 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Diffusion Models: Efficient Fine-Tuning and Post-Training of Interactive Diffusion Music Generators
May 21, 2026Interactive streaming music generation promises the use of generative models for live performance and co-creation that is impossible with offline models. However, SOTA models exist in the discrete-AR regime, requiring industrial levels of compute for both training and inference. In this work, we investigate whether audio diffusion models, with their wide support in the open-source community but non-streaming bidirectional nature, can be repurposed efficiently into interactive models accessible on consumer hardware. By taking a critical look at the modern pipeline for block-wise outpainting diffusion, we identify critical inefficiencies during inference that result in strictly worse computational efficiency than their discrete-AR counterparts. We propose Live Music Diffusion Models (LMDMs), a simple modification of the generative diffusion process that recovers, and then outperforms, the inference complexity of the discrete Live Music Models (LMMs) through block-wise KV Caching. Unlike LMMs, LMDMs further enable stable post-training alignment through our novel ARC-Forcing paradigm, reducing error accumulation without any explicit RL or reward models. We demonstrate the application of LMDMs in a number of creative domains, including text-conditioned generation, sketch-based music synthesis, and jamming. We finally show how LMDMs can be used as a generative instrument in a real artist-AI collaboration, utilizing LMDMs as a "generative delay" to transform musicians' improvisation live for variable timbral effects while running locally on a consumer gaming laptop.
Latent Fourier Transform
Apr 20, 2026We introduce the Latent Fourier Transform (LatentFT), a framework that provides novel frequency-domain controls for generative music models. LatentFT combines a diffusion autoencoder with a latent-space Fourier transform to separate musical patterns by timescale. By masking latents in the frequency domain during training, our method yields representations that can be manipulated coherently at inference. This allows us to generate musical variations and blends from reference examples while preserving characteristics at desired timescales, which are specified as frequencies in the latent space. LatentFT parallels the role of the equalizer in music production: while traditional equalizers operates on audible frequencies to shape timbre, LatentFT operates on latent-space frequencies to shape musical structure. Experiments and listening tests show that LatentFT improves condition adherence and quality compared to baselines. We also present a technique for hearing frequencies in the latent space in isolation, and show different musical attributes reside in different regions of the latent spectrum. Our results show how frequency-domain control in latent space provides an intuitive, continuous frequency axis for conditioning and blending, advancing us toward more interpretable and interactive generative music models.
Stemphonic: All-at-once Flexible Multi-stem Music Generation
Feb 10, 2026Music stem generation, the task of producing musically-synchronized and isolated instrument audio clips, offers the potential of greater user control and better alignment with musician workflows compared to conventional text-to-music models. Existing stem generation approaches, however, either rely on fixed architectures that output a predefined set of stems in parallel, or generate only one stem at a time, resulting in slow inference despite flexibility in stem combination. We propose Stemphonic, a diffusion-/flow-based framework that overcomes this trade-off and generates a variable set of synchronized stems in one inference pass. During training, we treat each stem as a batch element, group synchronized stems in a batch, and apply a shared noise latent to each group. At inference-time, we use a shared initial noise latent and stem-specific text inputs to generate synchronized multi-stem outputs in one pass. We further expand our approach to enable one-pass conditional multi-stem generation and stem-wise activity controls to empower users to iteratively generate and orchestrate the temporal layering of a mix. We benchmark our results on multiple open-source stem evaluation sets and show that Stemphonic produces higher-quality outputs while accelerating the full mix generation process by 25 to 50%. Demos at: https://stemphonic-demo.vercel.app.
MIDI-LLM: Adapting Large Language Models for Text-to-MIDI Music Generation
Nov 06, 2025We present MIDI-LLM, an LLM for generating multitrack MIDI music from free-form text prompts. Our approach expands a text LLM's vocabulary to include MIDI tokens, and uses a two-stage training recipe to endow text-to-MIDI abilities. By preserving the original LLM's parameter structure, we can directly leverage the vLLM library for accelerated inference. Experiments show that MIDI-LLM achieves higher quality, better text control, and faster inference compared to the recent Text2midi model. Live demo at https://midi-llm-demo.vercel.app.
