 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-R1: Incentivizing the Zero-Shot Graph Learning Capability in LLMs via Explicit Reasoning
Aug 24, 2025
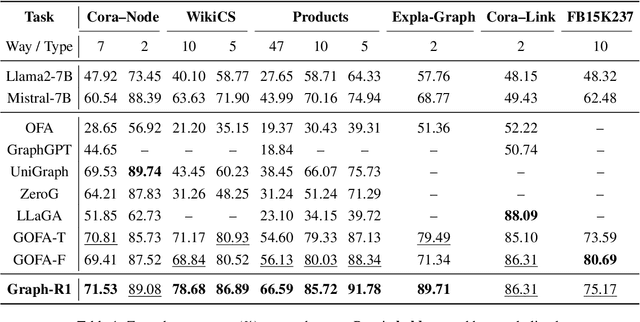
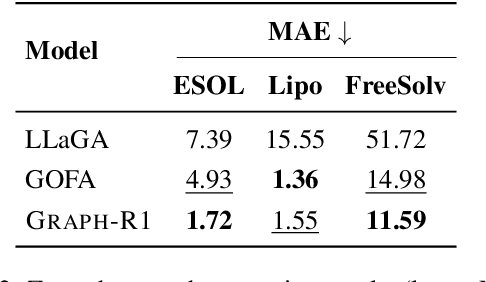
Generalizing to unseen graph tasks without task-pecific supervision remains challenging. Graph Neural Networks (GNNs) are limited by fixed label spaces, while Large Language Models (LLMs) lack structural inductive biases. Recent advances in Large Reasoning Models (LRMs) provide a zero-shot alternative via explicit, long chain-of-thought reasoning. Inspired by this, we propose a GNN-free approach that reformulates graph tasks--node classification, link prediction, and graph classification--as textual reasoning problems solved by LRMs. We introduce the first datasets with detailed reasoning traces for these tasks and develop Graph-R1, a reinforcement learning framework that leverages task-specific rethink templates to guide reasoning over linearized graphs. Experiments demonstrate that Graph-R1 outperforms state-of-the-art baselines in zero-shot settings, producing interpretable and effective predictions. Our work highlights the promise of explicit reasoning for graph learning and provides new resources for future research.
LLMs as Zero-shot Graph Learners: Alignment of GNN Representations with LLM Token Embeddings
Aug 25, 2024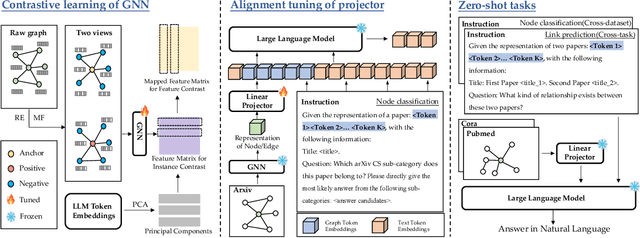
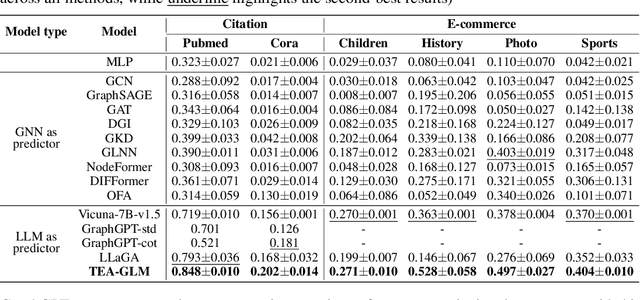
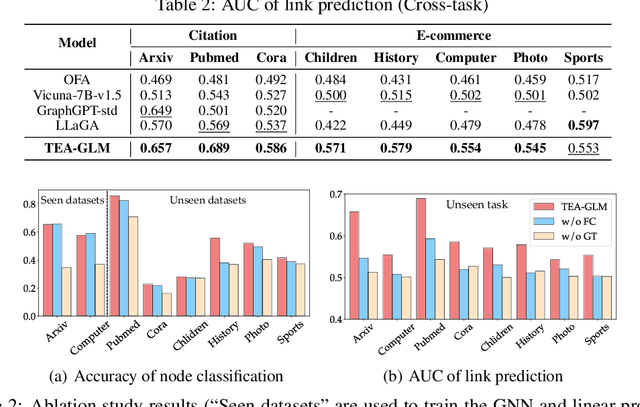
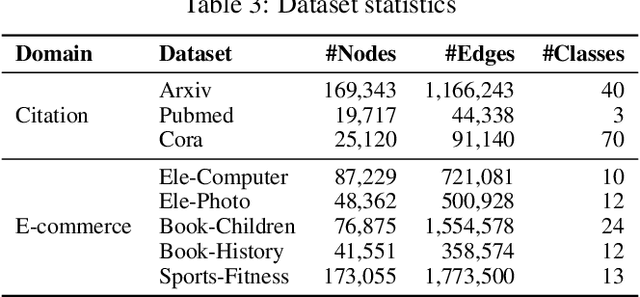
Zero-shot graph machine learning, especially with graph neural networks (GNNs), has garnered significant interest due to the challenge of scarce labeled data. While methods like self-supervised learning and graph prompt learning have been extensively explored, they often rely on fine-tuning with task-specific labels, limiting their effectiveness in zero-shot scenarios. Inspired by the zero-shot capabilities of instruction-fine-tuned large language models (LLMs), we introduce a novel framework named Token Embedding-Aligned Graph Language Model (TEA-GLM) that leverages LLMs as cross-dataset and cross-task zero-shot learners for graph machine learning. Concretely, we pretrain a GNN, aligning its representations with token embeddings of an LLM. We then train a linear projector that transforms the GNN's representations into a fixed number of graph token embeddings without tuning the LLM. A unified instruction is designed for various