 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Groundedness of Legal Question-Answering Systems
Oct 11, 2024
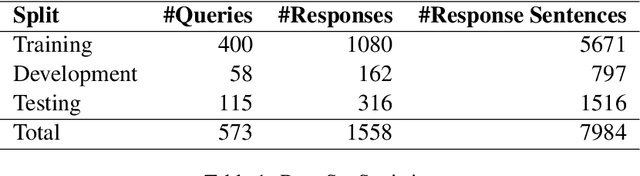
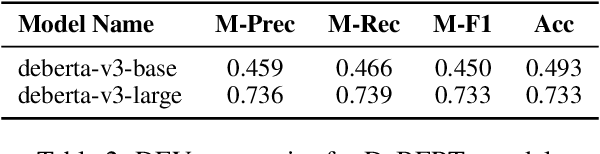
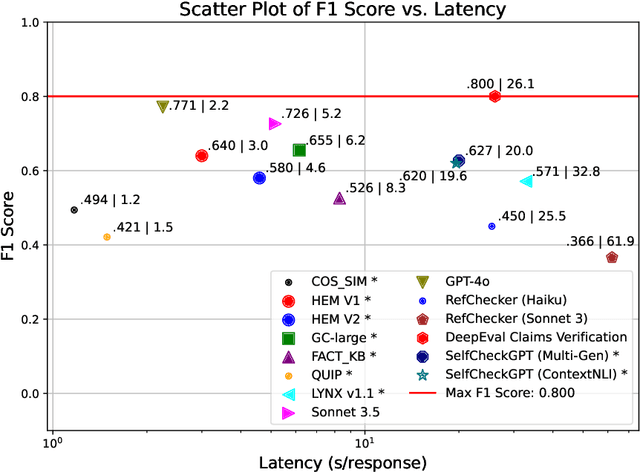
In high-stakes domains like legal question-answering, the accuracy and trustworthiness of generative AI systems are of paramount importance. This work presents a comprehensive benchmark of various methods to assess the groundedness of AI-generated responses, aiming to significantly enhance their reliability. Our experiments include similarity-based metrics and natural language inference models to evaluate whether responses are well-founded in the given contexts. We also explore different prompting strategies for large language models to improve the detection of ungrounded responses. We validated the effectiveness of these methods using a newly created grounding classification corpus, designed specifically for legal queries and corresponding responses from retrieval-augmented prompting, focusing on their alignment with source material. Our results indicate potential in groundedness classification of generated responses, with the best method achieving a macro-F1 score of 0.8. Additionally, we evaluated the methods in terms of their latency to determine their suitability for real-world applications, as this step typically follows the generation process. This capability is essential for processes that may trigger additional manual verification or automated response regeneration. In summary, this study demonstrates the potential of various detection methods to improve the trustworthiness of generative AI in legal settings.
Large Language Model Prompt Chaining for Long Legal Document Classification
Aug 08, 2023Prompting is used to guide or steer a language model in generating an appropriate response that is consistent with the desired outcome. Chaining is a strategy used to decompose complex tasks into smaller, manageable components. In this study, we utilize prompt chaining for extensive legal document classification tasks, which present difficulties due to their intricate domain-specific language and considerable length. Our approach begins with the creation of a concise summary of the original document, followed by a semantic search for related exemplar texts and their corresponding annotations from a training corpus. Finally, we prompt for a label - based on the task - to assign, by leveraging the in-context learning from the few-shot prompt. We demonstrate that through prompt chaining, we can not only enhance the performance over zero-shot, but also surpass the micro-F1 score achieved by larger models, such as ChatGPT zero-shot, using smaller models.
Legal Prompt Engineering for Multilingual Legal Judgement Prediction
Dec 05, 2022Legal Prompt Engineering (LPE) or Legal Prompting is a process to guide and assist a large language model (LLM) with performing a natural legal language processing (NLLP) skill. Our goal is to use LPE with LLMs over long legal documents for the Legal Judgement Prediction (LJP) task. We investigate the performance of zero-shot LPE for given facts in case-texts from the European Court of Human Rights (in English) and the Federal Supreme Court of Switzerland (in German, French and Italian). Our results show that zero-shot LPE is better compared to the baselines, but it still falls short compared to current state of the art supervised approaches. Nevertheless, the results are important, since there was 1) no explicit domain-specific data used - so we show that the transfer to the legal domain is possible for general-purpose LLMs, and 2) the LLMs where directly applied without any further training or fine-tuning - which in turn saves immensely in terms of additional computational costs.