Adaptive Accompaniment with ReaLchords
Jun 17, 2025Jamming requires coordination, anticipation, and collaborative creativity between musicians. Current generative models of music produce expressive output but are not able to generate in an \emph{online} manner, meaning simultaneously with other musicians (human or otherwise). We propose ReaLchords, an online generative model for improvising chord accompaniment to user melody. We start with an online model pretrained by maximum likelihood, and use reinforcement learning to finetune the model for online use. The finetuning objective leverages both a novel reward model that provides feedback on both harmonic and temporal coherency between melody and chord, and a divergence term that implements a novel type of distillation from a teacher model that can see the future melody. Through quantitative experiments and listening tests, we demonstrate that the resulting model adapts well to unfamiliar input and produce fitting accompaniment. ReaLchords opens the door to live jamming, as well as simultaneous co-creation in other modalities.
FLAM: Frame-Wise Language-Audio Modeling
May 08, 2025Recent multi-modal audio-language models (ALMs) excel at text-audio retrieval but struggle with frame-wise audio understanding. Prior works use temporal-aware labels or unsupervised training to improve frame-wise capabilities, but they still lack fine-grained labeling capability to pinpoint when an event occurs. While traditional sound event detection models can precisely localize events, they are limited to pre-defined categories, making them ineffective for real-world scenarios with out-of-distribution events. In this work, we introduce FLAM, an open-vocabulary contrastive audio-language model capable of localizing specific sound events. FLAM employs a memory-efficient and calibrated frame-wise objective with logit adjustment to address spurious correlations, such as event dependencies and label imbalances during training. To enable frame-wise supervision, we leverage a large-scale dataset with diverse audio events, LLM-generated captions and simulation. Experimental results and case studies demonstrate that FLAM significantly improves the open-vocabulary localization capability while maintaining strong performance in global retrieval and downstream tasks.
ReaLJam: Real-Time Human-AI Music Jamming with Reinforcement Learning-Tuned Transformers
Feb 28, 2025Recent advances in generative artificial intelligence (AI) have created models capable of high-quality musical content generation. However, little consideration is given to how to use these models for real-time or cooperative jamming musical applications because of crucial required features: low latency, the ability to communicate planned actions, and the ability to adapt to user input in real-time. To support these needs, we introduce ReaLJam, an interface and protocol for live musical jamming sessions between a human and a Transformer-based AI agent trained with reinforcement learning. We enable real-time interactions using the concept of anticipation, where the agent continually predicts how the performance will unfold and visually conveys its plan to the user. We conduct a user study where experienced musicians jam in real-time with the agent through ReaLJam. Our results demonstrate that ReaLJam enables enjoyable and musically interesting sessions, and we uncover important takeaways for future work.
Exploratory Study Of Human-AI Interaction For Hindustani Music
Nov 21, 2024This paper presents a study of participants interacting with and using GaMaDHaNi, a novel hierarchical generative model for Hindustani vocal contours. To explore possible use cases in human-AI interaction, we conducted a user study with three participants, each engaging with the model through three predefined interaction modes. Although this study was conducted "in the wild"- with the model unadapted for the shift from the training data to real-world interaction - we use it as a pilot to better understand the expectations, reactions, and preferences of practicing musicians when engaging with such a model. We note their challenges as (1) the lack of restrictions in model output, and (2) the incoherence of model output. We situate these challenges in the context of Hindustani music and aim to suggest future directions for the model design to address these gaps.
