 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAGLE: Episodic Appearance- and Geometry-aware Memory for Unified 2D-3D Visual Query Localization in Egocentric Vision
Nov 12, 2025Egocentric visual query localization is vital for embodied AI and VR/AR, yet remains challenging due to camera motion, viewpoint changes, and appearance variations. We present EAGLE, a novel framework that leverages episodic appearance- and geometry-aware memory to achieve unified 2D-3D visual query localization in egocentric vision. Inspired by avian memory consolidation, EAGLE synergistically integrates segmentation guided by an appearance-aware meta-learning memory (AMM), with tracking driven by a geometry-aware localization memory (GLM). This memory consolidation mechanism, through structured appearance and geometry memory banks, stores high-confidence retrieval samples, effectively supporting both long- and short-term modeling of target appearance variations. This enables precise contour delineation with robust spatial discrimination, leading to significantly improved retrieval accuracy. Furthermore, by integrating the VQL-2D output with a visual geometry grounded Transformer (VGGT), we achieve a efficient unification of 2D and 3D tasks, enabling rapid and accurate back-projection into 3D space. Our method achieves state-ofthe-art performance on the Ego4D-VQ benchmark.
SuperQ-GRASP: Superquadrics-based Grasp Pose Estimation on Larger Objects for Mobile-Manipulation
Nov 07, 2024


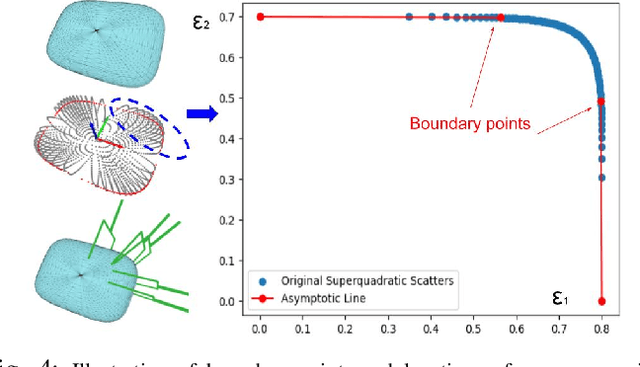
Grasp planning and estimation have been a longstanding research problem in robotics, with two main approaches to find graspable poses on the objects: 1) geometric approach, which relies on 3D models of objects and the gripper to estimate valid grasp poses, and 2) data-driven, learning-based approach, with models trained to identify grasp poses from raw sensor observations. The latter assumes comprehensive geometric coverage during the training phase. However, the data-driven approach is typically biased toward tabletop scenarios and struggle to generalize to out-of-distribution scenarios with larger objects (e.g. chair). Additionally, raw sensor data (e.g. RGB-D data) from a single view of these larger objects is often incomplete and necessitates additional observations. In this paper, we take a geometric approach, leveraging advancements in object modeling (e.g. NeRF) to build an implicit model by taking RGB images from views around the target object. This model enables the extraction of explicit mesh model while also capturing the visual appearance from novel viewpoints that is useful for perception tasks like object detection and pose estimation. We further decompose the NeRF-reconstructed 3D mesh into superquadrics (SQs) -- parametric geometric primitives, each mapped to a set of precomputed grasp poses, allowing grasp composition on the target object based on these primitives. Our proposed pipeline overcomes the problems: a) noisy depth and incomplete view of the object, with a modeling step, and b) generalization to objects of any size. For more qualitative results, refer to the supplementary video and webpage https://bit.ly/3ZrOanU