 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph-Assisted LLM Post-Training for Enhanced Legal Reasoning
Jan 20, 2026LLM post-training has primarily relied on large text corpora and human feedback, without capturing the structure of domain knowledge. This has caused models to struggle dealing with complex reasoning tasks, especially for high-stakes professional domains. In Law, reasoning requires deep understanding of the relations between various legal concepts, a key component missing in current LLM post-training. In this paper, we propose a knowledge graph (KG)-assisted approach for enhancing LLMs' reasoning capability in Legal that is generalizable to other high-stakes domains. We model key legal concepts by following the \textbf{IRAC} (Issue, Rule, Analysis and Conclusion) framework, and construct a KG with 12K legal cases. We then produce training data using our IRAC KG, and conduct both Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) with three state-of-the-art (SOTA) LLMs (30B, 49B and 70B), varying architecture and base model family. Our post-trained models obtained better average performance on 4/5 diverse legal benchmarks (14 tasks) than baselines. In particular, our 70B DPO model achieved the best score on 4/6 reasoning tasks, among baselines and a 141B SOTA legal LLM, demonstrating the effectiveness of our KG for enhancing LLMs' legal reasoning capability.
Beyond Pointwise Scores: Decomposed Criteria-Based Evaluation of LLM Responses
Sep 19, 2025Evaluating long-form answers in high-stakes domains such as law or medicine remains a fundamental challenge. Standard metrics like BLEU and ROUGE fail to capture semantic correctness, and current LLM-based evaluators often reduce nuanced aspects of answer quality into a single undifferentiated score. We introduce DeCE, a decomposed LLM evaluation framework that separates precision (factual accuracy and relevance) and recall (coverage of required concepts), using instance-specific criteria automatically extracted from gold answer requirements. DeCE is model-agnostic and domain-general, requiring no predefined taxonomies or handcrafted rubrics. We instantiate DeCE to evaluate different LLMs on a real-world legal QA task involving multi-jurisdictional reasoning and citation grounding. DeCE achieves substantially stronger correlation with expert judgments ($r=0.78$), compared to traditional metrics ($r=0.12$), pointwise LLM scoring ($r=0.35$), and modern multidimensional evaluators ($r=0.48$). It also reveals interpretable trade-offs: generalist models favor recall, while specialized models favor precision. Importantly, only 11.95% of LLM-generated criteria required expert revision, underscoring DeCE's scalability. DeCE offers an interpretable and actionable LLM evaluation framework in expert domains.
Making a Computational Attorney
Mar 07, 2023This "blue sky idea" paper outlines the opportunities and challenges in data mining and machine learning involving making a computational attorney -- an intelligent software agent capable of helping human lawyers with a wide range of complex high-level legal tasks such as drafting legal briefs for the prosecution or defense in court. In particular, we discuss what a ChatGPT-like Large Legal Language Model (L$^3$M) can and cannot do today, which will inspire researchers with promising short-term and long-term research objectives.
Legal Prompting: Teaching a Language Model to Think Like a Lawyer
Dec 08, 2022Large language models that are capable of zero or few-shot prompting approaches have given rise to the new research area of prompt engineering. Recent advances showed that for example Chain-of-Thought (CoT) prompts can improve arithmetic or common sense tasks significantly. We explore how such approaches fare with legal reasoning tasks and take the COLIEE entailment task based on the Japanese Bar exam for testing zero-shot/few-shot and fine-tuning approaches. Our findings show that while CoT prompting and fine-tuning with explanations approaches show improvements, the best results are produced by prompts that are derived from specific legal reasoning techniques such as IRAC (Issue, Rule, Application, Conclusion). Based on our experiments we improve the 2021 best result from 0.7037 accuracy to 0.8148 accuracy and beat the 2022 best system of 0.6789 accuracy with an accuracy of 0.7431.
TweetDrought: A Deep-Learning Drought Impacts Recognizer based on Twitter Data
Dec 07, 2022

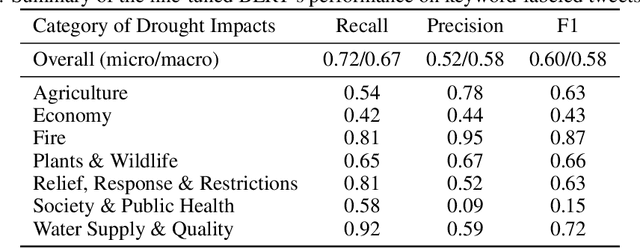

Acquiring a better understanding of drought impacts becomes increasingly vital under a warming climate. Traditional drought indices describe mainly biophysical variables and not impacts on social, economic, and environmental systems. We utilized natural language processing and bidirectional encoder representation from Transformers (BERT) based transfer learning to fine-tune the model on the data from the news-based Drought Impact Report (DIR) and then apply it to recognize seven types of drought impacts based on the filtered Twitter data from the United States. Our model achieved a satisfying macro-F1 score of 0.89 on the DIR test set. The model was then applied to California tweets and validated with keyword-based labels. The macro-F1 score was 0.58. However, due to the limitation of keywords, we also spot-checked tweets with controversial labels. 83.5% of BERT labels were correct compared to the keyword labels. Overall, the fine-tuned BERT-based recognizer provided proper predictions and valuable information on drought impacts. The interpretation and analysis of the model were consistent with experiential domain expertise.
Legal Prompt Engineering for Multilingual Legal Judgement Prediction
Dec 05, 2022Legal Prompt Engineering (LPE) or Legal Prompting is a process to guide and assist a large language model (LLM) with performing a natural legal language processing (NLLP) skill. Our goal is to use LPE with LLMs over long legal documents for the Legal Judgement Prediction (LJP) task. We investigate the performance of zero-shot LPE for given facts in case-texts from the European Court of Human Rights (in English) and the Federal Supreme Court of Switzerland (in German, French and Italian). Our results show that zero-shot LPE is better compared to the baselines, but it still falls short compared to current state of the art supervised approaches. Nevertheless, the results are important, since there was 1) no explicit domain-specific data used - so we show that the transfer to the legal domain is possible for general-purpose LLMs, and 2) the LLMs where directly applied without any further training or fine-tuning - which in turn saves immensely in terms of additional computational costs.