 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Category-level Last-meter Navigation from RGB Demonstrations of a Single-instance
Dec 11, 2025Achieving precise positioning of the mobile manipulator's base is essential for successful manipulation actions that follow. Most of the RGB-based navigation systems only guarantee coarse, meter-level accuracy, making them less suitable for the precise positioning phase of mobile manipulation. This gap prevents manipulation policies from operating within the distribution of their training demonstrations, resulting in frequent execution failures. We address this gap by introducing an object-centric imitation learning framework for last-meter navigation, enabling a quadruped mobile manipulator robot to achieve manipulation-ready positioning using only RGB observations from its onboard cameras. Our method conditions the navigation policy on three inputs: goal images, multi-view RGB observations from the onboard cameras, and a text prompt specifying the target object. A language-driven segmentation module and a spatial score-matrix decoder then supply explicit object grounding and relative pose reasoning. Using real-world data from a single object instance within a category, the system generalizes to unseen object instances across diverse environments with challenging lighting and background conditions. To comprehensively evaluate this, we introduce two metrics: an edge-alignment metric, which uses ground truth orientation, and an object-alignment metric, which evaluates how well the robot visually faces the target. Under these metrics, our policy achieves 73.47% success in edge-alignment and 96.94% success in object-alignment when positioning relative to unseen target objects. These results show that precise last-meter navigation can be achieved at a category-level without depth, LiDAR, or map priors, enabling a scalable pathway toward unified mobile manipulation. Project page: https://rpm-lab-umn.github.io/category-level-last-meter-nav/
SPARK-Remote: A Cost-Effective System for Remote Bimanual Robot Teleoperation
Apr 07, 2025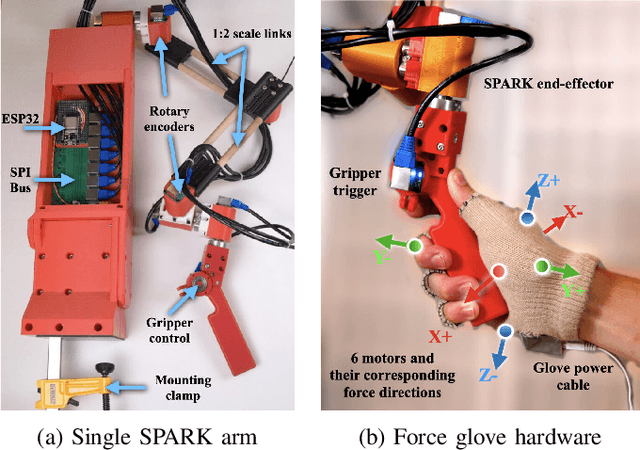
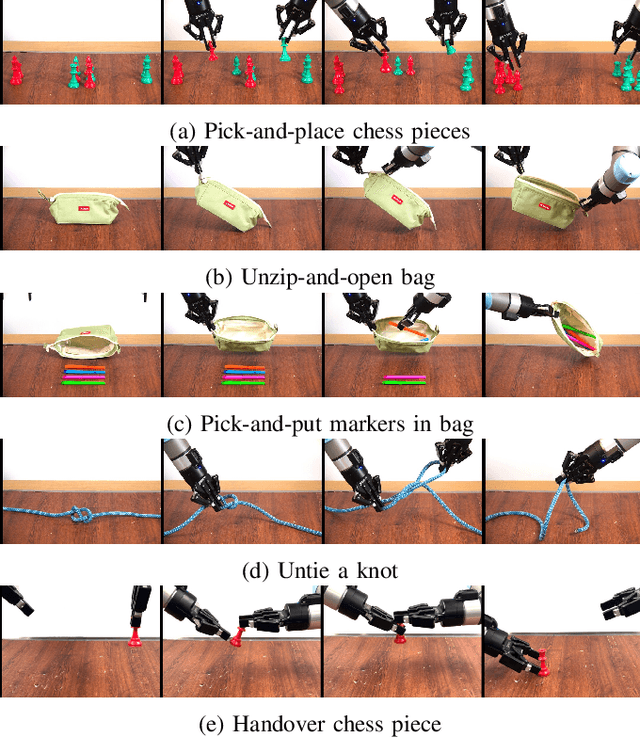
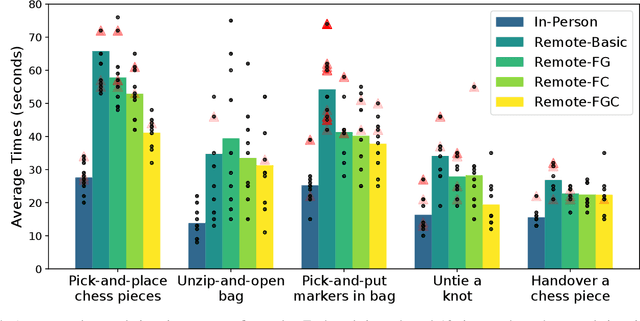
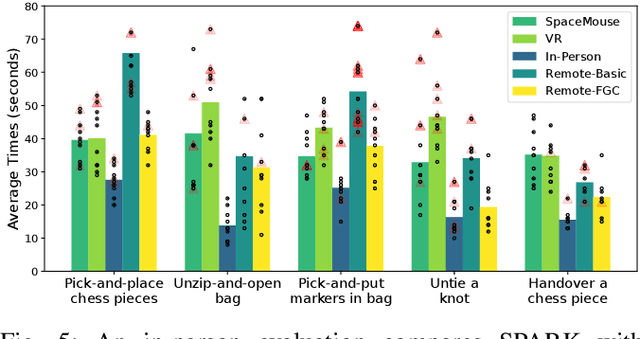