graph tasks at different levels, such as node classification (node-level) and link prediction (edge-level). These design choices collectively enhance our method's effectiveness in zero-shot learning, setting it apart from existing methods. Experiments show that our graph token embeddings help the LLM predictor achieve state-of-the-art performance on unseen datasets and tasks compared to other methods using LLMs as predictors.
Language Model as an Annotator: Unsupervised Context-aware Quality Phrase Generation
Dec 28, 2023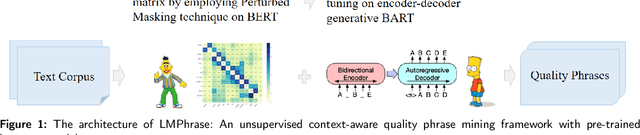
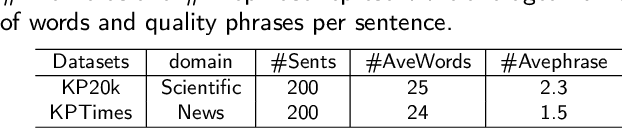
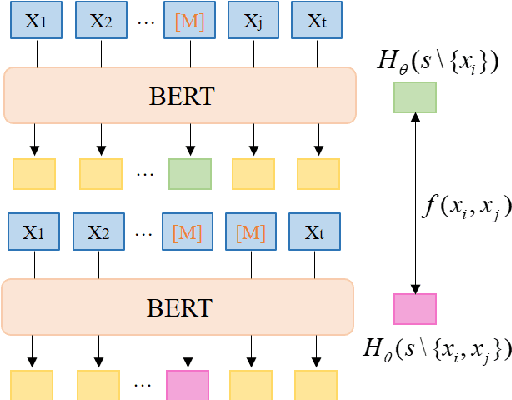

Phrase mining is a fundamental text mining task that aims to identify quality phrases from context. Nevertheless, the scarcity of extensive gold labels datasets, demanding substantial annotation efforts from experts, renders this task exceptionally challenging. Furthermore, the emerging, infrequent, and domain-specific nature of quality phrases presents further challenges in dealing with this task. In this paper, we propose LMPhrase, a novel unsupervised context-aware quality phrase mining framework built upon large pre-trained language models (LMs). Specifically, we first mine quality phrases as silver labels by employing a parameter-free probing technique called Perturbed Masking on the pre-trained language model BERT (coined as Annotator). In contrast to typical statistic-based or distantly-supervised methods, our silver labels, derived from large pre-trained language models, take into account rich contextual information contained in the LMs. As a result, they bring distinct advantages in preserving informativeness, concordance, and completeness of quality phrases. Secondly, training a discriminative span prediction model heavily relies on massive annotated data and is likely to face the risk of overfitting silver labels. Alternatively, we formalize phrase tagging task as the sequence generation problem by directly fine-tuning on the Sequence-to-Sequence pre-trained language model BART with silver labels (coined as Generator). Finally, we merge the quality phrases from both the Annotator and Generator as the final predictions, considering their complementary nature and distinct characteristics. Extensive experiments show that our LMPhrase consistently outperforms all the existing competitors across two different granularity phrase mining tasks, where each task is tested on two different domain datasets.
