 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Lossy Audio Compression Identification
Jul 31, 2024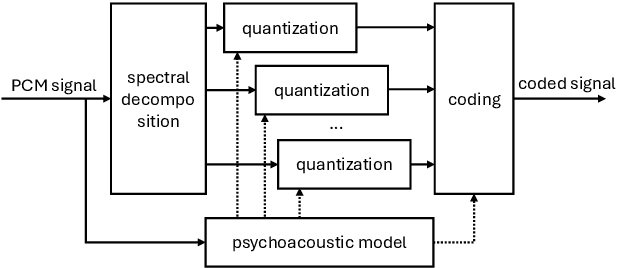

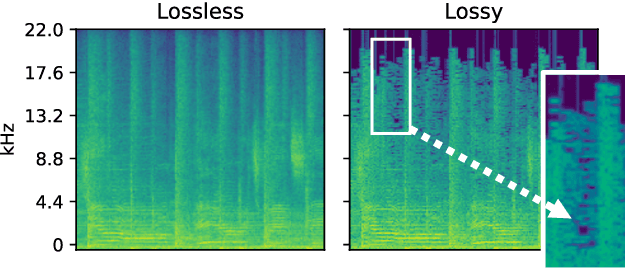

Previous research contributions on blind lossy compression identification report near perfect performance metrics on their test set, across a variety of codecs and bit rates. However, we show that such results can be deceptive and may not accurately represent true ability of the system to tackle the task at hand. In this article, we present an investigation into the robustness and generalisation capability of a lossy audio identification model. Our contributions are as follows. (1) We show the lack of robustness to codec parameter variations of a model equivalent to prior art. In particular, when naively training a lossy compression detection model on a dataset of music recordings processed with a range of codecs and their lossless counterparts, we obtain near perfect performance metrics on the held-out test set, but severely degraded performance on lossy tracks produced with codec parameters not seen in training. (2) We propose and show the effectiveness of an improved training strategy to significantly increase the robustness and generalisation capability of the model beyond codec configurations seen during training. Namely we apply a random mask to the input spectrogram to encourage the model not to rely solely on the training set's codec cutoff frequency.
Find the Cliffhanger: Multi-Modal Trailerness in Soap Operas
Jan 29, 2024Creating a trailer requires carefully picking out and piecing together brief enticing moments out of a longer video, making it a challenging and time-consuming task. This requires selecting moments based on both visual and dialogue information. We introduce a multi-modal method for predicting the trailerness to assist editors in selecting trailer-worthy moments from long-form videos. We present results on a newly introduced soap opera dataset, demonstrating that predicting trailerness is a challenging task that benefits from multi-modal information. Code is available at https://github.com/carlobretti/cliffhanger
Serenade: A Model for Human-in-the-loop Automatic Chord Estimation
Oct 17, 2023Computational harmony analysis is important for MIR tasks such as automatic segmentation, corpus analysis and automatic chord label estimation. However, recent research into the ambiguous nature of musical harmony, causing limited inter-rater agreement, has made apparent that there is a glass ceiling for common metrics such as accuracy. Commonly, these issues are addressed either in the training data itself by creating majority-rule annotations or during the training phase by learning soft targets. We propose a novel alternative approach in which a human and an autoregressive model together co-create a harmonic annotation for an audio track. After automatically generating harmony predictions, a human sparsely annotates parts with low model confidence and the model then adjusts its predictions following human guidance. We evaluate our model on a dataset of popular music and we show that, with this human-in-the-loop approach, harmonic analysis performance improves over a model-only approach. The human contribution is amplified by the second, constrained prediction of the model.
AI Song Contest: Human-AI Co-Creation in Songwriting
Oct 12, 2020
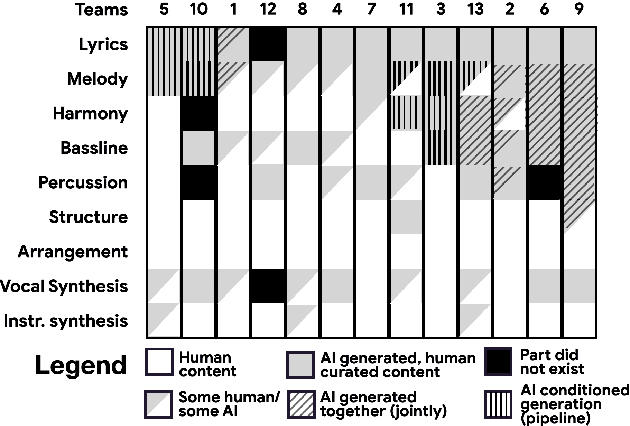
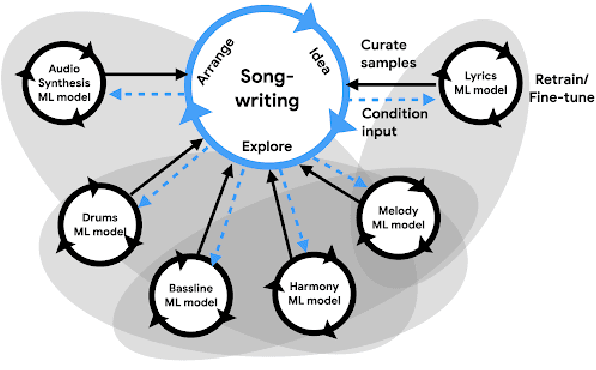
Machine learning is challenging the way we make music. Although research in deep generative models has dramatically improved the capability and fluency of music models, recent work has shown that it can be challenging for humans to partner with this new class of algorithms. In this paper, we present findings on what 13 musician/developer teams, a total of 61 users, needed when co-creating a song with AI, the challenges they faced, and how they leveraged and repurposed existing characteristics of AI to overcome some of these challenges. Many teams adopted modular approaches, such as independently running multiple smaller models that align with the musical building blocks of a song, before re-combining their results. As ML models are not easily steerable, teams also generated massive numbers of samples and curated them post-hoc, or used a range of strategies to direct the generation, or algorithmically ranked the samples. Ultimately, teams not only had to manage the "flare and focus" aspects of the creative process, but also juggle them with a parallel process of exploring and curating multiple ML models and outputs. These findings reflect a need to design machine learning-powered music interfaces that are more decomposable, steerable, interpretable, and adaptive, which in return will enable artists to more effectively explore how AI can extend their personal expression.
* 6 pages + 3 pages of references