 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph-Assisted LLM Post-Training for Enhanced Legal Reasoning
Jan 20, 2026LLM post-training has primarily relied on large text corpora and human feedback, without capturing the structure of domain knowledge. This has caused models to struggle dealing with complex reasoning tasks, especially for high-stakes professional domains. In Law, reasoning requires deep understanding of the relations between various legal concepts, a key component missing in current LLM post-training. In this paper, we propose a knowledge graph (KG)-assisted approach for enhancing LLMs' reasoning capability in Legal that is generalizable to other high-stakes domains. We model key legal concepts by following the \textbf{IRAC} (Issue, Rule, Analysis and Conclusion) framework, and construct a KG with 12K legal cases. We then produce training data using our IRAC KG, and conduct both Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) with three state-of-the-art (SOTA) LLMs (30B, 49B and 70B), varying architecture and base model family. Our post-trained models obtained better average performance on 4/5 diverse legal benchmarks (14 tasks) than baselines. In particular, our 70B DPO model achieved the best score on 4/6 reasoning tasks, among baselines and a 141B SOTA legal LLM, demonstrating the effectiveness of our KG for enhancing LLMs' legal reasoning capability.
Measuring the Groundedness of Legal Question-Answering Systems
Oct 11, 2024
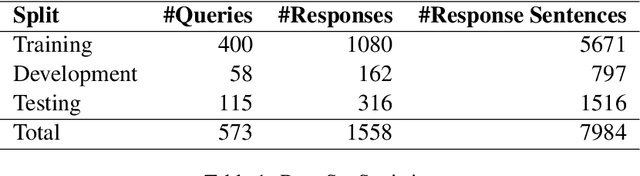
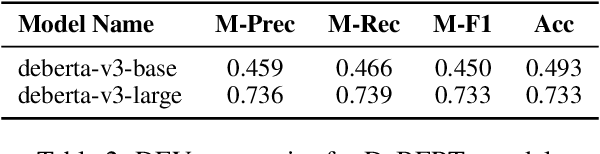
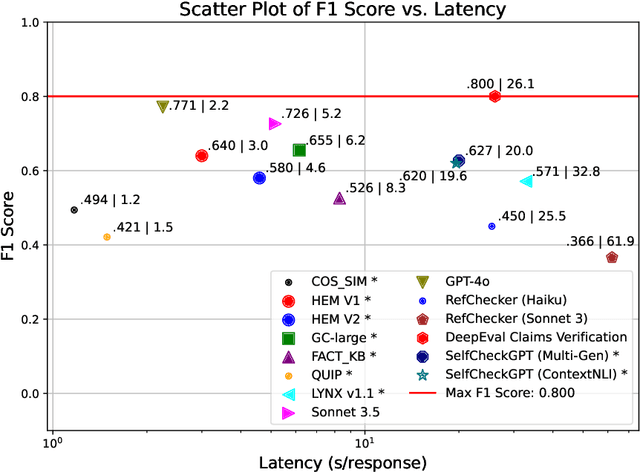
In high-stakes domains like legal question-answering, the accuracy and trustworthiness of generative AI systems are of paramount importance. This work presents a comprehensive benchmark of various methods to assess the groundedness of AI-generated responses, aiming to significantly enhance their reliability. Our experiments include similarity-based metrics and natural language inference models to evaluate whether responses are well-founded in the given contexts. We also explore different prompting strategies for large language models to improve the detection of ungrounded responses. We validated the effectiveness of these methods using a newly created grounding classification corpus, designed specifically for legal queries and corresponding responses from retrieval-augmented prompting, focusing on their alignment with source material. Our results indicate potential in groundedness classification of generated responses, with the best method achieving a macro-F1 score of 0.8. Additionally, we evaluated the methods in terms of their latency to determine their suitability for real-world applications, as this step typically follows the generation process. This capability is essential for processes that may trigger additional manual verification or automated response regeneration. In summary, this study demonstrates the potential of various detection methods to improve the trustworthiness of generative AI in legal settings.
Can We Understand Plasticity Through Neural Collapse?
Apr 03, 2024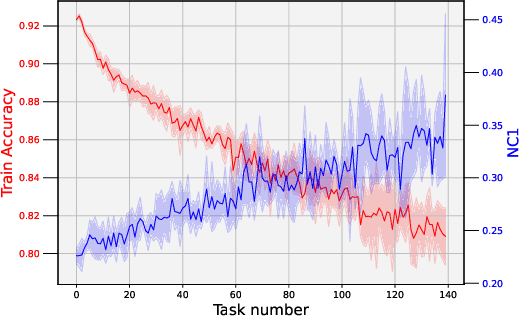
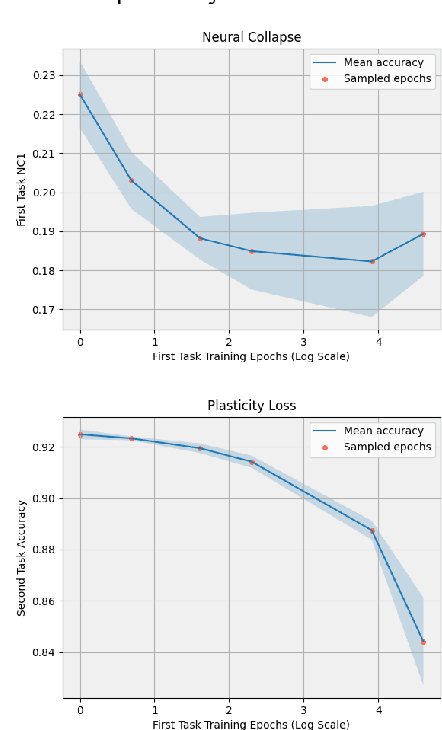
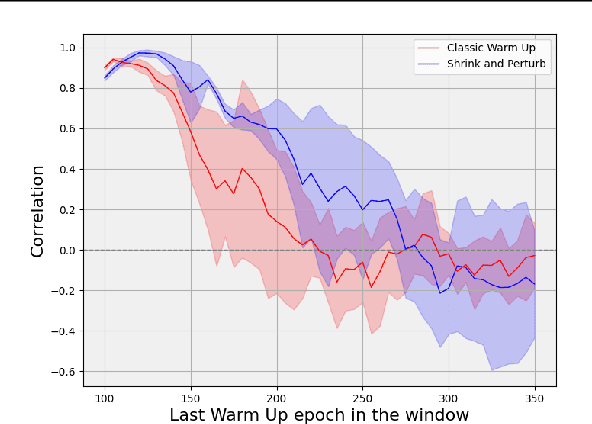
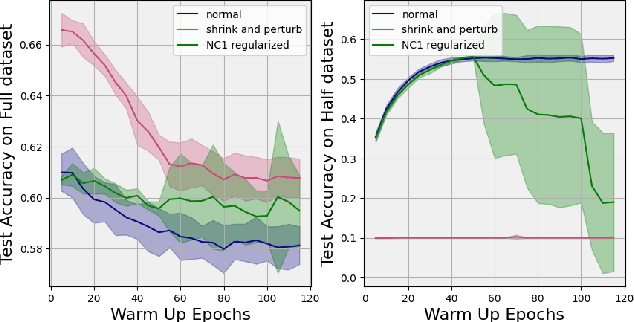
This paper explores the connection between two recently identified phenomena in deep learning: plasticity loss and neural collapse. We analyze their correlation in different scenarios, revealing a significant association during the initial training phase on the first task. Additionally, we introduce a regularization approach to mitigate neural collapse, demonstrating its effectiveness in alleviating plasticity loss in this specific setting.