TegFormer: Topic-to-Essay Generation with Good Topic Coverage and High Text Coherence
Dec 27, 2022Creating an essay based on a few given topics is a challenging NLP task. Although several effective methods for this problem, topic-to-essay generation, have appeared recently, there is still much room for improvement, especially in terms of the coverage of the given topics and the coherence of the generated text. In this paper, we propose a novel approach called TegFormer which utilizes the Transformer architecture where the encoder is enriched with domain-specific contexts while the decoder is enhanced by a large-scale pre-trained language model. Specifically, a \emph{Topic-Extension} layer capturing the interaction between the given topics and their domain-specific contexts is plugged into the encoder. Since the given topics are usually concise and sparse, such an additional layer can bring more topic-related semantics in to facilitate the subsequent natural language generation. Moreover, an \emph{Embedding-Fusion} module that combines the domain-specific word embeddings learnt from the given corpus and the general-purpose word embeddings provided by a GPT-2 model pre-trained on massive text data is integrated into the decoder. Since GPT-2 is at a much larger scale, it contains a lot more implicit linguistic knowledge which would help the decoder to produce more grammatical and readable text. Extensive experiments have shown that the pieces of text generated by TegFormer have better topic coverage and higher text coherence than those from SOTA topic-to-essay techniques, according to automatic and human evaluations. As revealed by ablation studies, both the Topic-Extension layer and the Embedding-Fusion module contribute substantially to TegFormer's performance advantage.
Parameter-Efficient Tuning on Layer Normalization for Pre-trained Language Models
Dec 09, 2022



Conventional fine-tuning encounters increasing difficulties given the size of current Pre-trained Language Models, which makes parameter-efficient tuning become the focal point of frontier research. Previous methods in this field add tunable adapters into MHA or/and FFN of Transformer blocks to enable PLMs achieve transferability. However, as an important part of Transformer architecture, the power of layer normalization for parameter-efficent tuning is ignored. In this paper, we first propose LN-tuning, by tuning the gain and bias term of Layer Normalization module with only 0.03\% parameters, which is of high time-efficency and significantly superior to baselines which are less than 0.1\% tunable parameters. Further, we study the unified framework of combining LN-tuning with previous ones and we find that: (1) the unified framework of combining prefix-tuning, the adapter-based method working on MHA, and LN-tuning achieves SOTA performance. (2) unified framework which tunes MHA and LayerNorm simultaneously can get performance improvement but those which tune FFN and LayerNorm simultaneous will cause performance decrease. Ablation study validates LN-tuning is of no abundant parameters and gives a further understanding of it.
Multi-Aspect Temporal Network Embedding: A Mixture of Hawkes Process View
May 18, 2021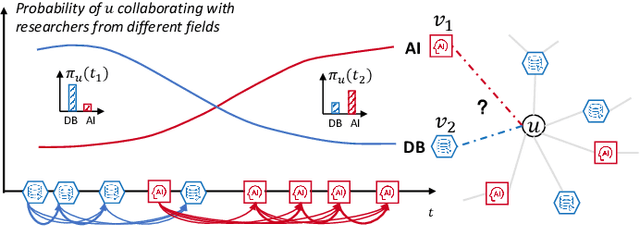