Robot teleoperation enables human control over robotic systems in environments where full autonomy is challenging. Recent advancements in low-cost teleoperation devices and VR/AR technologies have expanded accessibility, particularly for bimanual robot manipulators. However, transitioning from in-person to remote teleoperation presents challenges in task performance. We introduce SPARK, a kinematically scaled, low-cost teleoperation system for operating bimanual robots. Its effectiveness is compared to existing technologies like the 3D SpaceMouse and VR/AR controllers. We further extend SPARK to SPARK-Remote, integrating sensor-based force feedback using haptic gloves and a force controller for remote teleoperation. We evaluate SPARK and SPARK-Remote variants on 5 bimanual manipulation tasks which feature operational properties - positional precision, rotational precision, large movements in the workspace, and bimanual collaboration - to test the effective teleoperation modes. Our findings offer insights into improving low-cost teleoperation interfaces for real-world applications. For supplementary materials, additional experiments, and qualitative results, visit the project webpage: https://bit.ly/41EfcJa
SuperQ-GRASP: Superquadrics-based Grasp Pose Estimation on Larger Objects for Mobile-Manipulation
Nov 07, 2024


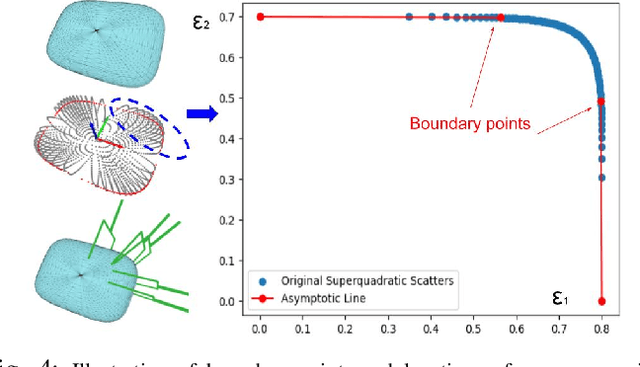
Grasp planning and estimation have been a longstanding research problem in robotics, with two main approaches to find graspable poses on the objects: 1) geometric approach, which relies on 3D models of objects and the gripper to estimate valid grasp poses, and 2) data-driven, learning-based approach, with models trained to identify grasp poses from raw sensor observations. The latter assumes comprehensive geometric coverage during the training phase. However, the data-driven approach is typically biased toward tabletop scenarios and struggle to generalize to out-of-distribution scenarios with larger objects (e.g. chair). Additionally, raw sensor data (e.g. RGB-D data) from a single view of these larger objects is often incomplete and necessitates additional observations. In this paper, we take a geometric approach, leveraging advancements in object modeling (e.g. NeRF) to build an implicit model