 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Centric Domain Adaptation for Historical Text with OCR Errors
Jul 02, 2021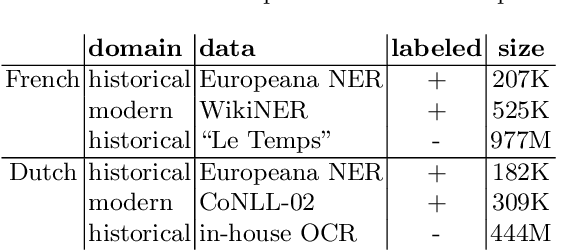

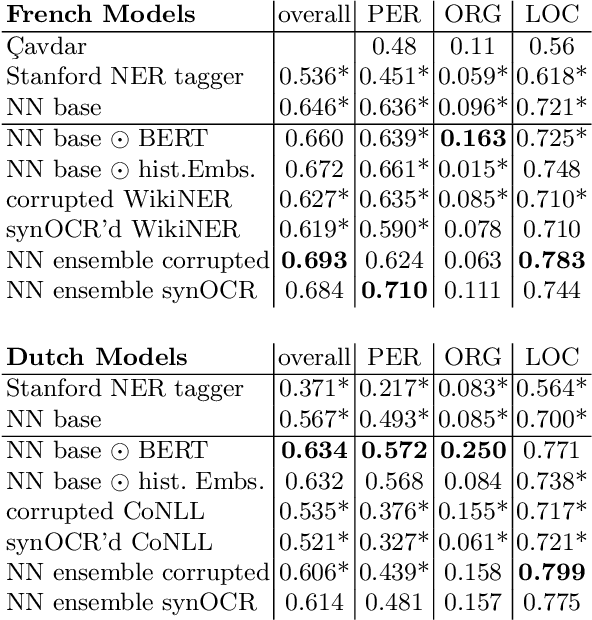

We propose new methods for in-domain and cross-domain Named Entity Recognition (NER) on historical data for Dutch and French. For the cross-domain case, we address domain shift by integrating unsupervised in-domain data via contextualized string embeddings; and OCR errors by injecting synthetic OCR errors into the source domain and address data centric domain adaptation. We propose a general approach to imitate OCR errors in arbitrary input data. Our cross-domain as well as our in-domain results outperform several strong baselines and establish state-of-the-art results. We publish preprocessed versions of the French and Dutch Europeana NER corpora.
Inexpensive Domain Adaptation of Pretrained Language Models: Case Studies on Biomedical NER and Covid-19 QA
Apr 30, 2020
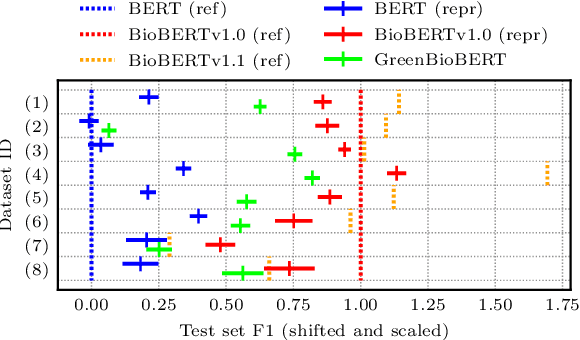
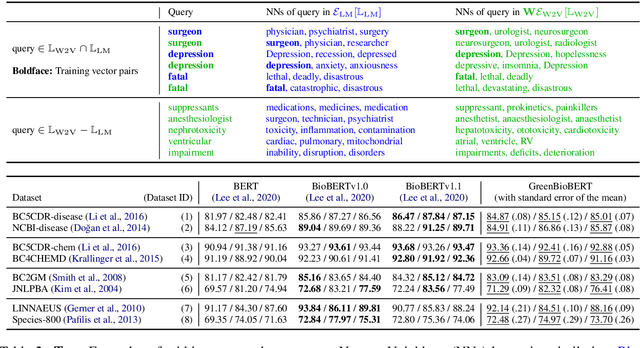

Domain adaptation of Pretrained Language Models (PTLMs) is typically achieved by unsupervised pretraining on target-domain text. While successful, this approach is expensive in terms of hardware, runtime and CO_2 emissions. Here, we propose a cheaper alternative: We train Word2Vec on target-domain text and align the resulting word vectors with the wordpiece vectors of a general-domain PTLM. We evaluate on eight biomedical Named Entity Recognition (NER) tasks and compare against the recently proposed BioBERT model. We cover over 50% of the BioBERT-BERT F1 delta, at 5% of BioBERT's CO_2 footprint and 2% of its cloud compute cost. We also show how to quickly adapt an existing general-domain Question Answering (QA) model to an emerging domain: the Covid-19 pandemic.
