 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Lossy Audio Compression Identification
Paper and Code
Jul 31, 2024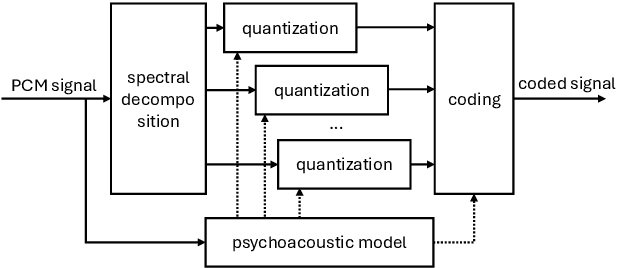

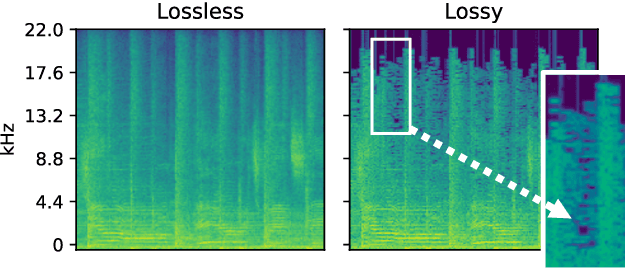

Previous research contributions on blind lossy compression identification report near perfect performance metrics on their test set, across a variety of codecs and bit rates. However, we show that such results can be deceptive and may not accurately represent true ability of the system to tackle the task at hand. In this article, we present an investigation into the robustness and generalisation capability of a lossy audio identification model. Our contributions are as follows. (1) We show the lack of robustness to codec parameter variations of a model equivalent to prior art. In particular, when naively training a lossy compression detection model on a dataset of music recordings processed with a range of codecs and their lossless counterparts, we obtain near perfect performance metrics on the held-out test set, but severely degraded performance on lossy tracks produced with codec parameters not seen in training. (2) We propose and show the effectiveness of an improved training strategy to significantly increase the robustness and generalisation capability of the model beyond codec configurations seen during training. Namely we apply a random mask to the input spectrogram to encourage the model not to rely solely on the training set's codec cutoff frequency.