by taking RGB images from views around the target object. This model enables the extraction of explicit mesh model while also capturing the visual appearance from novel viewpoints that is useful for perception tasks like object detection and pose estimation. We further decompose the NeRF-reconstructed 3D mesh into superquadrics (SQs) -- parametric geometric primitives, each mapped to a set of precomputed grasp poses, allowing grasp composition on the target object based on these primitives. Our proposed pipeline overcomes the problems: a) noisy depth and incomplete view of the object, with a modeling step, and b) generalization to objects of any size. For more qualitative results, refer to the supplementary video and webpage https://bit.ly/3ZrOanU
AugInsert: Learning Robust Visual-Force Policies via Data Augmentation for Object Assembly Tasks
Oct 19, 2024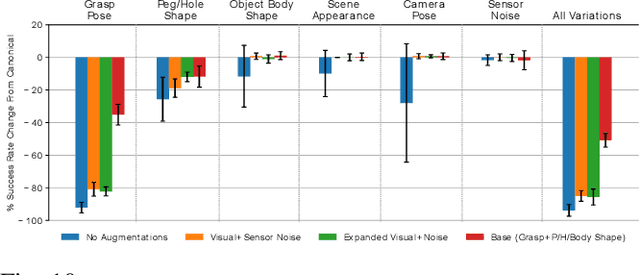
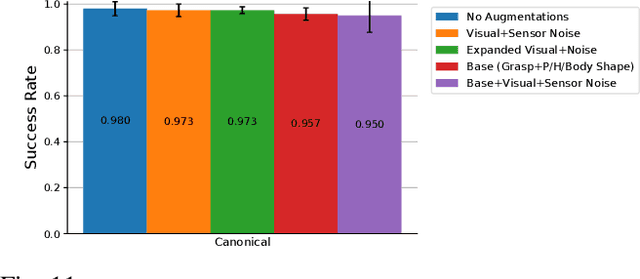
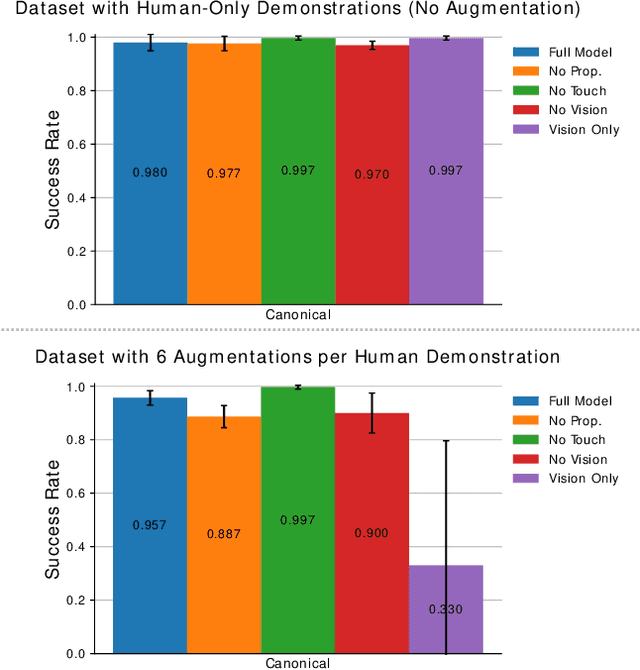

This paper primarily focuses on learning robust visual-force policies in the context of high-precision object assembly tasks. Specifically, we focus on the contact phase of the assembly task where both objects (peg and hole) have made contact and the objective lies in maneuvering the objects to complete the assembly. Moreover, we aim to learn contact-rich manipulation policies with multisensory inputs on limited expert data by expanding human demonstrations via online data augmentation. We develop a simulation environment with a dual-arm robot manipulator to evaluate the effect of augmented expert demonstration data. Our focus is on evaluating the robustness of our model with respect to certain task variations: grasp pose, peg/hole shape, object body shape, scene appearance, camera pose, and force-torque/proprioception noise. We show that our proposed data augmentation method helps in learning a multisensory manipulation policy that is robust to unseen instances of these variations, particularly physical variations such as grasp pose. Additionally, our ablative studies show the significant contribution of force-torque data to the robustness of our model. For additional experiments and qualitative results, we refer to the project webpage at https://bit.ly/47skWXH .
