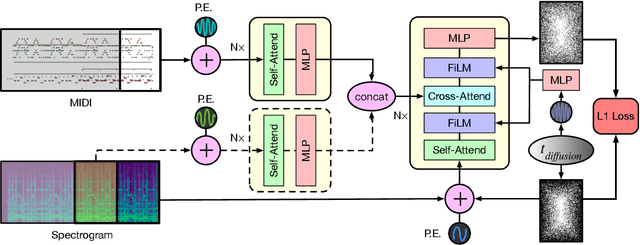
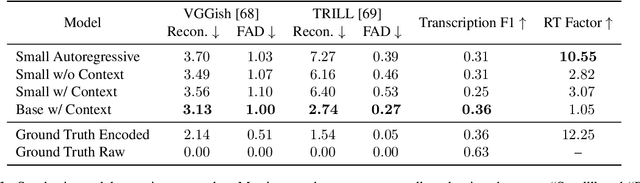

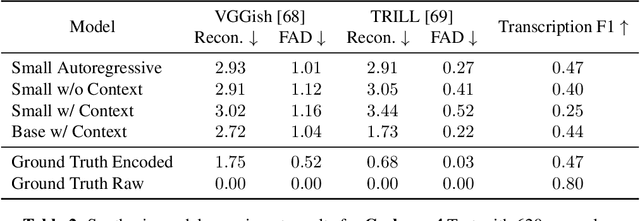
An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on all of music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fr\'echet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022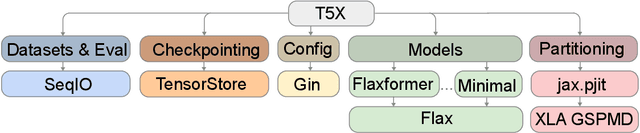
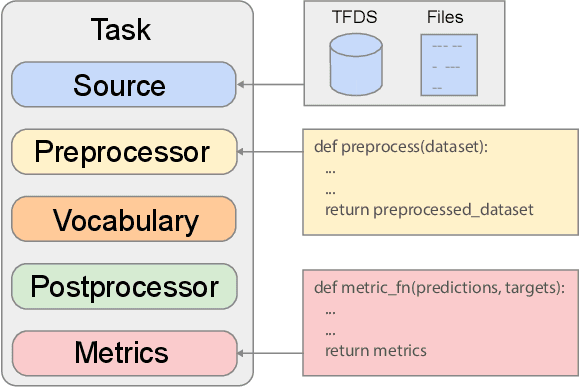
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
Improving Source Separation by Explicitly Modeling Dependencies Between Sources
Mar 28, 2022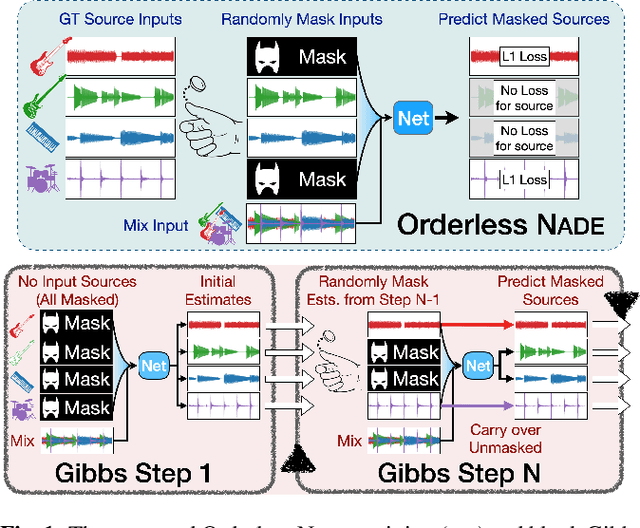
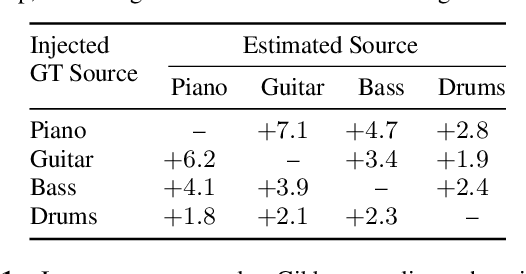
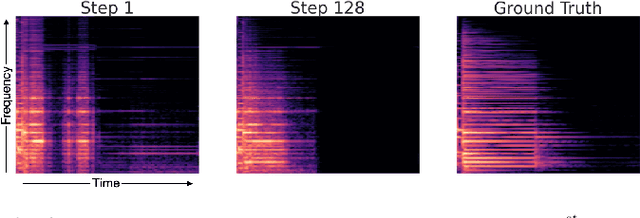
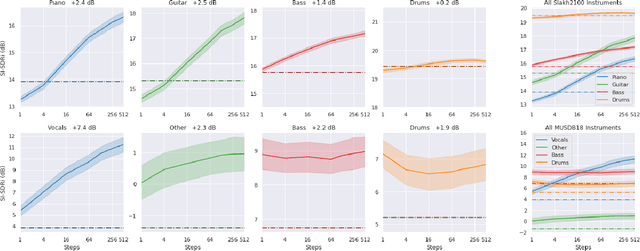
We propose a new method for training a supervised source separation system that aims to learn the interdependent relationships between all combinations of sources in a mixture. Rather than independently estimating each source from a mix, we reframe the source separation problem as an Orderless Neural Autoregressive Density Estimator (NADE), and estimate each source from both the mix and a random subset of the other sources. We adapt a standard source separation architecture, Demucs, with additional inputs for each individual source, in addition to the input mixture. We randomly mask these input sources during training so that the network learns the conditional dependencies between the sources. By pairing this training method with a block Gibbs sampling procedure at inference time, we demonstrate that the network can iteratively improve its separation