 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic-Regularized Verifier Elicits Reasoning from LLMs
May 07, 2026Verifiers are crucial components for enhancing modern LLMs' reasoning capability. Typicalverifiers require resource-intensive superviseddataset construction, which is costly and faceslimitations in data diversity. In this paper, wepropose LOVER, an unsupervised verifier regularized by logical rules. LOVER treats theverifier as a binary latent variable, utilizinginternal activations and enforcing three logical constraints on multiple reasoning paths:negation consistency, intra-group consistency,and inter-group consistency (grouped by thefinal answer). By incorporating logical rulesas priors, LOVER can leverage unlabeled examples and is directly compatible with any offthe-shelf LLMs. Experiments on 10 datasetsdemonstrate that LOVER significantly outperforms unsupervised baselines, achieving performance comparable to the supervised verifier(reaching its 95% level on average). The sourcecode is publicly available at https://github.com/wangxinyufighting/llm-lover.
STMI: Segmentation-Guided Token Modulation with Cross-Modal Hypergraph Interaction for Multi-Modal Object Re-Identification
Feb 28, 2026Multi-modal object Re-Identification (ReID) aims to exploit complementary information from different modalities to retrieve specific objects. However, existing methods often rely on hard token filtering or simple fusion strategies, which can lead to the loss of discriminative cues and increased background interference. To address these challenges, we propose STMI, a novel multi-modal learning framework consisting of three key components: (1) Segmentation-Guided Feature Modulation (SFM) module leverages SAM-generated masks to enhance foreground representations and suppress background noise through learnable attention modulation; (2) Semantic Token Reallocation (STR) module employs learnable query tokens and an adaptive reallocation mechanism to extract compact and informative representations without discarding any tokens; (3) Cross-Modal Hypergraph Interaction (CHI) module constructs a unified hypergraph across modalities to capture high-order semantic relationships. Extensive experiments on public benchmarks (i.e., RGBNT201, RGBNT100, and MSVR310) demonstrate the effectiveness and robustness of our proposed STMI framework in multi-modal ReID scenarios.
Beyond Heuristics: A Decision-Theoretic Framework for Agent Memory Management
Dec 25, 2025External memory is a key component of modern large language model (LLM) systems, enabling long-term interaction and personalization. Despite its importance, memory management is still largely driven by hand-designed heuristics, offering little insight into the long-term and uncertain consequences of memory decisions. In practice, choices about what to read or write shape future retrieval and downstream behavior in ways that are difficult to anticipate. We argue that memory management should be viewed as a sequential decision-making problem under uncertainty, where the utility of memory is delayed and dependent on future interactions. To this end, we propose DAM (Decision-theoretic Agent Memory), a decision-theoretic framework that decomposes memory management into immediate information access and hierarchical storage maintenance. Within this architecture, candidate operations are evaluated via value functions and uncertainty estimators, enabling an aggregate policy to arbitrate decisions based on estimated long-term utility and risk. Our contribution is not a new algorithm, but a principled reframing that clarifies the limitations of heuristic approaches and provides a foundation for future research on uncertainty-aware memory systems.
Codebook-Centric Deep Hashing: End-to-End Joint Learning of Semantic Hash Centers and Neural Hash Function
Nov 15, 2025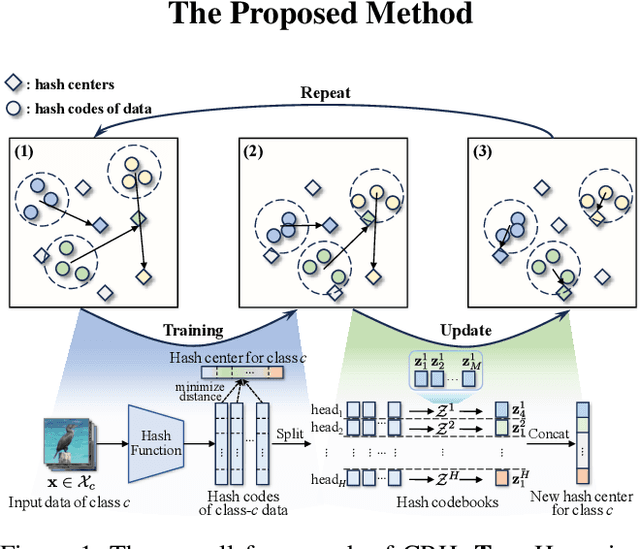
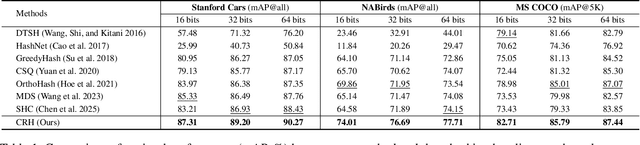

