 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPASC: Measuring Generalization in Weak Supervision
Jun 03, 2022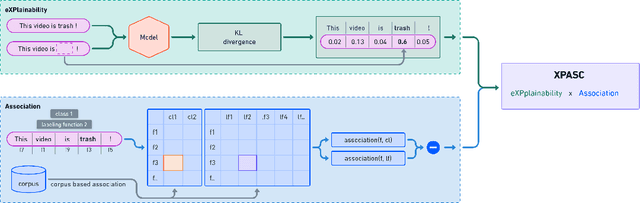
Weak supervision is leveraged in a wide range of domains and tasks due to its ability to create massive amounts of labeled data, requiring only little manual effort. Standard approaches use labeling functions to specify signals that are relevant for the labeling. It has been conjectured that weakly supervised models over-rely on those signals and as a result suffer from overfitting. To verify this assumption, we introduce a novel method, XPASC (eXPlainability-Association SCore), for measuring the generalization of a model trained with a weakly supervised dataset. Considering the occurrences of features, classes and labeling functions in a dataset, XPASC takes into account the relevance of each feature for the predictions of the model as well as the associations of the feature with the class and the labeling function, respectively. The association in XPASC can be measured in two variants: XPASC-CHI SQAURE measures associations relative to their statistical significance, while XPASC-PPMI measures association strength more generally. We use XPASC to analyze KnowMAN, an adversarial architecture intended to control the degree of generalization from the labeling functions and thus to mitigate the problem of overfitting. On one hand, we show that KnowMAN is able to control the degree of generalization through a hyperparameter. On the other hand, results and qualitative analysis show that generalization and performance do not relate one-to-one, and that the highest degree of generalization does not necessarily imply the best performance. Therefore methods that allow for controlling the amount of generalization can achieve the right degree of benign overfitting. Our contributions in this study are i) the XPASC score to measure generalization in weakly-supervised models, ii) evaluation of XPASC across datasets and models and iii) the release of the XPASC implementation.
KnowMAN: Weakly Supervised Multinomial Adversarial Networks
Sep 16, 2021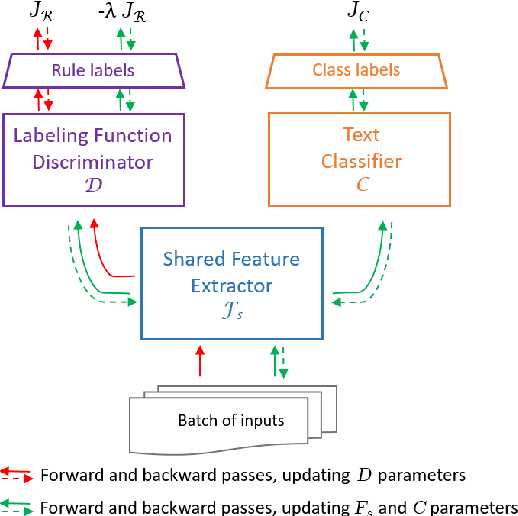


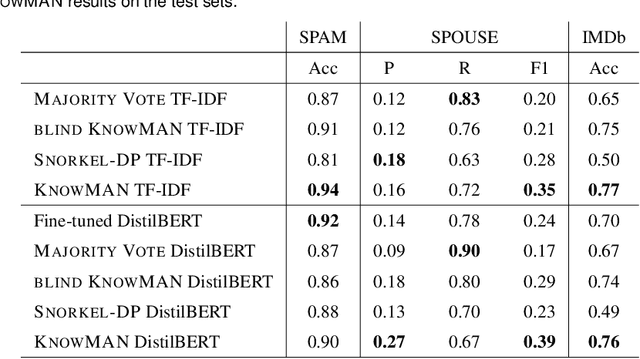
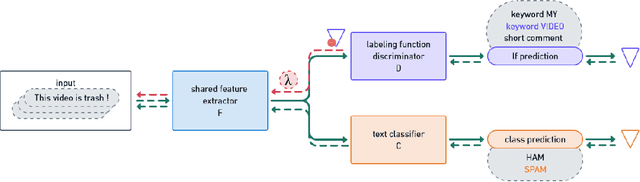
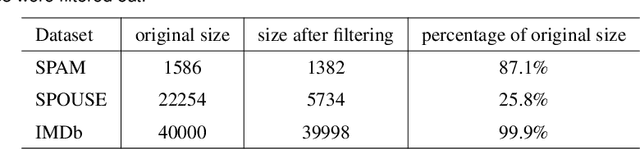
The absence of labeled data for training neural models is often addressed by leveraging knowledge about the specific task, resulting in heuristic but noisy labels. The knowledge is captured in labeling functions, which detect certain regularities or patterns in the training samples and annotate corresponding labels for training. This process of weakly supervised training may result in an over-reliance on the signals captured by the labeling functions and hinder models to exploit other signals or to generalize well. We propose KnowMAN, an adversarial scheme that enables to control influence of signals associated with specific labeling functions. KnowMAN forces the network to learn representations that are invariant to those signals and to pick up other signals that are more generally associated with an output label. KnowMAN strongly improves results compared to direct weakly supervised learning with a pre-trained transformer language model and a feature-based baseline.
