 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARK-Remote: A Cost-Effective System for Remote Bimanual Robot Teleoperation
Apr 07, 2025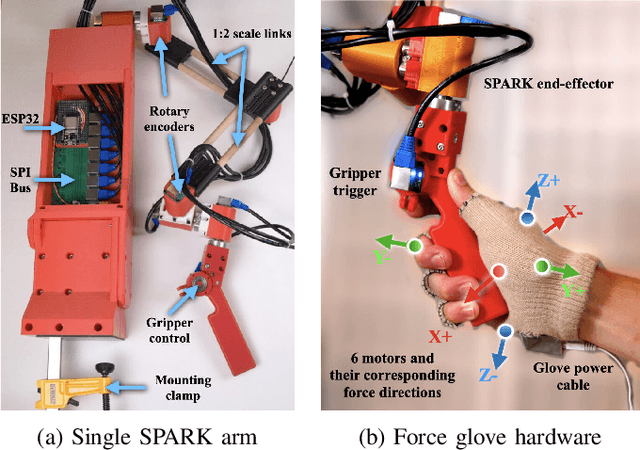
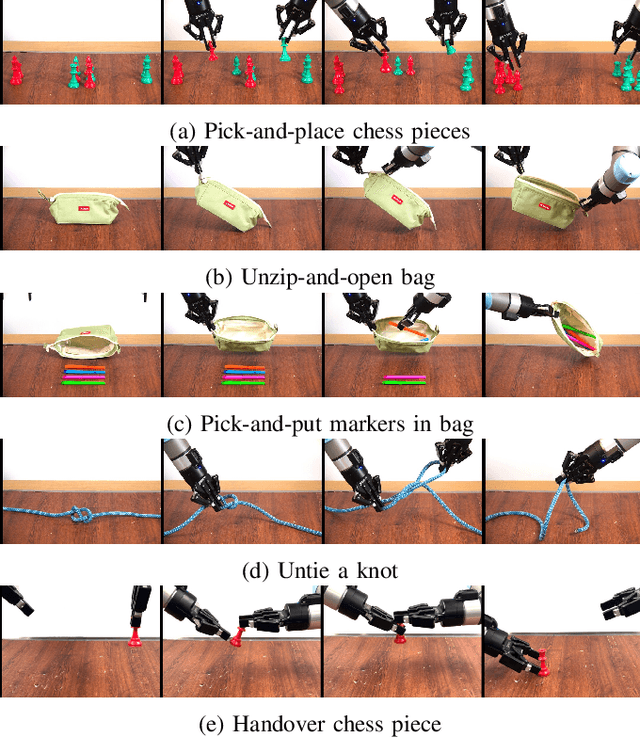
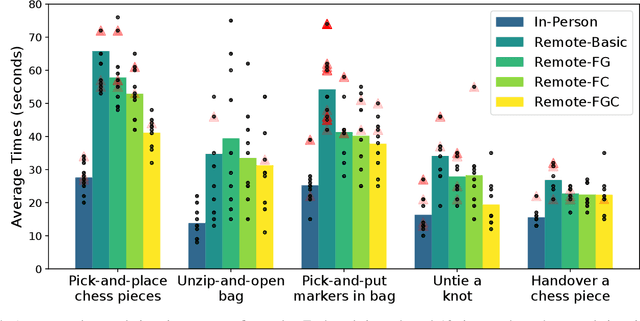
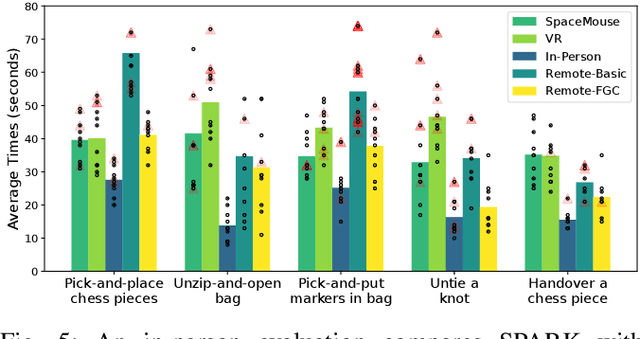
Robot teleoperation enables human control over robotic systems in environments where full autonomy is challenging. Recent advancements in low-cost teleoperation devices and VR/AR technologies have expanded accessibility, particularly for bimanual robot manipulators. However, transitioning from in-person to remote teleoperation presents challenges in task performance. We introduce SPARK, a kinematically scaled, low-cost teleoperation system for operating bimanual robots. Its effectiveness is compared to existing technologies like the 3D SpaceMouse and VR/AR controllers. We further extend SPARK to SPARK-Remote, integrating sensor-based force feedback using haptic gloves and a force controller for remote teleoperation. We evaluate SPARK and SPARK-Remote variants on 5 bimanual manipulation tasks which feature operational properties - positional precision, rotational precision, large movements in the workspace, and bimanual collaboration - to test the effective teleoperation modes. Our findings offer insights into improving low-cost teleoperation interfaces for real-world applications. For supplementary materials, additional experiments, and qualitative results, visit the project webpage: https://bit.ly/41EfcJa
AugInsert: Learning Robust Visual-Force Policies via Data Augmentation for Object Assembly Tasks
Oct 19, 2024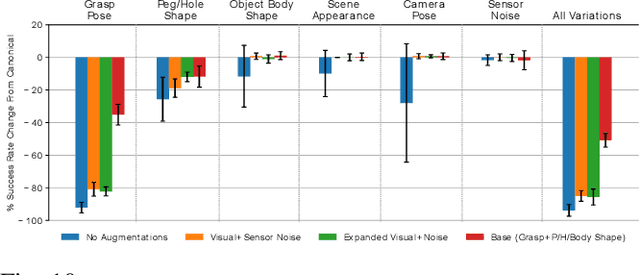
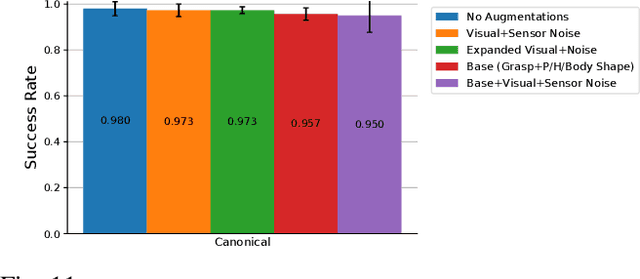
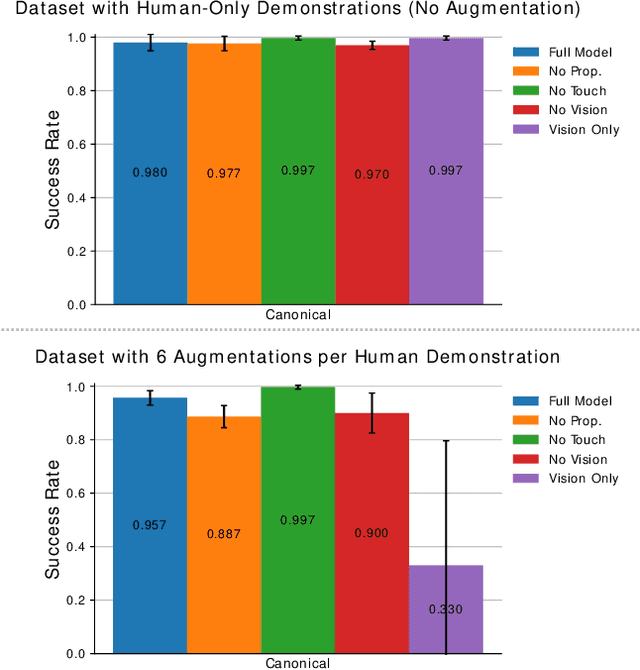

This paper primarily focuses on learning robust visual-force policies in the context of high-precision object assembly tasks. Specifically, we focus on the contact phase of the assembly task where both objects (peg and hole) have made contact and the objective lies in maneuvering the objects to complete the assembly. Moreover, we aim to learn contact-rich manipulation policies