performance by conditioning a source estimate on its earlier source estimates. Experiments on two source separation datasets show that training a Demucs model with an Orderless NADE approach and using Gibbs sampling (up to 512 steps) at inference time strongly outperforms a Demucs baseline that uses a standard regression loss and direct (one step) estimation of sources.
General-purpose, long-context autoregressive modeling with Perceiver AR
Feb 15, 2022
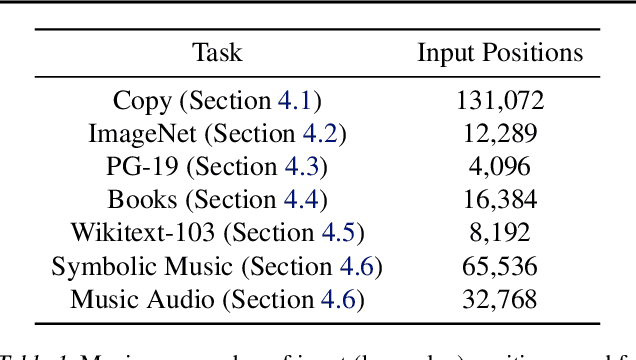
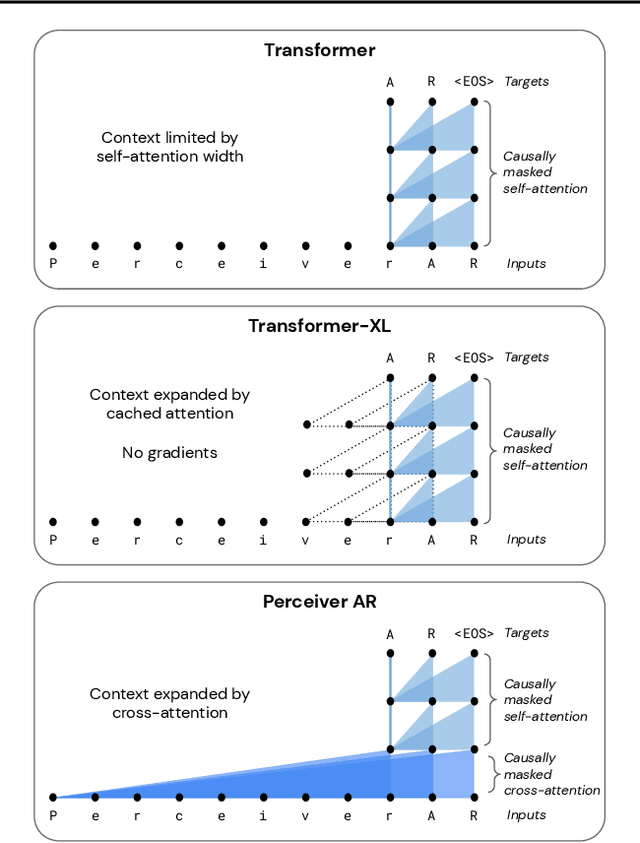
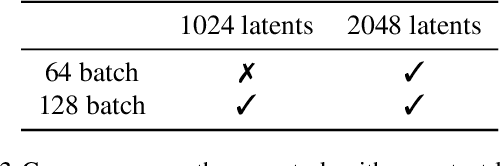
Real-world data is high-dimensional: a book, image, or musical performance can easily contain hundreds of thousands of elements even after compression. However, the most commonly used autoregressive models, Transformers, are prohibitively expensive to scale to the number of inputs and layers needed to capture this long-range structure. We develop Perceiver AR, an autoregressive, modality-agnostic architecture which uses cross-attention to map long-range inputs to a small number of latents while also maintaining end-to-end causal masking. Perceiver AR can directly attend to over a hundred thousand tokens, enabling practical long-context density estimation without the need for hand-crafted sparsity patterns or memory mechanisms. When trained on images or music, Perceiver AR generates outputs with clear long-term coherence and structure. Our architecture also obtains state-of-the-art likelihood on long-sequence benchmarks, including 64 x 64 ImageNet images and PG-19 books.