Talk Through It: End User Directed Manipulation Learning
Feb 19, 2024



Training generalist robot agents is an immensely difficult feat due to the requirement to perform a huge range of tasks in many different environments. We propose selectively training robots based on end-user preferences instead. Given a factory model that lets an end user instruct a robot to perform lower-level actions (e.g. 'Move left'), we show that end users can collect demonstrations using language to train their home model for higher-level tasks specific to their needs (e.g. 'Open the top drawer and put the block inside'). We demonstrate this hierarchical robot learning framework on robot manipulation tasks using RLBench environments. Our method results in a 16% improvement in skill success rates compared to a baseline method. In further experiments, we explore the use of the large vision-language model (VLM), Bard, to automatically break down tasks into sequences of lower-level instructions, aiming to bypass end-user involvement. The VLM is unable to break tasks down to our lowest level, but does achieve good results breaking high-level tasks into mid-level skills. We have a supplemental video and additional results at talk-through-it.github.io.
Evaluating Robustness of Visual Representations for Object Assembly Task Requiring Spatio-Geometrical Reasoning
Oct 22, 2023



This paper primarily focuses on evaluating and benchmarking the robustness of visual representations in the context of object assembly tasks. Specifically, it investigates the alignment and insertion of objects with geometrical extrusions and intrusions, commonly referred to as a peg-in-hole task. The accuracy required to detect and orient the peg and the hole geometry in SE(3) space for successful assembly poses significant challenges. Addressing this, we employ a general framework in visuomotor policy learning that utilizes visual pretraining models as vision encoders. Our study investigates the robustness of this framework when applied to a dual-arm manipulation setup, specifically to the grasp variations. Our quantitative analysis shows that existing pretrained models fail to capture the essential visual features necessary for this task. However, a visual encoder trained from scratch consistently outperforms the frozen pretrained models. Moreover, we discuss rotation representations and associated loss functions that substantially improve policy learning. We present a novel task scenario designed to evaluate the progress in visuomotor policy learning, with a specific focus on improving the robustness of intricate assembly tasks that require both geometrical and spatial reasoning. Videos, additional experiments, dataset, and code are available at https://bit.ly/geometric-peg-in-hole .