Sentence Meta-Embeddings for Unsupervised Semantic Textual Similarity
Nov 09, 2019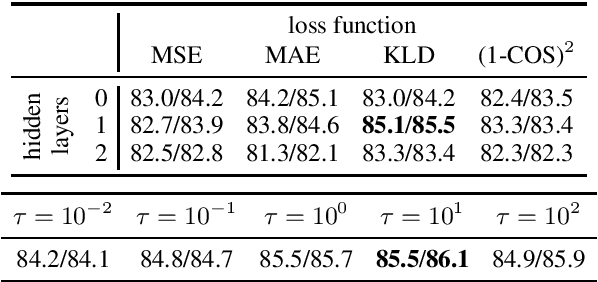
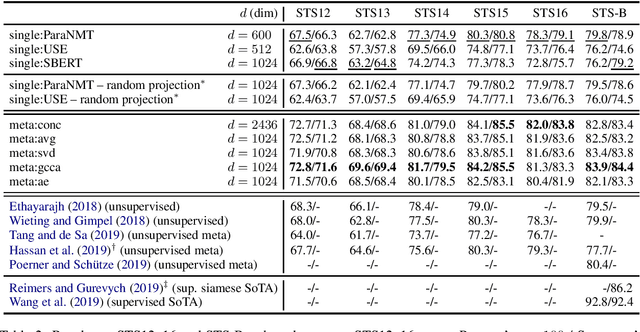

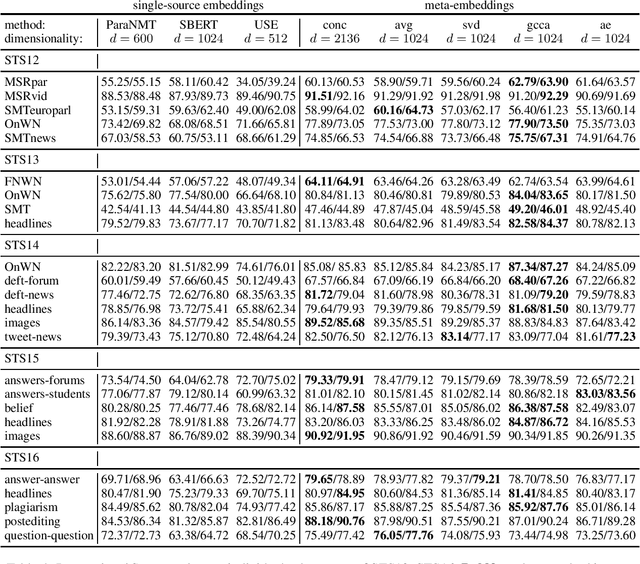
We address the task of unsupervised Semantic Textual Similarity (STS) by ensembling diverse pre-trained sentence encoders into sentence meta-embeddings. We apply and extend different meta-embedding methods from the word embedding literature, including dimensionality reduction (Yin and Sch\"utze, 2016), generalized Canonical Correlation Analysis (Rastogi et al., 2015) and cross-view autoencoders (Bollegala and Bao, 2018). We set a new unsupervised State of The Art (SoTA) on the STS Benchmark and on the STS12-STS16 datasets, with gains of between 3.7% and 6.4% Pearson's r over single-source systems.