MT3: Multi-Task Multitrack Music Transcription
Nov 10, 2021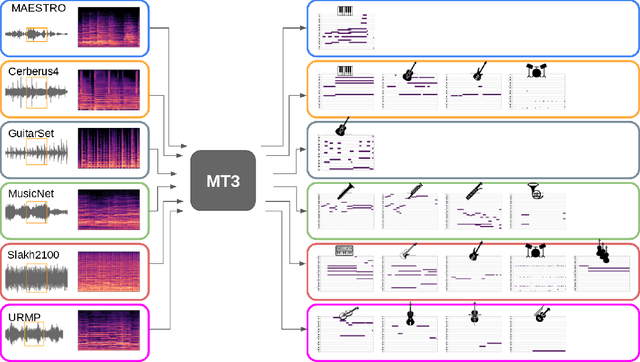

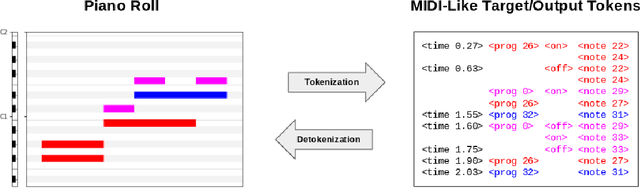
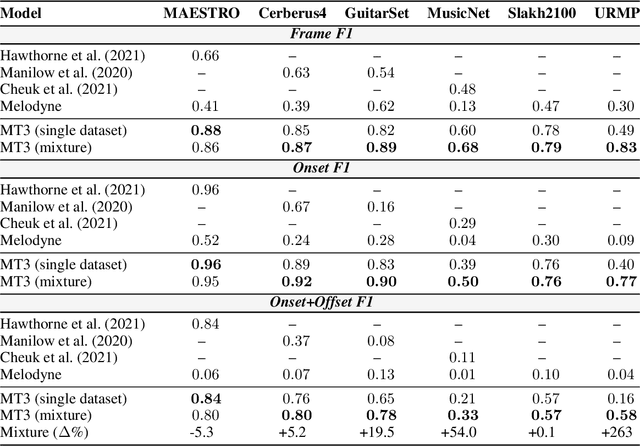
Automatic Music Transcription (AMT), inferring musical notes from raw audio, is a challenging task at the core of music understanding. Unlike Automatic Speech Recognition (ASR), which typically focuses on the words of a single speaker, AMT often requires transcribing multiple instruments simultaneously, all while preserving fine-scale pitch and timing information. Further, many AMT datasets are "low-resource", as even expert musicians find music transcription difficult and time-consuming. Thus, prior work has focused on task-specific architectures, tailored to the individual instruments of each task. In this work, motivated by the promising results of sequence-to-sequence transfer learning for low-resource Natural Language Processing (NLP), we demonstrate that a general-purpose Transformer model can perform multi-task AMT, jointly transcribing arbitrary combinations of musical instruments across several transcription datasets. We show this unified training framework achieves high-quality transcription results across a range of datasets, dramatically improving performance for low-resource instruments (such as guitar), while preserving strong performance for abundant instruments (such as piano). Finally, by expanding the scope of AMT, we expose the need for more consistent evaluation metrics and better dataset alignment, and provide a strong baseline for this new direction of multi-task AMT.
