 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPASC: Measuring Generalization in Weak Supervision
Paper and Code
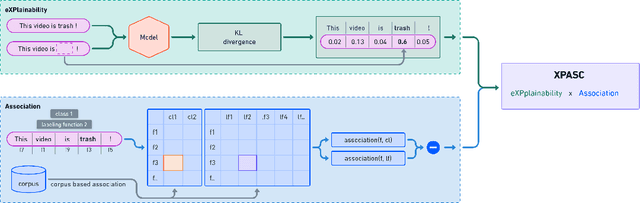
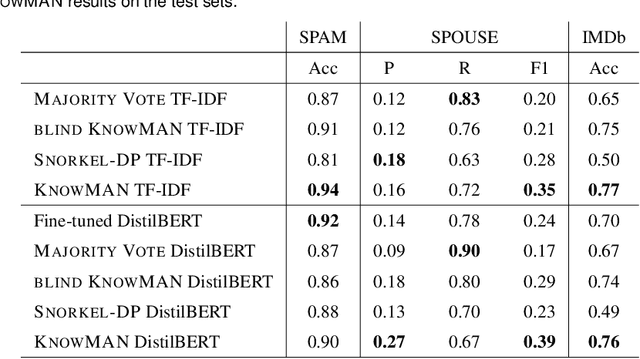
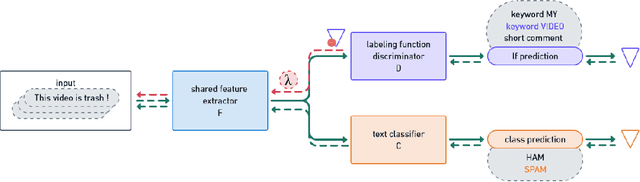
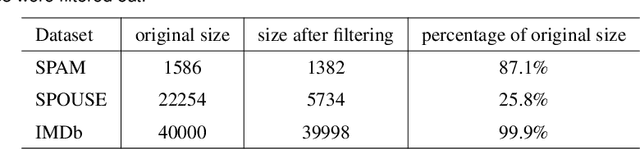
Weak supervision is leveraged in a wide range of domains and tasks due to its ability to create massive amounts of labeled data, requiring only little manual effort. Standard approaches use labeling functions to specify signals that are relevant for the labeling. It has been conjectured that weakly supervised models over-rely on those signals and as a result suffer from overfitting. To verify this assumption, we introduce a novel method, XPASC (eXPlainability-Association SCore), for measuring the generalization of a model trained with a weakly supervised dataset. Considering the occurrences of features, classes and labeling functions in a dataset, XPASC takes into account the relevance of each feature for the predictions of the model as well as the associations of the feature with the class and the labeling function, respectively. The association in XPASC can be measured in two variants: XPASC-CHI SQAURE measures associations relative to their statistical significance, while XPASC-PPMI measures association strength more generally. We use XPASC to analyze KnowMAN, an adversarial architecture intended to control the degree of generalization from the labeling functions and thus to mitigate the problem of overfitting. On one hand, we show that KnowMAN is able to control the degree of generalization through a hyperparameter. On the other hand, results and qualitative analysis show that generalization and performance do not relate one-to-one, and that the highest degree of generalization does not necessarily imply the best performance. Therefore methods that allow for controlling the amount of generalization can achieve the right degree of benign overfitting. Our contributions in this study are i) the XPASC score to measure generalization in weakly-supervised models, ii) evaluation of XPASC across datasets and models and iii) the release of the XPASC implementation.