SlotGNN: Unsupervised Discovery of Multi-Object Representations and Visual Dynamics
Oct 06, 2023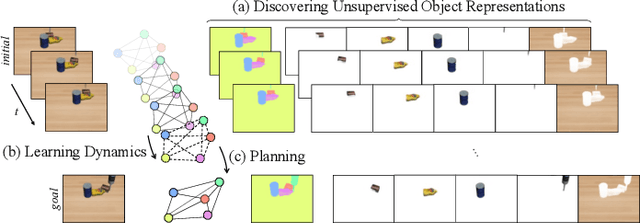

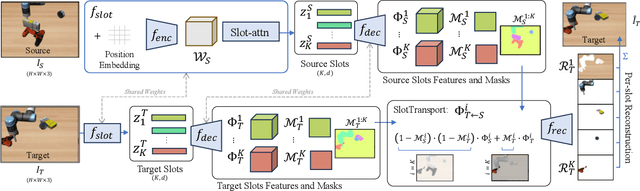
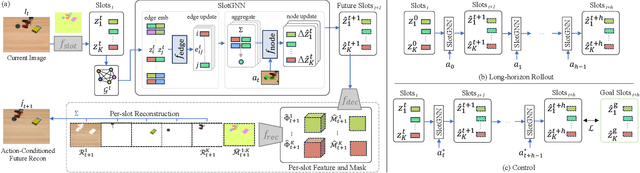
Learning multi-object dynamics from visual data using unsupervised techniques is challenging due to the need for robust, object representations that can be learned through robot interactions. This paper presents a novel framework with two new architectures: SlotTransport for discovering object representations from RGB images and SlotGNN for predicting their collective dynamics from RGB images and robot interactions. Our SlotTransport architecture is based on slot attention for unsupervised object discovery and uses a feature transport mechanism to maintain temporal alignment in object-centric representations. This enables the discovery of slots that consistently reflect the composition of multi-object scenes. These slots robustly bind to distinct objects, even under heavy occlusion or absence. Our SlotGNN, a novel unsupervised graph-based dynamics model, predicts the future state of multi-object scenes. SlotGNN learns a graph representation of the scene using the discovered slots from SlotTransport and performs relational and spatial reasoning to predict the future appearance of each slot conditioned on robot actions. We demonstrate the effectiveness of SlotTransport in learning object-centric features that accurately encode both visual and positional information. Further, we highlight the accuracy of SlotGNN in downstream robotic tasks, including challenging multi-object rearrangement and long-horizon prediction. Finally, our unsupervised approach proves effective in the real world. With only minimal additional data, our framework robustly predicts slots and their corresponding dynamics in real-world control tasks.
DNBP: Differentiable Nonparametric Belief Propagation
Mar 08, 2023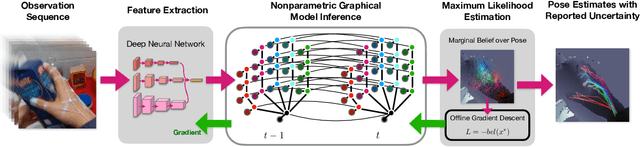
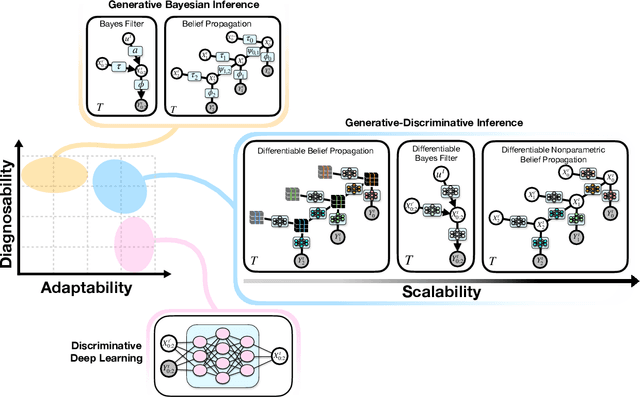
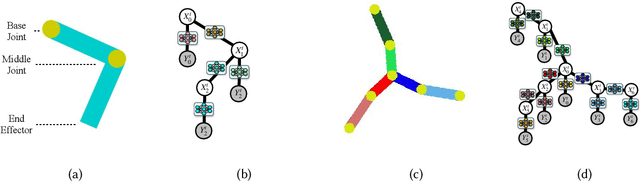
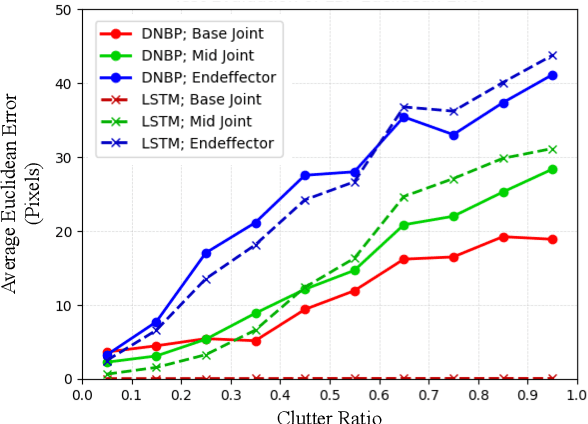
We present a differentiable approach to learn the probabilistic factors used for inference by a nonparametric belief propagation algorithm. Existing nonparametric belief propagation methods rely on domain-specific features encoded in the probabilistic factors of a graphical model. In this work, we replace each crafted factor with a differentiable neural network enabling the factors to be learned using an efficient