Sequence-to-Sequence Piano Transcription with Transformers
Jul 19, 2021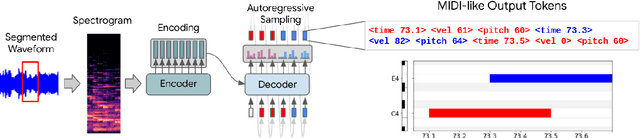



Automatic Music Transcription has seen significant progress in recent years by training custom deep neural networks on large datasets. However, these models have required extensive domain-specific design of network architectures, input/output representations, and complex decoding schemes. In this work, we show that equivalent performance can be achieved using a generic encoder-decoder Transformer with standard decoding methods. We demonstrate that the model can learn to translate spectrogram inputs directly to MIDI-like output events for several transcription tasks. This sequence-to-sequence approach simplifies transcription by jointly modeling audio features and language-like output dependencies, thus removing the need for task-specific architectures. These results point toward possibilities for creating new Music Information Retrieval models by focusing on dataset creation and labeling rather than custom model design.
Symbolic Music Generation with Diffusion Models
Mar 30, 2021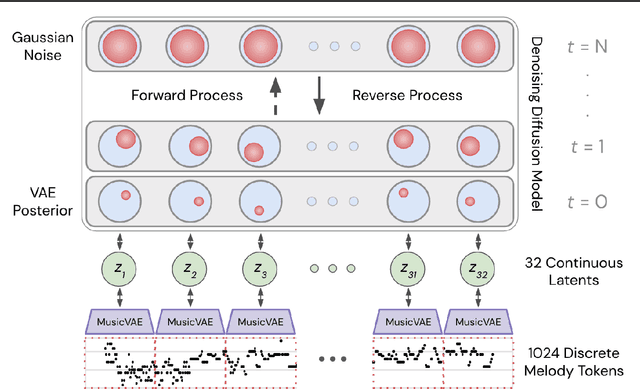
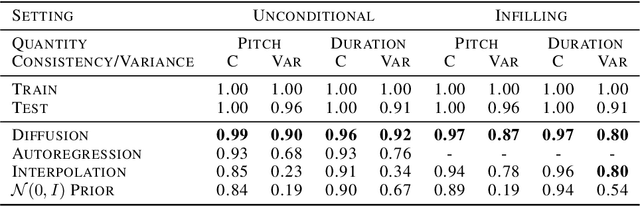
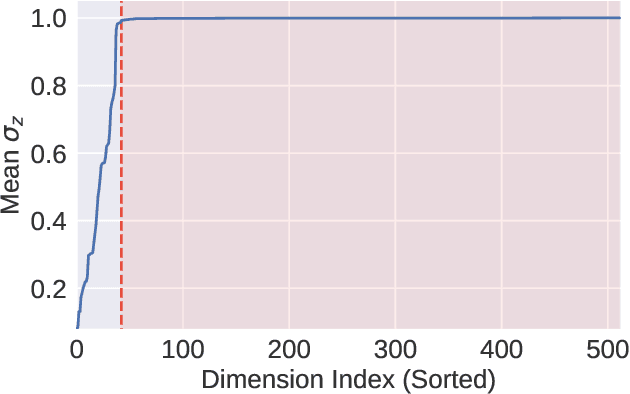
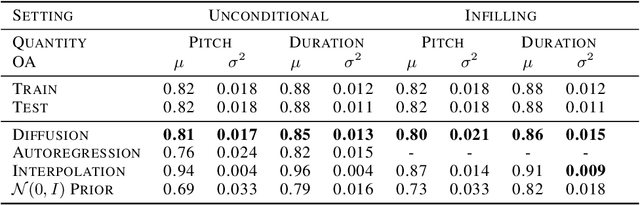
Score-based generative models and diffusion probabilistic models have been successful at generating high-quality samples in continuous domains such as images and audio. However, due to their Langevin-inspired sampling mechanisms, their application to discrete and sequential data has been limited. In this work, we present a technique for training diffusion models on sequential data by parameterizing the discrete domain in the continuous latent space of a pre-trained variational autoencoder. Our method is non-autoregressive and learns to generate sequences of latent embeddings through the reverse process and offers parallel generation with a constant number of iterative refinement steps. We apply this technique to modeling symbolic music and show strong unconditional generation and post-hoc conditional infilling results compared to autoregressive language models operating over the same continuous embeddings.