UniSent: Universal Adaptable Sentiment Lexica for 1000+ Languages
Apr 21, 2019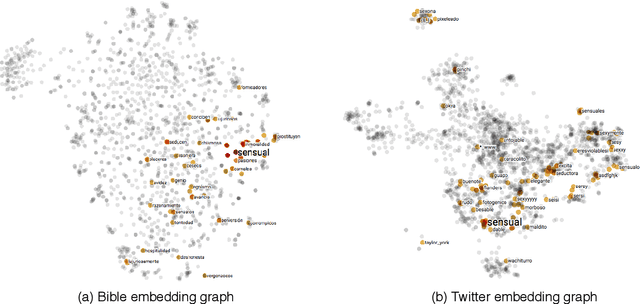
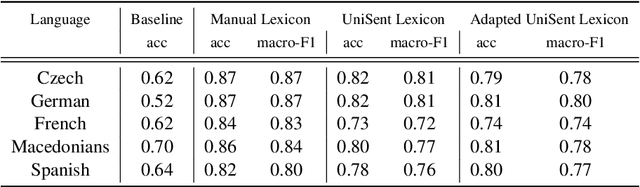
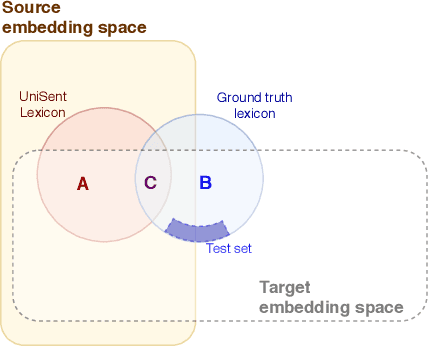
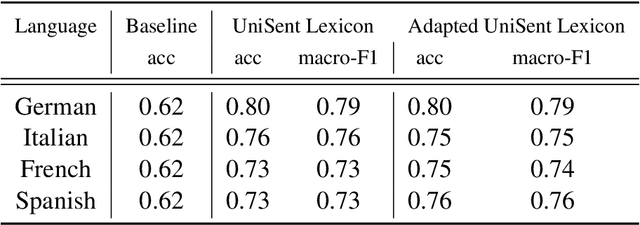
In this paper, we introduce UniSent a universal sentiment lexica for 1000 languages created using an English sentiment lexicon and a massively parallel corpus in the Bible domain. To the best of our knowledge, UniSent is the largest sentiment resource to date in terms of number of covered languages, including many low resource languages. To create UniSent, we propose Adapted Sentiment Pivot, a novel method that combines annotation projection, vocabulary expansion, and unsupervised domain adaptation. We evaluate the quality of UniSent for Macedonian, Czech, German, Spanish, and French and show that its quality is comparable to manually or semi-manually created sentiment resources. With the publication of this paper, we release UniSent lexica as well as Adapted Sentiment Pivot related codes. method.