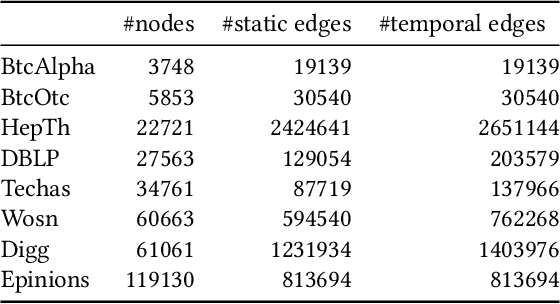
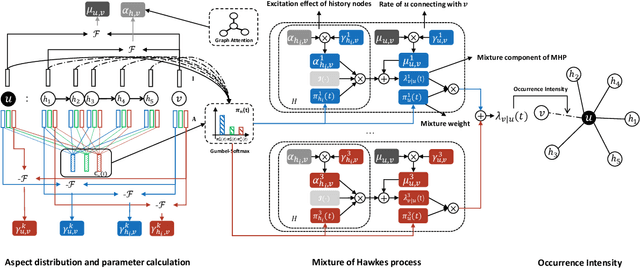
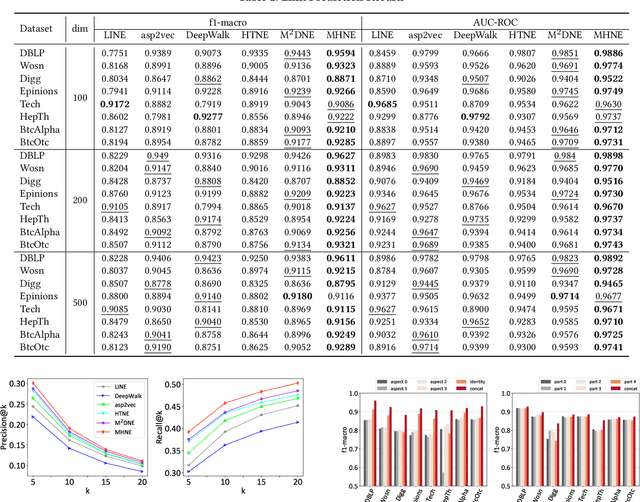
Recent years have witnessed the tremendous research interests in network embedding. Extant works have taken the neighborhood formation as the critical information to reveal the inherent dynamics of network structures, and suggested encoding temporal edge formation sequences to capture the historical influences of neighbors. In this paper, however, we argue that the edge formation can be attributed to a variety of driving factors including the temporal influence, which is better referred to as multiple aspects. As a matter of fact, different node aspects can drive the formation of distinctive neighbors, giving birth to the multi-aspect embedding that relates to but goes beyond a temporal scope. Along this vein, we propose a Mixture of Hawkes-based Temporal Network Embeddings (MHNE) model to capture the aspect-driven neighborhood formation of networks. In MHNE, we encode the multi-aspect embeddings into the mixture of Hawkes processes to gain the advantages in modeling the excitation effects and the latent aspects. Specifically, a graph attention mechanism is used to assign different weights to account for the excitation effects of history events, while a Gumbel-Softmax is plugged in to derive the distribution over the aspects. Extensive experiments on 8 different temporal networks have demonstrated the great performance of the multi-aspect embeddings obtained by MHNE in comparison with the state-of-the-art methods.
Word Network Topic Model: A Simple but General Solution for Short and Imbalanced Texts
Dec 17, 2014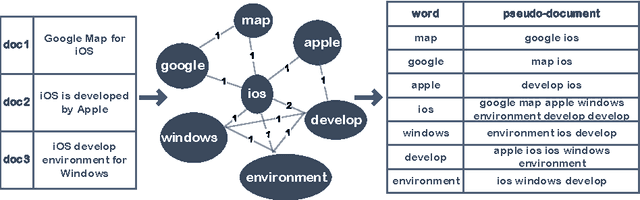
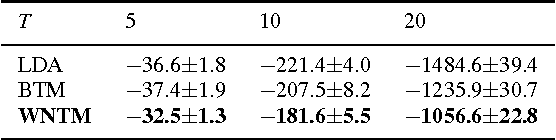
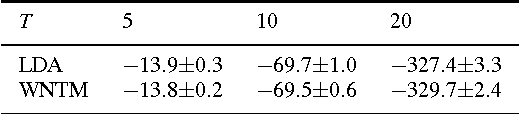
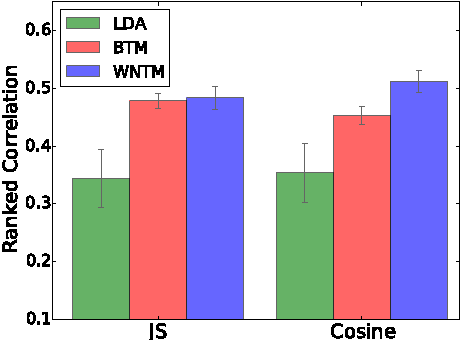
The short text has been the prevalent format for information of Internet in recent decades, especially with the development of online social media, whose millions of users generate a vast number of short messages everyday. Although sophisticated signals delivered by the short text make it a promising source for topic modeling, its extreme sparsity and imbalance brings unprecedented challenges to conventional topic models like LDA and its variants. Aiming at presenting a simple but general solution for topic modeling in short texts, we present a word co-occurrence network based model named WNTM to tackle the sparsity and imbalance simultaneously. Different from previous approaches, WNTM models the distribution over topics for each word instead of learning topics for each document, which successfully enhance the semantic density of data space without importing too much time or space complexity. Meanwhile, the rich contextual information preserved in the word-word space also guarantees its sensitivity in identifying rare topics with convincing quality. Furthermore, employing the same Gibbs sampling with LDA makes WNTM easily to be extended to various application scenarios. Extensive validations on both short and normal texts testify the outperformance of WNTM as compared to baseline methods. And finally we also demonstrate its potential in precisely discovering newly emerging topics or unexpected events in Weibo at pretty early stages.