 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPASC: Measuring Generalization in Weak Supervision
Jun 03, 2022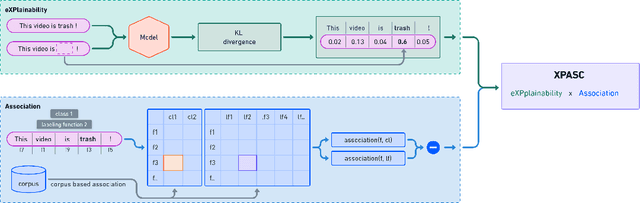
Weak supervision is leveraged in a wide range of domains and tasks due to its ability to create massive amounts of labeled data, requiring only little manual effort. Standard approaches use labeling functions to specify signals that are relevant for the labeling. It has been conjectured that weakly supervised models over-rely on those signals and as a result suffer from overfitting. To verify this assumption, we introduce a novel method, XPASC (eXPlainability-Association SCore), for measuring the generalization of a model trained with a weakly supervised dataset. Considering the occurrences of features, classes and labeling functions in a dataset, XPASC takes into account the relevance of each feature for the predictions of the model as well as the associations of the feature with the class and the labeling function, respectively. The association in XPASC can be measured in two variants: XPASC-CHI SQAURE measures associations relative to their statistical significance, while XPASC-PPMI measures association strength more generally. We use XPASC to analyze KnowMAN, an adversarial architecture intended to control the degree of generalization from the labeling functions and thus to mitigate the problem of overfitting. On one hand, we show that KnowMAN is able to control the degree of generalization through a hyperparameter. On the other hand, results and qualitative analysis show that generalization and performance do not relate one-to-one, and that the highest degree of generalization does not necessarily imply the best performance. Therefore methods that allow for controlling the amount of generalization can achieve the right degree of benign overfitting. Our contributions in this study are i) the XPASC score to measure generalization in weakly-supervised models, ii) evaluation of XPASC across datasets and models and iii) the release of the XPASC implementation.
hmBERT: Historical Multilingual Language Models for Named Entity Recognition
May 31, 2022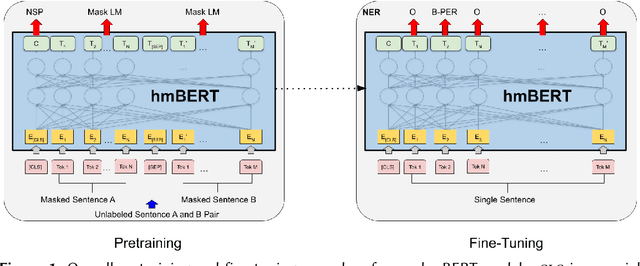



Compared to standard Named Entity Recognition (NER), identifying persons, locations, and organizations in historical texts forms a big challenge. To obtain machine-readable corpora, the historical text is usually scanned and optical character recognition (OCR) needs to be performed. As a result, the historical corpora contain errors. Also, entities like location or organization can change over time, which poses another challenge. Overall historical texts come with several peculiarities that differ greatly from modern texts and large labeled corpora for training a neural tagger are hardly available for this domain. In this work, we tackle NER for historical German, English, French, Swedish, and Finnish by training large historical language models. We circumvent the need for labeled data by using unlabeled data for pretraining a language model. hmBERT, a historical multilingual BERT-based language model is proposed, with different sizes of it being publicly released. Furthermore, we evaluate the capability of hmBERT by solving downstream NER as part of this year's HIPE-2022 shared task and provide detailed analysis and insights. For the Multilingual Classical Commentary coarse-grained NER challenge, our tagger HISTeria outperforms the other teams' models for two out of three languages.