with multisensory inputs on limited expert data by expanding human demonstrations via online data augmentation. We develop a simulation environment with a dual-arm robot manipulator to evaluate the effect of augmented expert demonstration data. Our focus is on evaluating the robustness of our model with respect to certain task variations: grasp pose, peg/hole shape, object body shape, scene appearance, camera pose, and force-torque/proprioception noise. We show that our proposed data augmentation method helps in learning a multisensory manipulation policy that is robust to unseen instances of these variations, particularly physical variations such as grasp pose. Additionally, our ablative studies show the significant contribution of force-torque data to the robustness of our model. For additional experiments and qualitative results, we refer to the project webpage at https://bit.ly/47skWXH .
Talk Through It: End User Directed Manipulation Learning
Feb 19, 2024



Training generalist robot agents is an immensely difficult feat due to the requirement to perform a huge range of tasks in many different environments. We propose selectively training robots based on end-user preferences instead. Given a factory model that lets an end user instruct a robot to perform lower-level actions (e.g. 'Move left'), we show that end users can collect demonstrations using language to train their home model for higher-level tasks specific to their needs (e.g. 'Open the top drawer and put the block inside'). We demonstrate this hierarchical robot learning framework on robot manipulation tasks using RLBench environments. Our method results in a 16% improvement in skill success rates compared to a baseline method. In further experiments, we explore the use of the large vision-language model (VLM), Bard, to automatically break down tasks into sequences of lower-level instructions, aiming to bypass end-user involvement. The VLM is unable to break tasks down to our lowest level, but does achieve good results breaking high-level tasks into mid-level skills. We have a supplemental video and additional results at talk-through-it.github.io.