 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Groundedness of Legal Question-Answering Systems
Oct 11, 2024
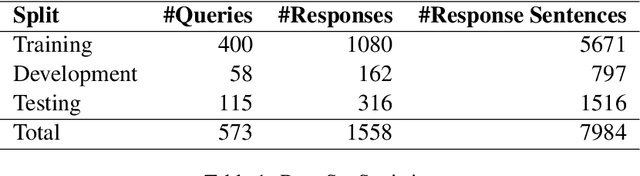
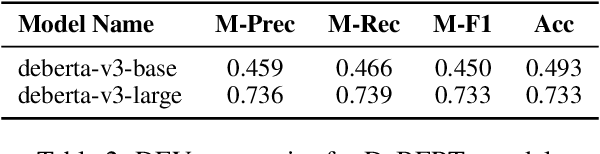
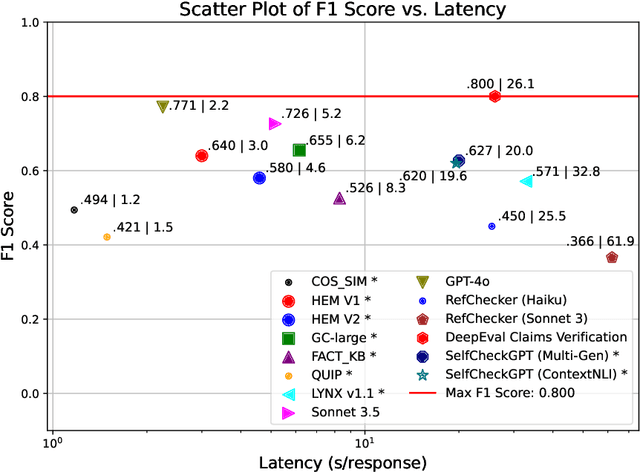
In high-stakes domains like legal question-answering, the accuracy and trustworthiness of generative AI systems are of paramount importance. This work presents a comprehensive benchmark of various methods to assess the groundedness of AI-generated responses, aiming to significantly enhance their reliability. Our experiments include similarity-based metrics and natural language inference models to evaluate whether responses are well-founded in the given contexts. We also explore different prompting strategies for large language models to improve the detection of ungrounded responses. We validated the effectiveness of these methods using a newly created grounding classification corpus, designed specifically for legal queries and corresponding responses from retrieval-augmented prompting, focusing on their alignment with source material. Our results indicate potential in groundedness classification of generated responses, with the best method achieving a macro-F1 score of 0.8. Additionally, we evaluated the methods in terms of their latency to determine their suitability for real-world applications, as this step typically follows the generation process. This capability is essential for processes that may trigger additional manual verification or automated response regeneration. In summary, this study demonstrates the potential of various detection methods to improve the trustworthiness of generative AI in legal settings.