optimization routine from labeled data. By combining differentiable neural networks with an efficient belief propagation algorithm, our method learns to maintain a set of marginal posterior samples using end-to-end training. We evaluate our differentiable nonparametric belief propagation (DNBP) method on a set of articulated pose tracking tasks and compare performance with learned baselines. Results from these experiments demonstrate the effectiveness of using learned factors for tracking and suggest the practical advantage over hand-crafted approaches. The project webpage is available at: https://progress.eecs.umich.edu/projects/dnbp/ .
Break and Make: Interactive Structural Understanding Using LEGO Bricks
Jul 27, 2022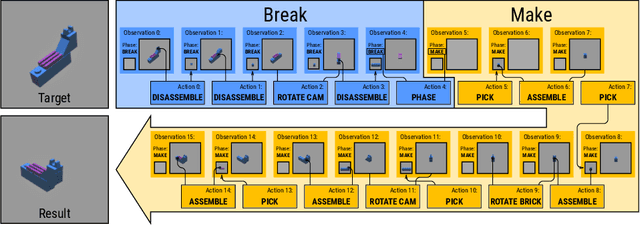
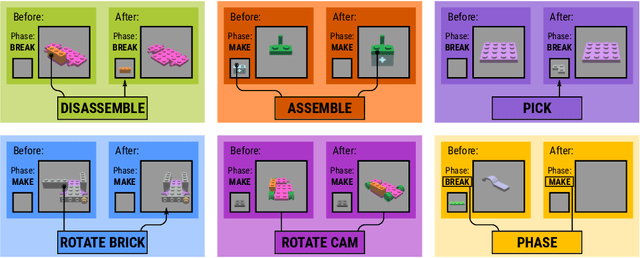
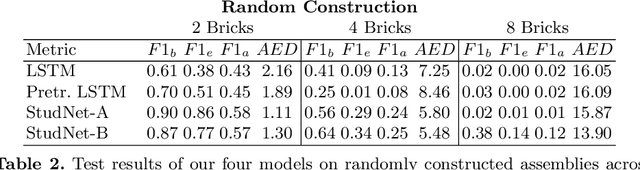
Visual understanding of geometric structures with complex spatial relationships is a fundamental component of human intelligence. As children, we learn how to reason about structure not only from observation, but also by interacting with the world around us -- by taking things apart and putting them back together again. The ability to reason about structure and compositionality allows us to not only build things, but also understand and reverse-engineer complex systems. In order to advance research in interactive reasoning for part-based geometric understanding, we propose a challenging new assembly problem using LEGO bricks that we call Break and Make. In this problem an agent is given a LEGO model and attempts to understand its structure by interactively inspecting and disassembling it. After this inspection period, the agent must then prove its understanding by rebuilding the model from scratch using low-level action primitives. In order to facilitate research on this problem we have built LTRON, a fully interactive 3D simulator that allows learning agents to assemble, disassemble and manipulate LEGO models. We pair this simulator with a new dataset of fan-made LEGO creations that have been uploaded to the internet in order to provide complex scenes containing over a thousand unique brick shapes. We take a first step towards solving this problem using sequence-to-sequence models that provide guidance for how to make progress on this challenging problem. Our simulator and data are available at github.com/aaronwalsman/ltron. Additional training code and PyTorch examples are available at github.com/aaronwalsman/ltron-torch-eccv22.
