 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikert or Not: LLM Absolute Relevance Judgments on Fine-Grained Ordinal Scales
May 25, 2025Large language models (LLMs) obtain state of the art zero shot relevance ranking performance on a variety of information retrieval tasks. The two most common prompts to elicit LLM relevance judgments are pointwise scoring (a.k.a. relevance generation), where the LLM sees a single query-document pair and outputs a single relevance score, and listwise ranking (a.k.a. permutation generation), where the LLM sees a query and a list of documents and outputs a permutation, sorting the documents in decreasing order of relevance. The current research community consensus is that listwise ranking yields superior performance, and significant research effort has been devoted to crafting LLM listwise ranking algorithms. The underlying hypothesis is that LLMs are better at making relative relevance judgments than absolute ones. In tension with this hypothesis, we find that the gap between pointwise scoring and listwise ranking shrinks when pointwise scoring is implemented using a sufficiently large ordinal relevance label space, becoming statistically insignificant for many LLM-benchmark dataset combinations (where ``significant'' means ``95\% confidence that listwise ranking improves NDCG@10''). Our evaluations span four LLMs, eight benchmark datasets from the BEIR and TREC-DL suites, and two proprietary datasets with relevance labels collected after the training cut-off of all LLMs evaluated.
Measuring the Groundedness of Legal Question-Answering Systems
Oct 11, 2024
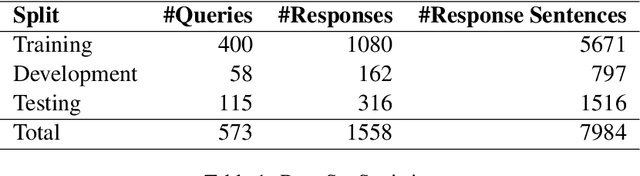
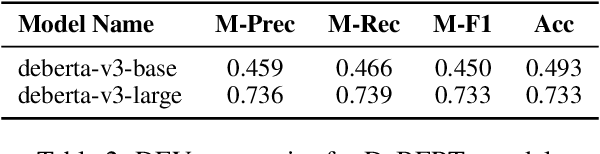
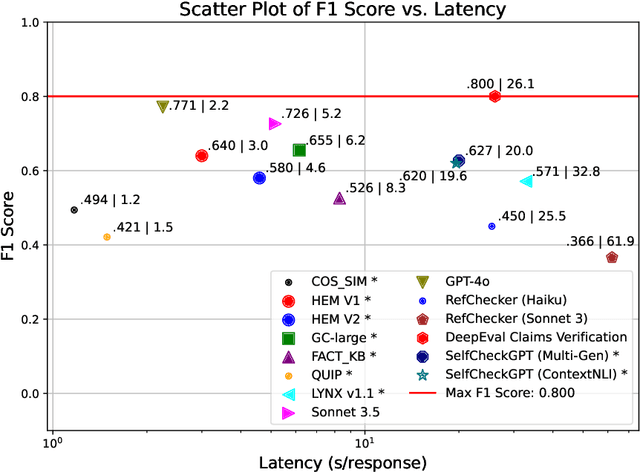
In high-stakes domains like legal question-answering, the accuracy and trustworthiness of generative AI systems are of paramount importance. This work presents a comprehensive benchmark of various methods to assess the groundedness of AI-generated responses, aiming to significantly enhance their reliability. Our experiments include similarity-based metrics and natural language inference models to evaluate whether responses are well-founded in the given contexts. We also explore different prompting strategies for large language models to improve the detection of ungrounded responses. We validated the effectiveness of these methods using a newly created grounding classification corpus, designed specifically for legal queries and corresponding responses from retrieval-augmented prompting, focusing on their alignment with source material. Our results indicate potential in groundedness classification of generated responses, with the best method achieving a macro-F1 score of 0.8. Additionally, we evaluated the methods in terms of their latency to determine their suitability for real-world applications, as this step typically follows the generation process. This capability is essential for processes that may trigger additional manual verification or automated response regeneration. In summary, this study demonstrates the potential of various detection methods to improve the trustworthiness of generative AI in legal settings.