KnowMAN: Weakly Supervised Multinomial Adversarial Networks
Sep 16, 2021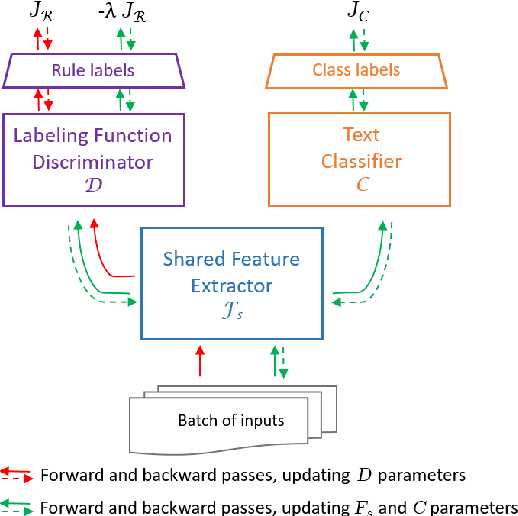


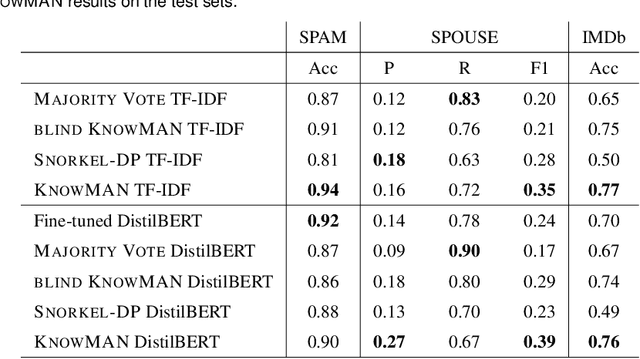
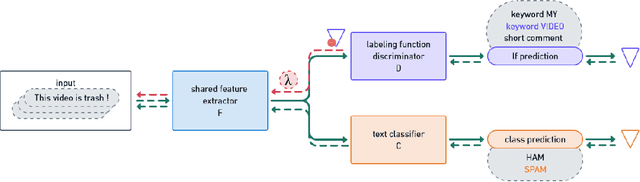
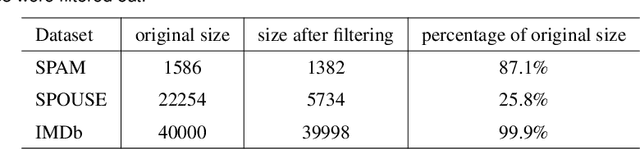
The absence of labeled data for training neural models is often addressed by leveraging knowledge about the specific task, resulting in heuristic but noisy labels. The knowledge is captured in labeling functions, which detect certain regularities or patterns in the training samples and annotate corresponding labels for training. This process of weakly supervised training may result in an over-reliance on the signals captured by the labeling functions and hinder models to exploit other signals or to generalize well. We propose KnowMAN, an adversarial scheme that enables to control influence of signals associated with specific labeling functions. KnowMAN forces the network to learn representations that are invariant to those signals and to pick up other signals that are more generally associated with an output label. KnowMAN strongly improves results compared to direct weakly supervised learning with a pre-trained transformer language model and a feature-based baseline.
Data Centric Domain Adaptation for Historical Text with OCR Errors
Jul 02, 2021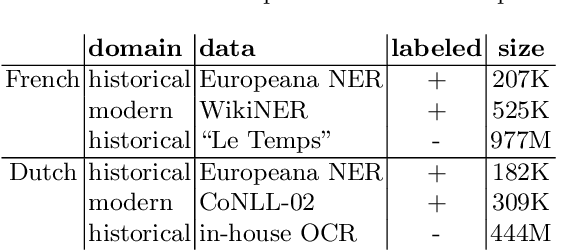

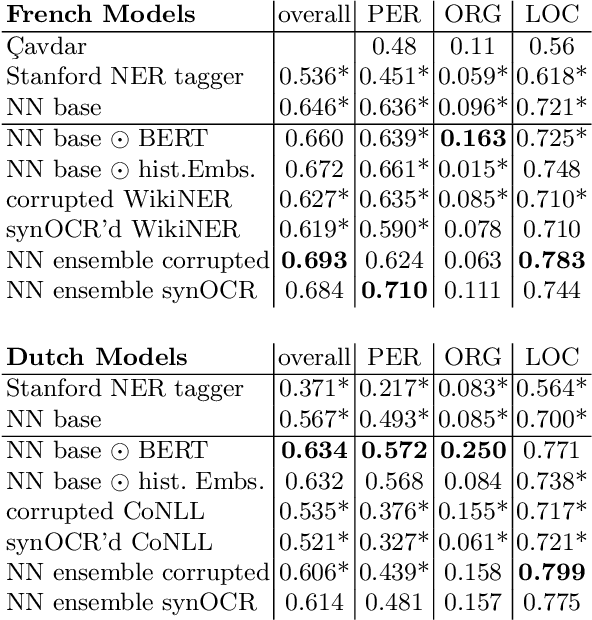

We propose new methods for in-domain and cross-domain Named Entity Recognition (NER) on historical data for Dutch and French. For the cross-domain case, we address domain shift by integrating unsupervised in-domain data via contextualized string embeddings; and OCR errors by injecting synthetic OCR errors into the source domain and address data centric domain adaptation. We propose a general approach to imitate OCR errors in arbitrary input data. Our cross-domain as well as our in-domain results outperform several strong baselines and establish state-of-the-art results. We publish preprocessed versions of the French and Dutch Europeana NER corpora.