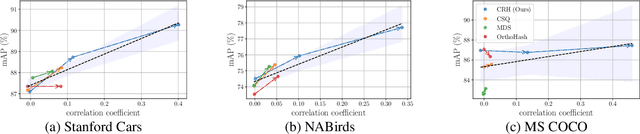
Hash center-based deep hashing methods improve upon pairwise or triplet-based approaches by assigning fixed hash centers to each class as learning targets, thereby avoiding the inefficiency of local similarity optimization. However, random center initialization often disregards inter-class semantic relationships. While existing two-stage methods mitigate this by first refining hash centers with semantics and then training the hash function, they introduce additional complexity, computational overhead, and suboptimal performance due to stage-wise discrepancies. To address these limitations, we propose $\textbf{Center-Reassigned Hashing (CRH)}$, an end-to-end framework that $\textbf{dynamically reassigns hash centers}$ from a preset codebook while jointly optimizing the hash function. Unlike previous methods, CRH adapts hash centers to the data distribution $\textbf{without explicit center optimization phases}$, enabling seamless integration of semantic relationships into the learning process. Furthermore, $\textbf{a multi-head mechanism}$ enhances the representational capacity of hash centers, capturing richer semantic structures. Extensive experiments on three benchmarks demonstrate that CRH learns semantically meaningful hash centers and outperforms state-of-the-art deep hashing methods in retrieval tasks.
Decoupling the Image Perception and Multimodal Reasoning for Reasoning Segmentation with Digital Twin Representations
Jun 09, 2025



Reasoning Segmentation (RS) is a multimodal vision-text task that requires segmenting objects based on implicit text queries, demanding both precise visual perception and vision-text reasoning capabilities. Current RS approaches rely on fine-tuning vision-language models (VLMs) for both perception and reasoning, but their tokenization of images fundamentally disrupts continuous spatial relationships between objects. We introduce DTwinSeger, a novel RS approach that leverages Digital Twin (DT) representation as an intermediate layer to decouple perception from reasoning. Innovatively, DTwinSeger reformulates RS as a two-stage process, where the first transforms the image into a structured DT representation that preserves spatial relationships and semantic properties and then employs a Large Language Model (LLM) to perform explicit reasoning over this representation to identify target objects. We propose a supervised fine-tuning method specifically for LLM with DT representation, together with a corresponding fine-tuning dataset Seg-DT, to enhance the LLM's reasoning capabilities with DT representations. Experiments show that our method can achieve state-of-the-art performance on two image RS benchmarks and three image referring segmentation benchmarks. It yields that DT representation functions as an effective bridge between vision and text, enabling complex multimodal reasoning tasks to be accomplished solely with an LLM.
SmartFreeEdit: Mask-Free Spatial-Aware Image Editing with Complex Instruction Understanding
Apr 17, 2025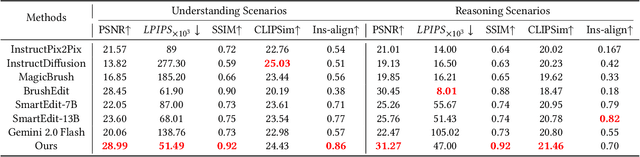