BERT is Not a Knowledge Base : Factual Knowledge vs. Name-Based Reasoning in Unsupervised QA
Nov 09, 2019
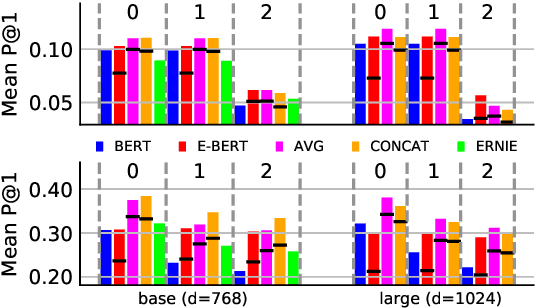
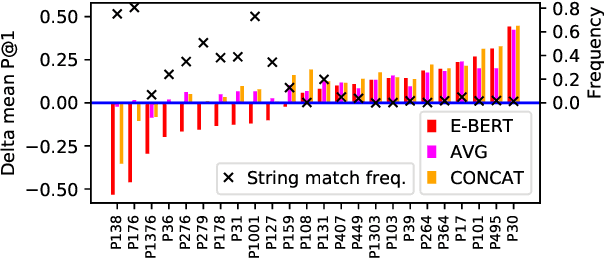
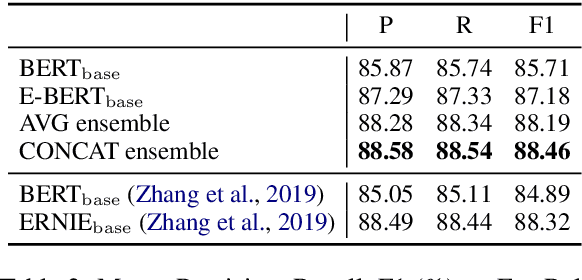
The BERT language model (LM) (Devlin et al., 2019) is surprisingly good at answering cloze-style questions about relational facts. Petroni et al. (2019) take this as evidence that BERT memorizes factual knowledge during pre-training. We take issue with this interpretation and argue that the performance of BERT is partly due to reasoning about (the surface form of) entity names, e.g., guessing that a person with an Italian-sounding name speaks Italian. More specifically, we show that BERT's precision drops dramatically when we filter certain easy-to-guess facts. As a remedy, we propose E-BERT, an extension of BERT that replaces entity mentions with symbolic entity embeddings. E-BERT outperforms both BERT and ERNIE (Zhang et al., 2019) on hard-to-guess queries. We take this as evidence that E-BERT is richer in factual knowledge, and we show two ways of ensembling BERT and E-BERT.
Interpretable Question Answering on Knowledge Bases and Text
Jun 26, 2019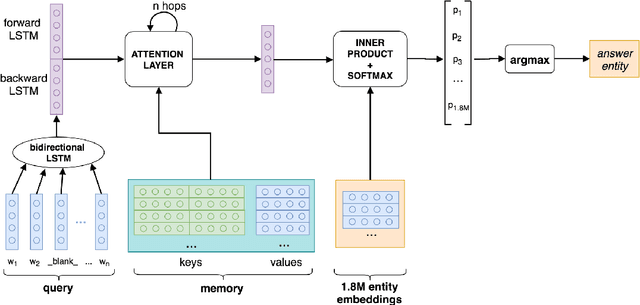


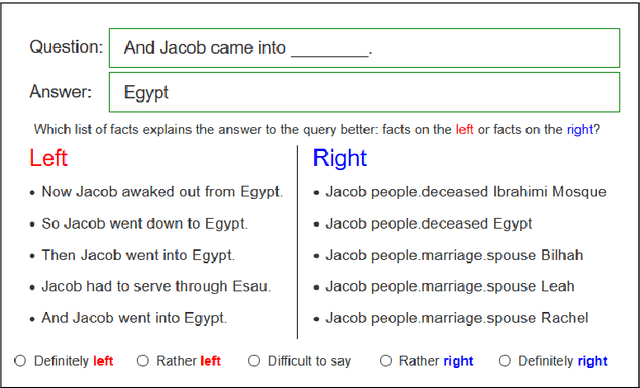
Interpretability of machine learning (ML) models becomes more relevant with their increasing adoption. In this work, we address the interpretability of ML based question answering (QA) models on a combination of knowledge bases (KB) and text documents. We adapt post hoc explanation methods such as LIME and input perturbation (IP) and compare them with the self-explanatory attention mechanism of the model. For this purpose, we propose an automatic evaluation paradigm for explanation methods in the context of QA. We also conduct a study with human annotators to evaluate whether explanations help them identify better QA models. Our results suggest that IP provides better explanations than LIME or attention, according to both automatic and human evaluation. We obtain the same ranking of methods in both experiments, which supports the validity of our automatic evaluation paradigm.
