 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugInsert: Learning Robust Visual-Force Policies via Data Augmentation for Object Assembly Tasks
Oct 19, 2024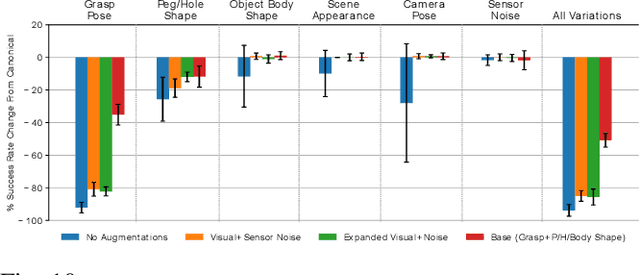
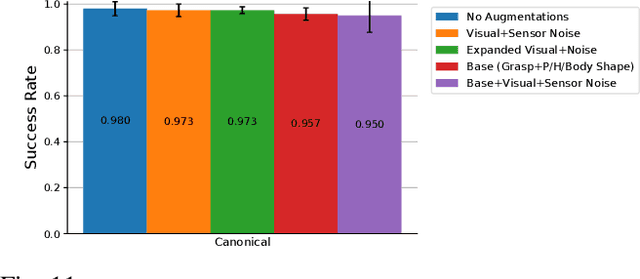
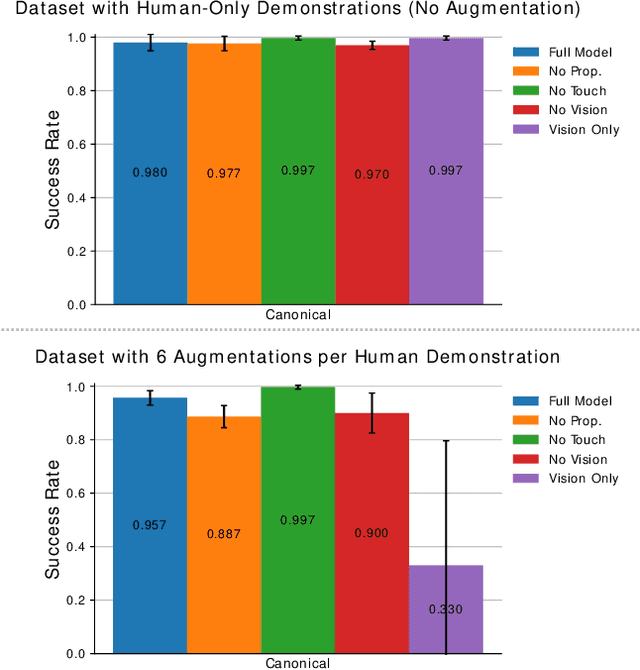

This paper primarily focuses on learning robust visual-force policies in the context of high-precision object assembly tasks. Specifically, we focus on the contact phase of the assembly task where both objects (peg and hole) have made contact and the objective lies in maneuvering the objects to complete the assembly. Moreover, we aim to learn contact-rich manipulation policies with multisensory inputs on limited expert data by expanding human demonstrations via online data augmentation. We develop a simulation environment with a dual-arm robot manipulator to evaluate the effect of augmented expert demonstration data. Our focus is on evaluating the robustness of our model with respect to certain task variations: grasp pose, peg/hole shape, object body shape, scene appearance, camera pose, and force-torque/proprioception noise. We show that our proposed data augmentation method helps in learning a multisensory manipulation policy that is robust to unseen instances of these variations, particularly physical variations such as grasp pose. Additionally, our ablative studies show the significant contribution of force-torque data to the robustness of our model. For additional experiments and qualitative results, we refer to the project webpage at https://bit.ly/47skWXH .
Evaluating Robustness of Visual Representations for Object Assembly Task Requiring Spatio-Geometrical Reasoning
Oct 22, 2023



This paper primarily focuses on evaluating and benchmarking the robustness of visual representations in the context of object assembly tasks. Specifically, it investigates the alignment and insertion of objects with geometrical extrusions and intrusions, commonly referred to as a peg-in-hole task. The accuracy required to detect and orient the peg and the hole geometry in SE(3) space for successful assembly poses significant challenges. Addressing this, we employ a general framework in visuomotor policy learning that utilizes visual pretraining models as vision encoders. Our study investigates the robustness of this framework when applied to a dual-arm manipulation setup, specifically to the grasp variations. Our quantitative analysis shows that existing pretrained models fail to capture the essential visual features necessary for this task. However, a visual encoder trained from scratch consistently outperforms the frozen pretrained models. Moreover, we discuss rotation representations and associated loss functions that substantially improve policy learning. We present a novel task scenario designed to evaluate the progress in visuomotor policy learning, with a specific focus on improving the robustness of intricate assembly tasks that require both geometrical and spatial reasoning. Videos, additional experiments, dataset, and code are available at https://bit.ly/geometric-peg-in-hole .