Improving Perceptual Quality of Drum Transcription with the Expanded Groove MIDI Dataset
Apr 08, 2020
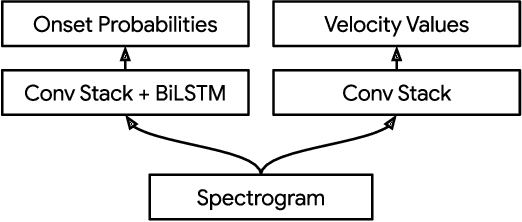
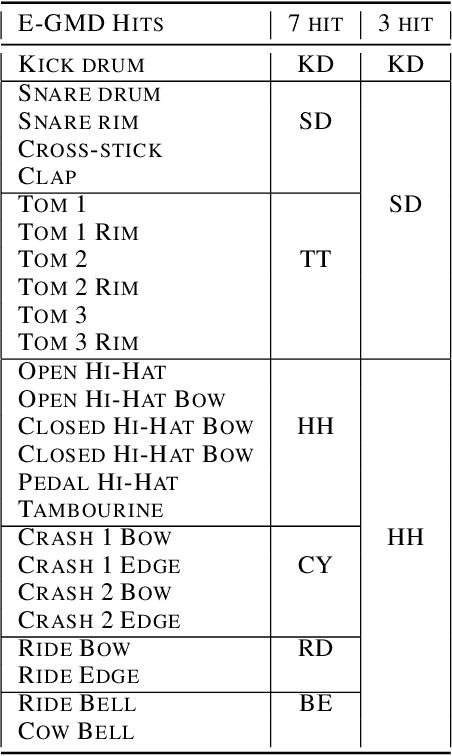
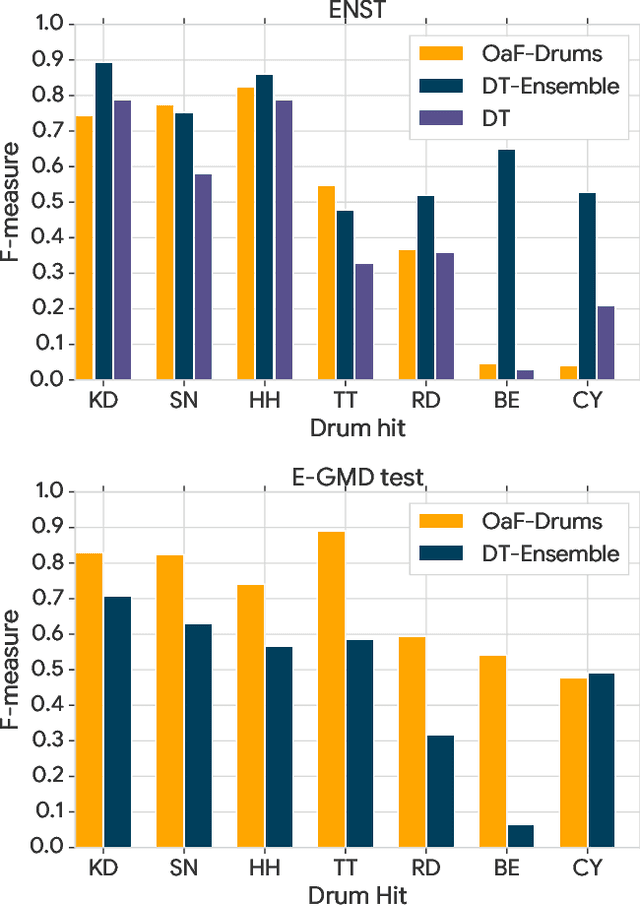
Classifier metrics, such as accuracy and F-measure score, often serve as proxies for performance in downstream tasks. For the case of generative systems that use predicted labels as inputs, accuracy is a good proxy only if it aligns with the perceptual quality of generated outputs. Here, we demonstrate this effect using the example of automatic drum transcription (ADT). We optimize classifiers for downstream generation by predicting expressive dynamics (velocity) and show with listening tests that they produce outputs with improved perceptual quality, despite achieving similar results on classification metrics. To train expressive ADT models, we introduce the Expanded Groove MIDI dataset (E-GMD), a large dataset of human drum performances, with audio recordings annotated in MIDI. E-GMD contains 444 hours of audio from 43 drum kits and is an order of magnitude larger than similar datasets. It is also the first human-performed drum dataset with annotations of velocity. We make this new dataset available under a Creative Commons license along with open source code for training and a pre-trained model for inference.