Aligning Very Small Parallel Corpora Using Cross-Lingual Word Embeddings and a Monogamy Objective
Oct 31, 2018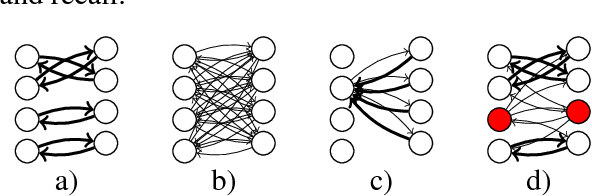
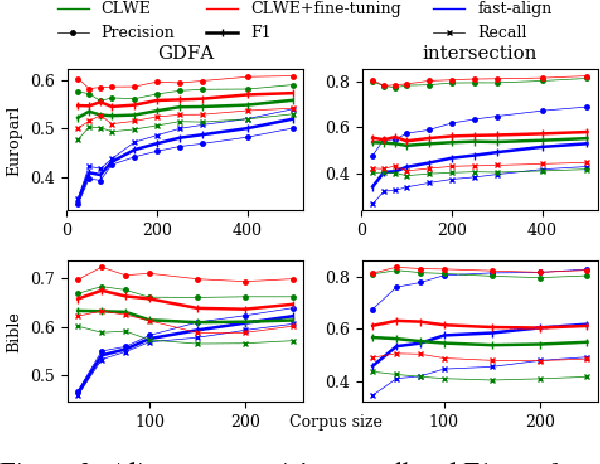
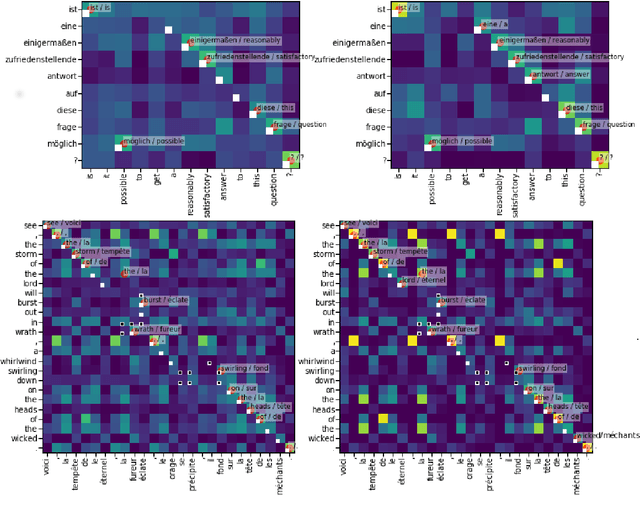
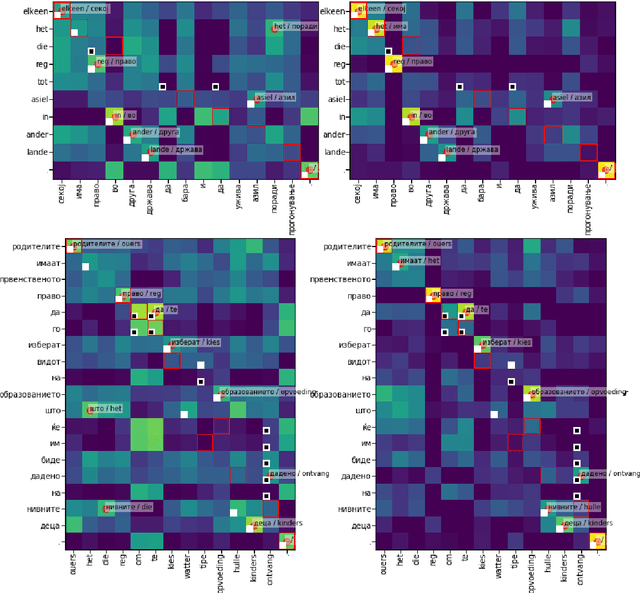
Count-based word alignment methods, such as the IBM models or fast-align, struggle on very small parallel corpora. We therefore present an alternative approach based on cross-lingual word embeddings (CLWEs), which are trained on purely monolingual data. Our main contribution is an unsupervised objective to adapt CLWEs to parallel corpora. In experiments on between 25 and 500 sentences, our method outperforms fast-align. We also show that our fine-tuning objective consistently improves a CLWE-only baseline.