Active Learning for Argument Mining: A Practical Approach
Sep 28, 2021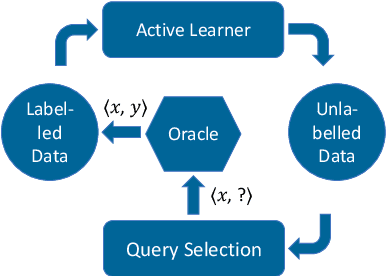
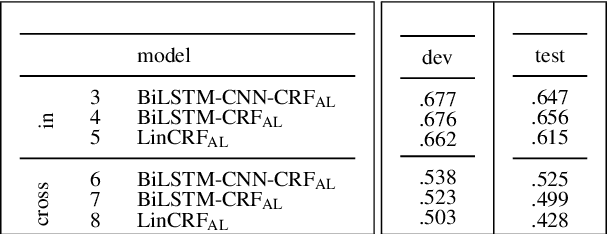
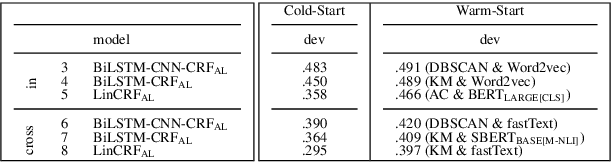
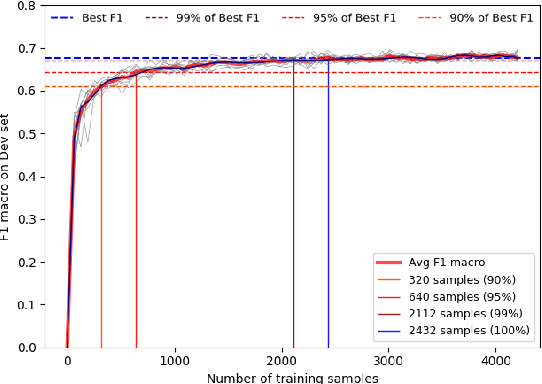
Despite considerable recent progress, the creation of well-balanced and diverse resources remains a time-consuming and costly challenge in Argument Mining. Active Learning reduces the amount of data necessary for the training of machine learning models by querying the most informative samples for annotation and therefore is a promising method for resource creation. In a large scale comparison of several Active Learning methods, we show that Active Learning considerably decreases the effort necessary to get good deep learning performance on the task of Argument Unit Recognition and Classification (AURC).
Aspect-Based Argument Mining
Nov 01, 2020

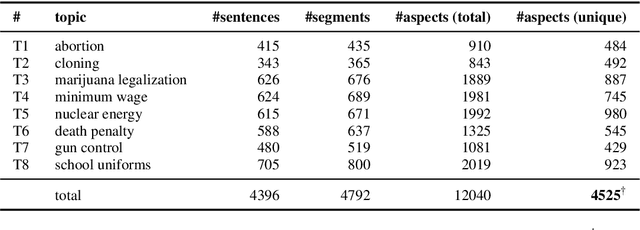

Computational Argumentation in general and Argument Mining in particular are important research fields. In previous works, many of the challenges to automatically extract and to some degree reason over natural language arguments were addressed. The tools to extract argument units are increasingly available and further open problems can be addressed. In this work, we are presenting the task of Aspect-Based Argument Mining (ABAM), with the essential subtasks of Aspect Term Extraction (ATE) and Nested Segmentation (NS). At the first instance, we create and release an annotated corpus with aspect information on the token-level. We consider aspects as the main point(s) argument units are addressing. This information is important for further downstream tasks such as argument ranking, argument summarization and generation, as well as the search for counter-arguments on the aspect-level. We present several experiments using state-of-the-art supervised architectures and demonstrate their performance for both of the subtasks. The annotated benchmark is available at https://github.com/trtm/ABAM.