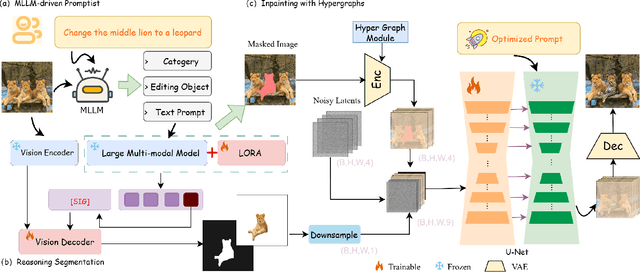
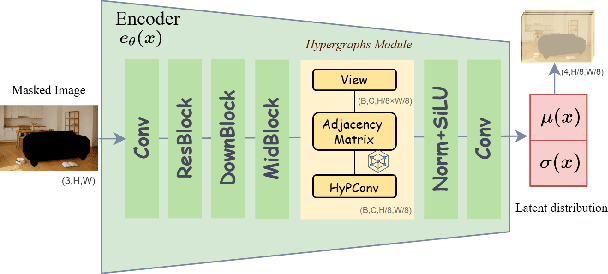
Recent advancements in image editing have utilized large-scale multimodal models to enable intuitive, natural instruction-driven interactions. However, conventional methods still face significant challenges, particularly in spatial reasoning, precise region segmentation, and maintaining semantic consistency, especially in complex scenes. To overcome these challenges, we introduce SmartFreeEdit, a novel end-to-end framework that integrates a multimodal large language model (MLLM) with a hypergraph-enhanced inpainting architecture, enabling precise, mask-free image editing guided exclusively by natural language instructions. The key innovations of SmartFreeEdit include:(1)the introduction of region aware tokens and a mask embedding paradigm that enhance the spatial understanding of complex scenes;(2) a reasoning segmentation pipeline designed to optimize the generation of editing masks based on natural language instructions;and (3) a hypergraph-augmented inpainting module that ensures the preservation of both structural integrity and semantic coherence during complex edits, overcoming the limitations of local-based image generation. Extensive experiments on the Reason-Edit benchmark demonstrate that SmartFreeEdit surpasses current state-of-the-art methods across multiple evaluation metrics, including segmentation accuracy, instruction adherence, and visual quality preservation, while addressing the issue of local information focus and improving global consistency in the edited image. Our project will be available at https://github.com/smileformylove/SmartFreeEdit.
Multi-Label Out-of-Distribution Detection with Spectral Normalized Joint Energy
May 08, 2024

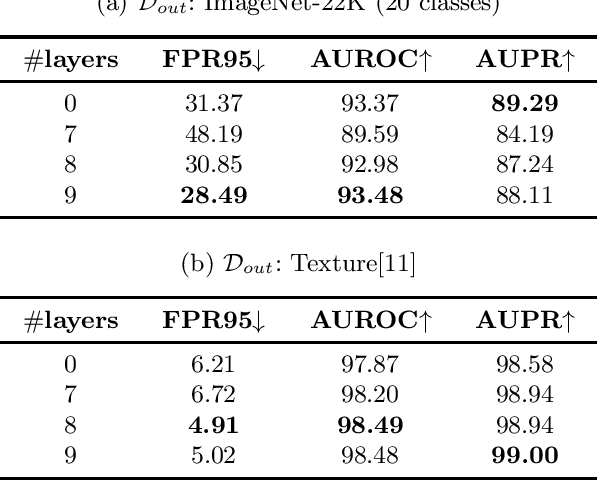
In today's interconnected world, achieving reliable out-of-distribution (OOD) detection poses a significant challenge for machine learning models. While numerous studies have introduced improved approaches for multi-class OOD detection tasks, the investigation into multi-label OOD detection tasks has been notably limited. We introduce Spectral Normalized Joint Energy (SNoJoE), a method that consolidates label-specific information across multiple labels through the theoretically justified concept of an energy-based function. Throughout the training process, we employ spectral normalization to manage the model's feature space, thereby enhancing model efficacy and generalization, in addition to bolstering robustness. Our findings indicate that the application of spectral normalization to joint energy scores notably amplifies the model's capability for OOD detection. We perform OOD detection experiments utilizing PASCAL-VOC as the in-distribution dataset and ImageNet-22K or Texture as the out-of-distribution datasets. Our experimental results reveal that, in comparison to prior top performances, SNoJoE achieves 11% and 54% relative reductions in FPR95 on the respective OOD datasets, thereby defining the new state of the art in this field of study.
Would You Trust an AI Doctor? Building Reliable Medical Predictions with Kernel Dropout Uncertainty
Apr 16, 2024