Hierarchical Generative Modeling of Melodic Vocal Contours in Hindustani Classical Music
Aug 26, 2024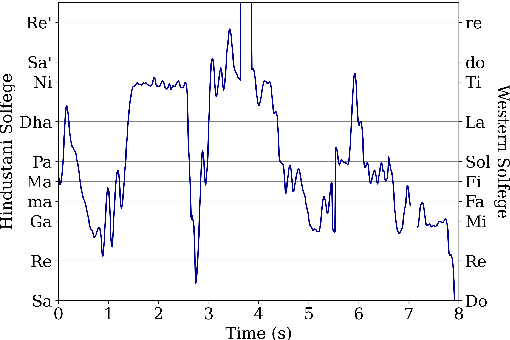
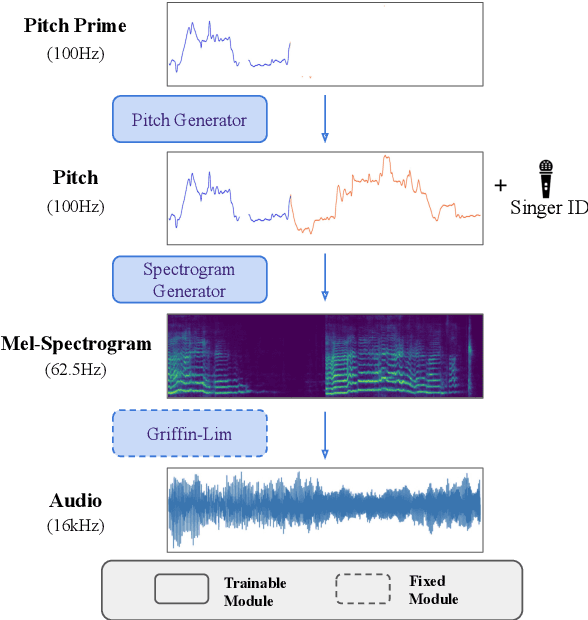
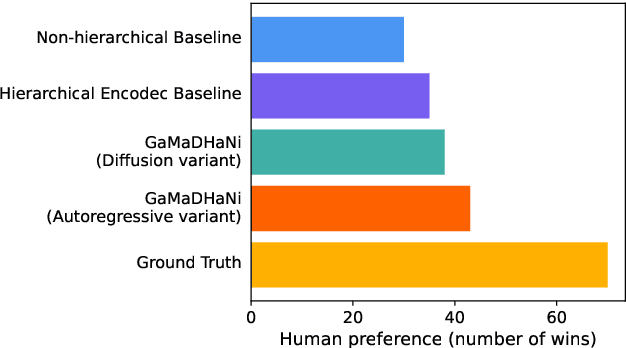
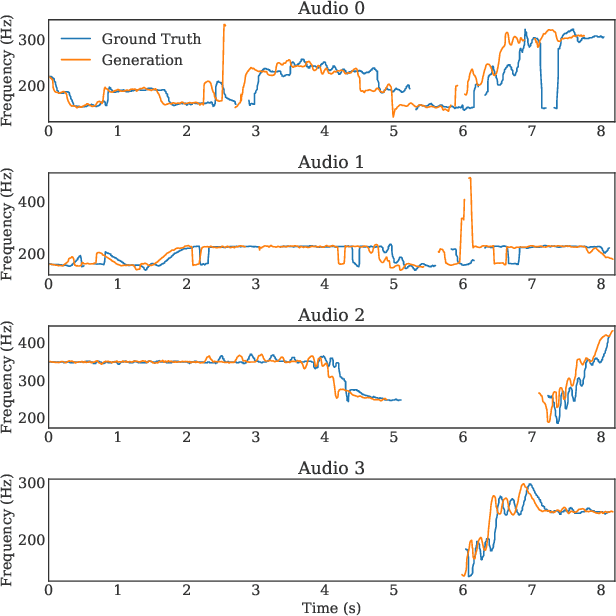
Hindustani music is a performance-driven oral tradition that exhibits the rendition of rich melodic patterns. In this paper, we focus on generative modeling of singers' vocal melodies extracted from audio recordings, as the voice is musically prominent within the tradition. Prior generative work in Hindustani music models melodies as coarse discrete symbols which fails to capture the rich expressive melodic intricacies of singing. Thus, we propose to use a finely quantized pitch contour, as an intermediate representation for hierarchical audio modeling. We propose GaMaDHaNi, a modular two-level hierarchy, consisting of a generative model on pitch contours, and a pitch contour to audio synthesis model. We compare our approach to non-hierarchical audio models and hierarchical models that use a self-supervised intermediate representation, through a listening test and qualitative analysis. We also evaluate audio model's ability to faithfully represent the pitch contour input using Pearson correlation coefficient. By using pitch contours as an intermediate representation, we show that our model may be better equipped to listen and respond to musicians in a human-AI collaborative setting by highlighting two potential interaction use cases (1) primed generation, and (2) coarse pitch conditioning.