Multipurpose Intelligent Process Automation via Conversational Assistant
Jan 07, 2020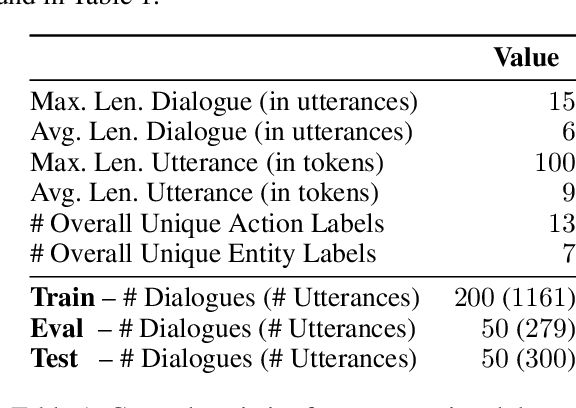

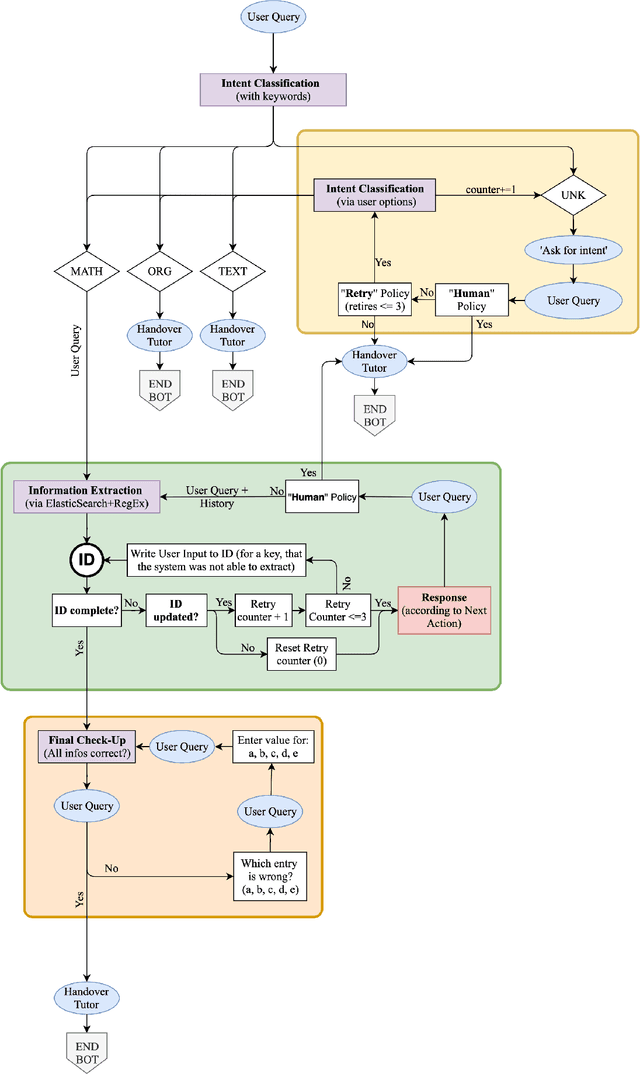
Intelligent Process Automation (IPA) is an emerging technology with a primary goal to assist the knowledge worker by taking care of repetitive, routine and low-cognitive tasks. Conversational agents that can interact with users in a natural language are potential application for IPA systems. Such intelligent agents can assist the user by answering specific questions and executing routine tasks that are ordinarily performed in a natural language (i.e., customer support). In this work, we tackle a challenge of implementing an IPA conversational assistant in a real-world industrial setting with a lack of structured training data. Our proposed system brings two significant benefits: First, it reduces repetitive and time-consuming activities and, therefore, allows workers to focus on more intelligent processes. Second, by interacting with users, it augments the resources with structured and to some extent labeled training data. We showcase the usage of the latter by re-implementing several components of our system with Transfer Learning (TL) methods.
