 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Perceptual Quality of Drum Transcription with the Expanded Groove MIDI Dataset
Apr 08, 2020
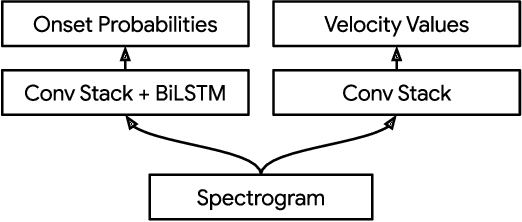
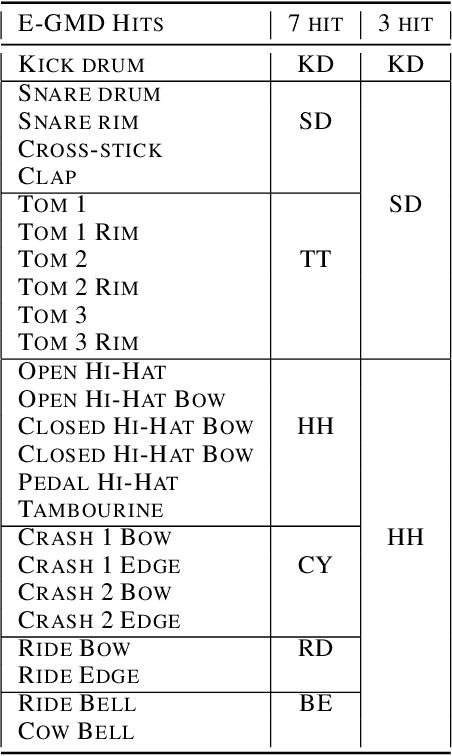
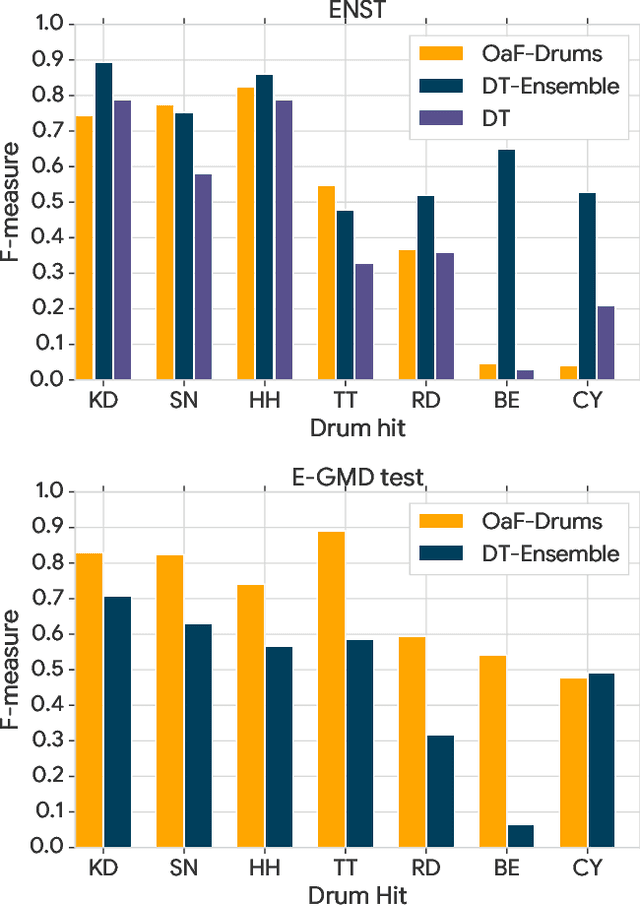
Classifier metrics, such as accuracy and F-measure score, often serve as proxies for performance in downstream tasks. For the case of generative systems that use predicted labels as inputs, accuracy is a good proxy only if it aligns with the perceptual quality of generated outputs. Here, we demonstrate this effect using the example of automatic drum transcription (ADT). We optimize classifiers for downstream generation by predicting expressive dynamics (velocity) and show with listening tests that they produce outputs with improved perceptual quality, despite achieving similar results on classification metrics. To train expressive ADT models, we introduce the Expanded Groove MIDI dataset (E-GMD), a large dataset of human drum performances, with audio recordings annotated in MIDI. E-GMD contains 444 hours of audio from 43 drum kits and is an order of magnitude larger than similar datasets. It is also the first human-performed drum dataset with annotations of velocity. We make this new dataset available under a Creative Commons license along with open source code for training and a pre-trained model for inference.