The growing capabilities of AI raise questions about their trustworthiness in healthcare, particularly due to opaque decision-making and limited data availability. This paper proposes a novel approach to address these challenges, introducing a Bayesian Monte Carlo Dropout model with kernel modelling. Our model is designed to enhance reliability on small medical datasets, a crucial barrier to the wider adoption of AI in healthcare. This model leverages existing language models for improved effectiveness and seamlessly integrates with current workflows. We demonstrate significant improvements in reliability, even with limited data, offering a promising step towards building trust in AI-driven medical predictions and unlocking its potential to improve patient care.
BayesJudge: Bayesian Kernel Language Modelling with Confidence Uncertainty in Legal Judgment Prediction
Apr 16, 2024
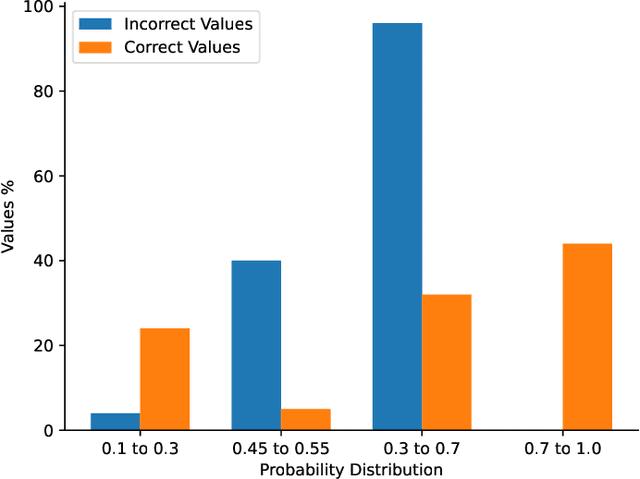


Predicting legal judgments with reliable confidence is paramount for responsible legal AI applications. While transformer-based deep neural networks (DNNs) like BERT have demonstrated promise in legal tasks, accurately assessing their prediction confidence remains crucial. We present a novel Bayesian approach called BayesJudge that harnesses the synergy between deep learning and deep Gaussian Processes to quantify uncertainty through Bayesian kernel Monte Carlo dropout. Our method leverages informative priors and flexible data modelling via kernels, surpassing existing methods in both predictive accuracy and confidence estimation as indicated through brier score. Extensive evaluations of public legal datasets showcase our model's superior performance across diverse tasks. We also introduce an optimal solution to automate the scrutiny of unreliable predictions, resulting in a significant increase in the accuracy of the model's predictions by up to 27\%. By empowering judges and legal professionals with more reliable information, our work paves the way for trustworthy and transparent legal AI applications that facilitate informed decisions grounded in both knowledge and quantified uncertainty.
Context-Aware Classification of Legal Document Pages
Apr 25, 2023



For many business applications that require the processing, indexing, and retrieval of professional documents such as legal briefs (in PDF format etc.), it is often essential to classify the pages of any given document into their corresponding types beforehand. Most existing studies in the field of document image classification either focus on single-page documents or treat multiple pages in a document independently. Although in recent years a few techniques have been proposed to exploit the context information from neighboring pages to enhance document page classification, they typically cannot be utilized with large pre-trained language models due to the constraint on input length. In this paper, we present a simple but effective approach that overcomes the above limitation. Specifically, we enhance the input with extra tokens carrying sequential information about previous pages - introducing recurrence - which enables the usage of pre-trained Transformer models like BERT for context-aware page classification. Our experiments conducted on two legal datasets in English and Portuguese respectively show that the proposed approach can significantly improve the performance of document page classification compared to the non-recurrent setup as well as the other context-aware baselines.