Domain adaptation for part-of-speech tagging of noisy user-generated text
May 21, 2019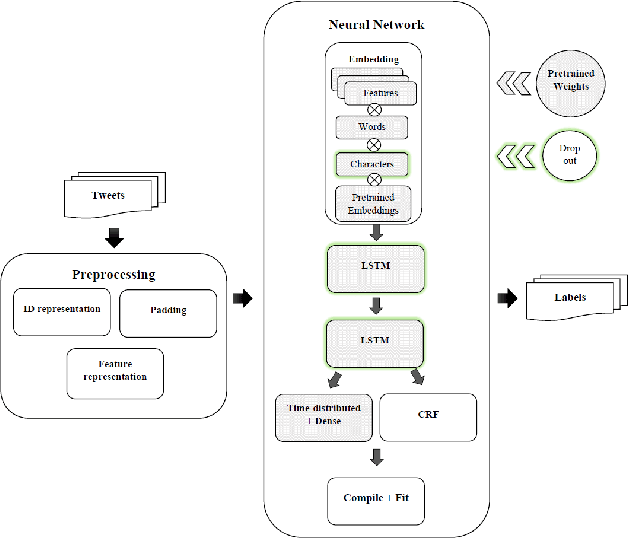
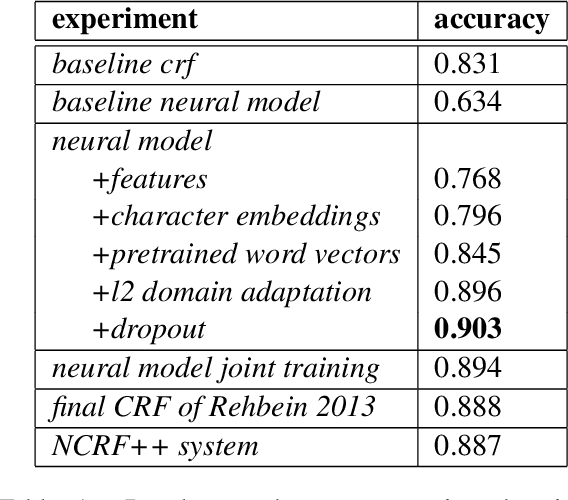
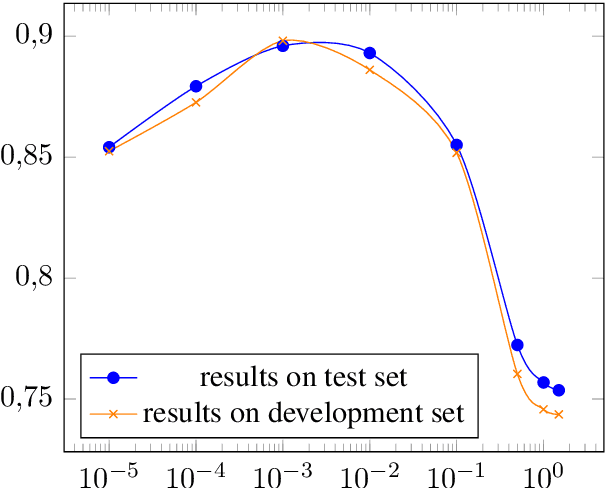
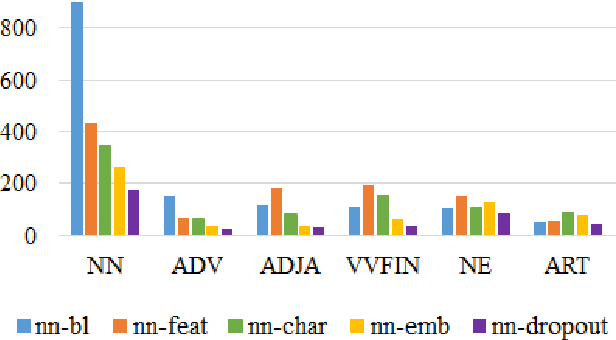
The performance of a Part-of-speech (POS) tagger is highly dependent on the domain ofthe processed text, and for many domains there is no or only very little training data available. This work addresses the problem of POS tagging noisy user-generated text using a neural network. We propose an architecture that trains an out-of-domain model on a large newswire corpus, and transfers those weights by using them as a prior for a model trained on the target domain (a data-set of German Tweets) for which there is very little an-notations available. The neural network has two standard bidirectional LSTMs at its core. However, we find it crucial to also encode a set of task-specific features, and to obtain reliable (source-domain and target-domain) word representations. Experiments with different regularization techniques such as early stopping, dropout and fine-tuning the domain adaptation prior weights are conducted. Our best model uses external weights from the out-of-domain model, as well as feature embeddings, pre-trained word and sub-word embeddings and achieves a tagging accuracy of slightly over 90%, improving on the previous state of the art for this task.