SORNet: Spatial Object-Centric Representations for Sequential Manipulation
Sep 08, 2021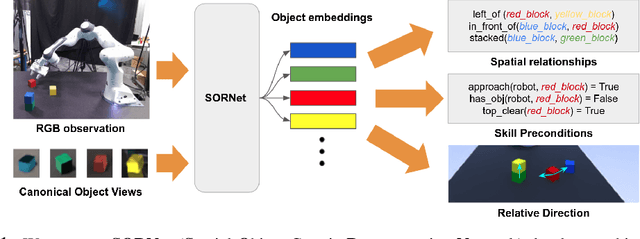

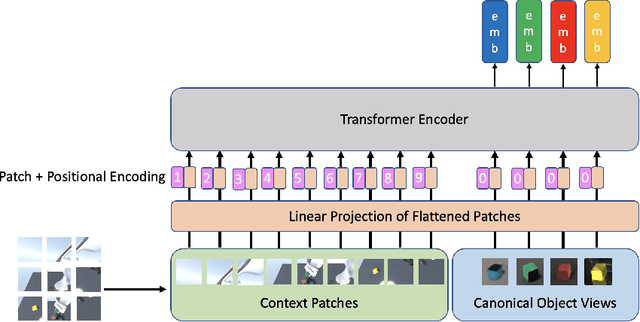
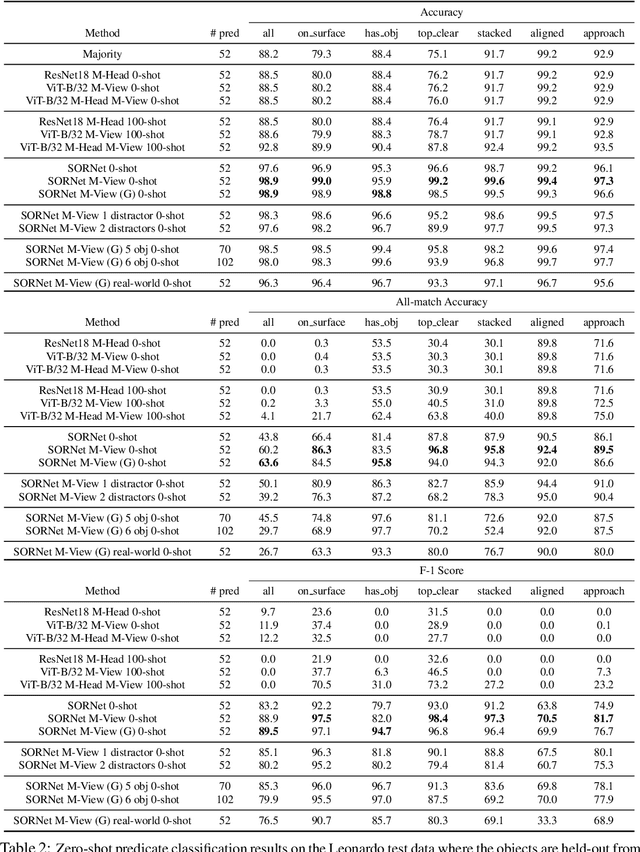
Sequential manipulation tasks require a robot to perceive the state of an environment and plan a sequence of actions leading to a desired goal state, where the ability to reason about spatial relationships among object entities from raw sensor inputs is crucial. Prior works relying on explicit state estimation or end-to-end learning struggle with novel objects. In this work, we propose SORNet (Spatial Object-Centric Representation Network), which extracts object-centric representations from RGB images conditioned on canonical views of the objects of interest. We show that the object embeddings learned by SORNet generalize zero-shot to unseen object entities on three spatial reasoning tasks: spatial relationship classification, skill precondition classification and relative direction regression, significantly outperforming baselines. Further, we present real-world robotic experiments demonstrating the usage of the learned object embeddings in task planning for sequential manipulation.