ReviewQA: a relational aspect-based opinion reading dataset
Oct 29, 2018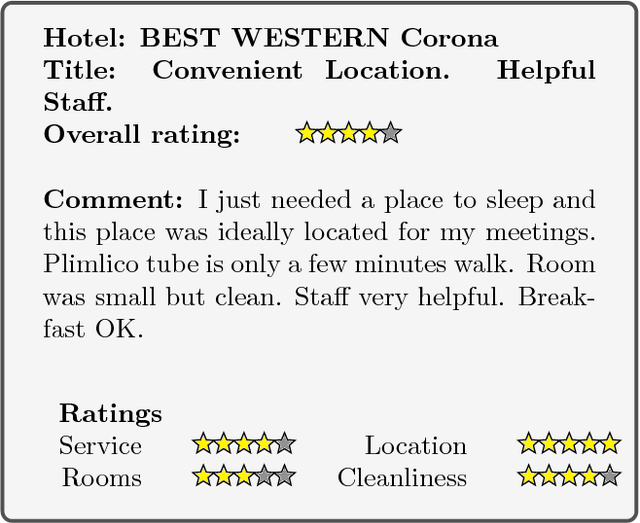
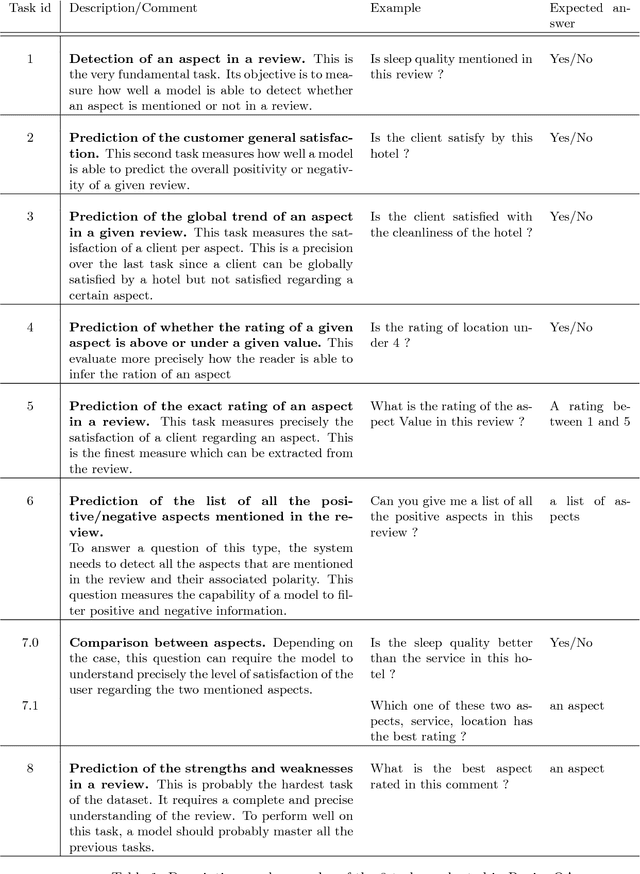
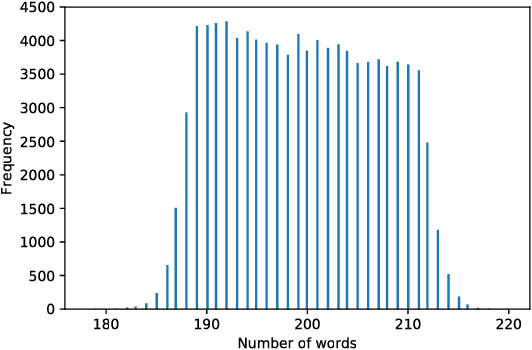
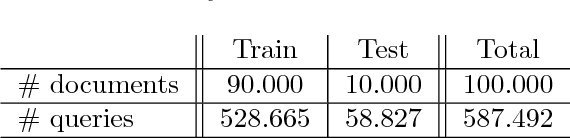
Deep reading models for question-answering have demonstrated promising performance over the last couple of years. However current systems tend to learn how to cleverly extract a span of the source document, based on its similarity with the question, instead of seeking for the appropriate answer. Indeed, a reading machine should be able to detect relevant passages in a document regarding a question, but more importantly, it should be able to reason over the important pieces of the document in order to produce an answer when it is required. To motivate this purpose, we present ReviewQA, a question-answering dataset based on hotel reviews. The questions of this dataset are linked to a set of relational understanding competencies that we expect a model to master. Indeed, each question comes with an associated type that characterizes the required competency. With this framework, it is possible to benchmark the main families of models and to get an overview of what are the strengths and the weaknesses of a given model on the set of tasks evaluated in this dataset. Our corpus contains more than 500.000 questions in natural language over 100.000 hotel reviews. Our setup is projective, the answer of a question does not need to be extracted from a document, like in most of the recent datasets, but selected among a set of candidates that contains all the possible answers to the questions of the dataset. Finally, we present several baselines over this dataset.