Neural Architectures for Open-Type Relation Argument Extraction
Sep 30, 2018



In this work, we introduce the task of Open-Type Relation Argument Extraction (ORAE): Given a corpus, a query entity Q and a knowledge base relation (e.g.,"Q authored notable work with title X"), the model has to extract an argument of non-standard entity type (entities that cannot be extracted by a standard named entity tagger, e.g. X: the title of a book or a work of art) from the corpus. A distantly supervised dataset based on WikiData relations is obtained and released to address the task. We develop and compare a wide range of neural models for this task yielding large improvements over a strong baseline obtained with a neural question answering system. The impact of different sentence encoding architectures and answer extraction methods is systematically compared. An encoder based on gated recurrent units combined with a conditional random fields tagger gives the best results.
Interpretable Textual Neuron Representations for NLP
Sep 19, 2018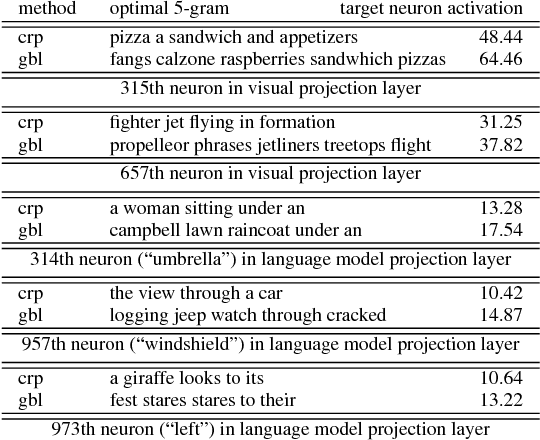
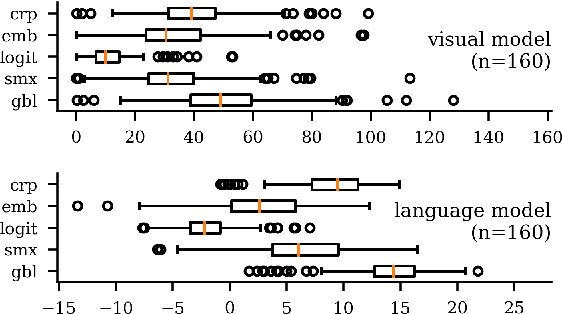
Input optimization methods, such as Google Deep Dream, create interpretable representations of neurons for computer vision DNNs. We propose and evaluate ways of transferring this technology to NLP. Our results suggest that gradient ascent with a gumbel softmax layer produces n-gram representations that outperform naive corpus search in terms of target neuron activation. The representations highlight differences in syntax awareness between the language and visual models of the Imaginet architecture.
Evaluating neural network explanation methods using hybrid documents and morphological agreement
Apr 23, 2018



The behavior of deep neural networks (DNNs) is hard to understand. This makes it necessary to explore post hoc explanation methods. We conduct the first comprehensive evaluation of explanation methods for NLP. To this end, we design two novel evaluation paradigms that cover two important classes of NLP problems: small context and large context problems. Both paradigms require no manual annotation and are therefore broadly applicable. We also introduce LIMSSE, an explanation method inspired by LIME that is designed for NLP. We show empirically that LIMSSE, LRP and DeepLIFT are the most effective explanation methods and recommend them for explaining DNNs in NLP.