Improving Source Separation by Explicitly Modeling Dependencies Between Sources
Mar 28, 2022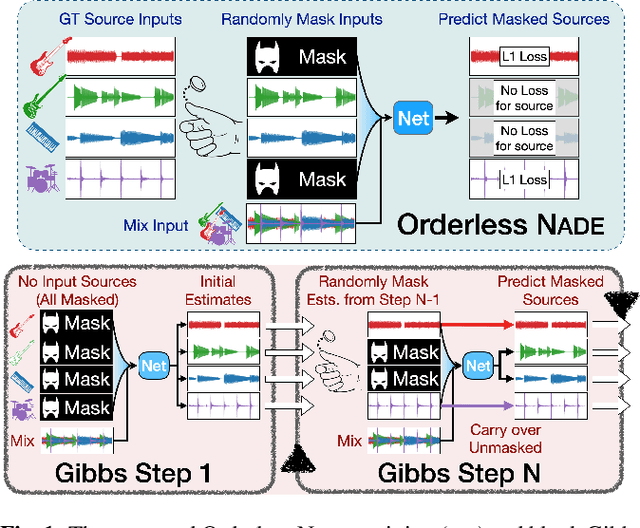
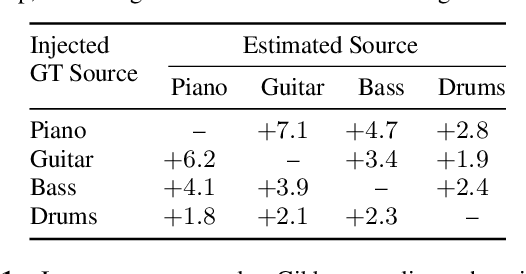
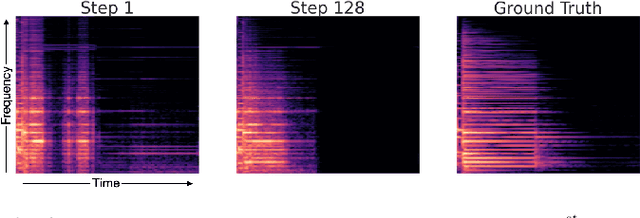
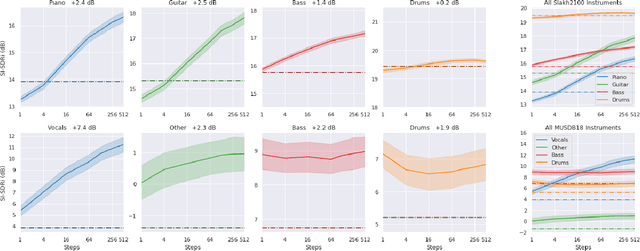
We propose a new method for training a supervised source separation system that aims to learn the interdependent relationships between all combinations of sources in a mixture. Rather than independently estimating each source from a mix, we reframe the source separation problem as an Orderless Neural Autoregressive Density Estimator (NADE), and estimate each source from both the mix and a random subset of the other sources. We adapt a standard source separation architecture, Demucs, with additional inputs for each individual source, in addition to the input mixture. We randomly mask these input sources during training so that the network learns the conditional dependencies between the sources. By pairing this training method with a block Gibbs sampling procedure at inference time, we demonstrate that the network can iteratively improve its separation performance by conditioning a source estimate on its earlier source estimates. Experiments on two source separation datasets show that training a Demucs model with an Orderless NADE approach and using Gibbs sampling (up to 512 steps) at inference time strongly outperforms a Demucs baseline that uses a standard regression loss and direct (one step) estimation of sources.