Domain adaptation for part-of-speech tagging of noisy user-generated text
May 21, 2019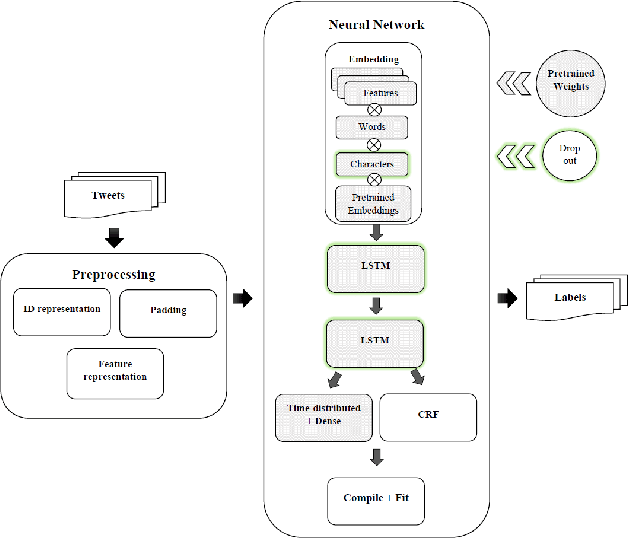
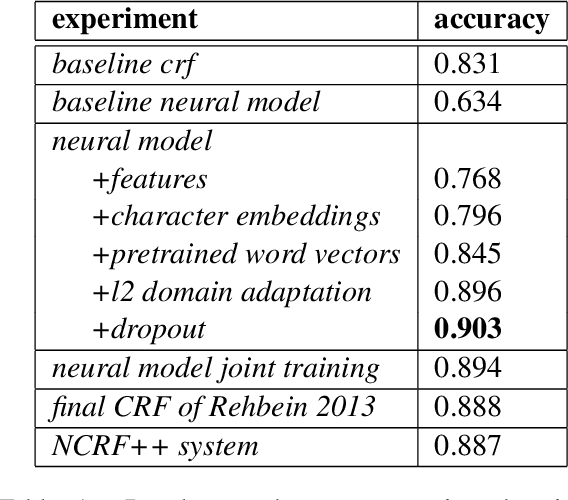
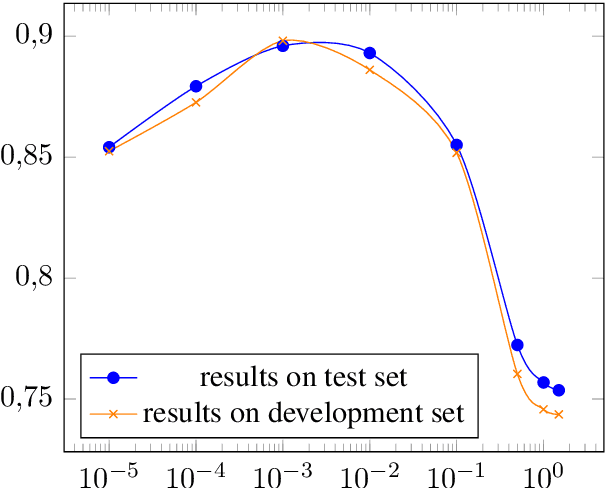
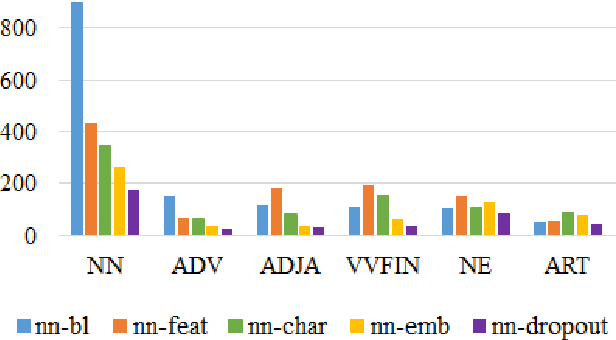
The performance of a Part-of-speech (POS) tagger is highly dependent on the domain ofthe processed text, and for many domains there is no or only very little training data available. This work addresses the problem of POS tagging noisy user-generated text using a neural network. We propose an architecture that trains an out-of-domain model on a large newswire corpus, and transfers those weights by using them as a prior for a model trained on the target domain (a data-set of German Tweets) for which there is very little an-notations available. The neural network has two standard bidirectional LSTMs at its core. However, we find it crucial to also encode a set of task-specific features, and to obtain reliable (source-domain and target-domain) word representations. Experiments with different regularization techniques such as early stopping, dropout and fine-tuning the domain adaptation prior weights are conducted. Our best model uses external weights from the out-of-domain model, as well as feature embeddings, pre-trained word and sub-word embeddings and achieves a tagging accuracy of slightly over 90%, improving on the previous state of the art for this task.