Robust Argument Unit Recognition and Classification
Apr 22, 2019
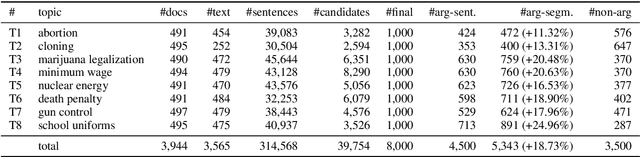
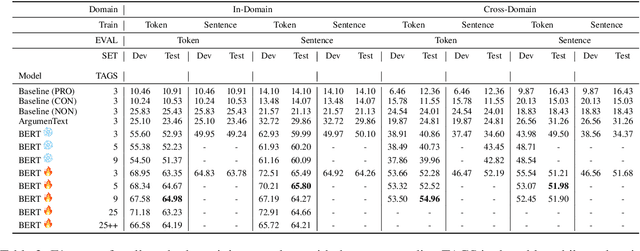
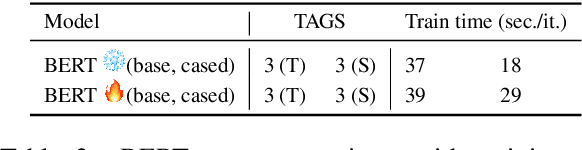
Argument mining is generally performed on the sentence-level -- it is assumed that an entire sentence (not parts of it) corresponds to an argument. In this paper, we introduce the new task of Argument unit Recognition and Classification (ARC). In ARC, an argument is generally a part of a sentence -- a more realistic assumption since several different arguments can occur in one sentence and longer sentences often contain a mix of argumentative and non-argumentative parts. Recognizing and classifying the spans that correspond to arguments makes ARC harder than previously defined argument mining tasks. We release ARC-8, a new benchmark for evaluating the ARC task. We show that token-level annotations for argument units can be gathered using scalable methods. ARC-8 contains 25\% more arguments than a dataset annotated on the sentence-level would. We cast ARC as a sequence labeling task, develop a number of methods for ARC sequence tagging and establish the state of the art for ARC-8. A focus of our work is robustness: both robustness against errors in sentence identification (which are frequent for noisy text) and robustness against divergence in training and test data.
Sequence Labeling: A Practical Approach
Aug 12, 2018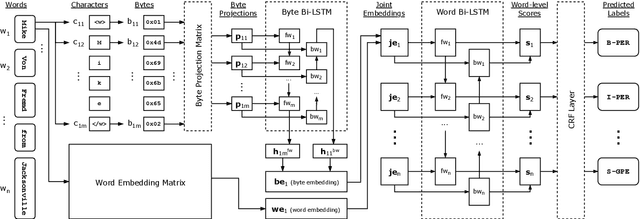
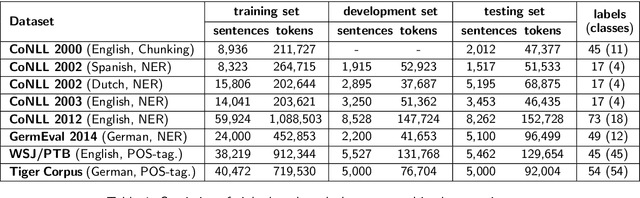
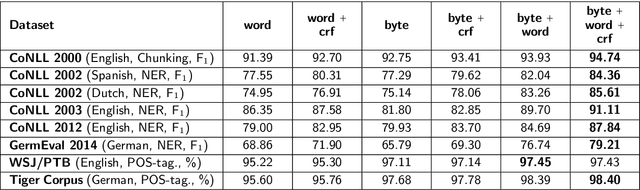
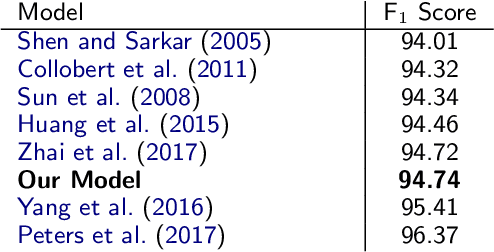
We take a practical approach to solving sequence labeling problem assuming unavailability of domain expertise and scarcity of informational and computational resources. To this end, we utilize a universal end-to-end Bi-LSTM-based neural sequence labeling model applicable to a wide range of NLP tasks and languages. The model combines morphological, semantic, and structural cues extracted from data to arrive at informed predictions. The model's performance is evaluated on eight benchmark datasets (covering three tasks: POS-tagging, NER, and Chunking, and four languages: English, German, Dutch, and Spanish). We observe state-of-the-art results on four of them: CoNLL-2012 (English NER), CoNLL-2002 (Dutch NER), GermEval 2014 (German NER), Tiger Corpus (German POS-tagging), and competitive performance on the rest.