 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Network Topic Model: A Simple but General Solution for Short and Imbalanced Texts
Paper and Code
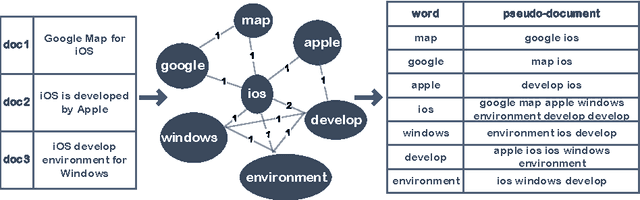
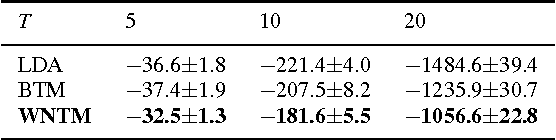
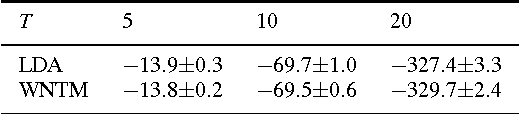
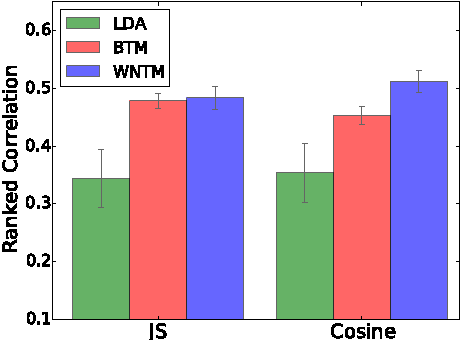
The short text has been the prevalent format for information of Internet in recent decades, especially with the development of online social media, whose millions of users generate a vast number of short messages everyday. Although sophisticated signals delivered by the short text make it a promising source for topic modeling, its extreme sparsity and imbalance brings unprecedented challenges to conventional topic models like LDA and its variants. Aiming at presenting a simple but general solution for topic modeling in short texts, we present a word co-occurrence network based model named WNTM to tackle the sparsity and imbalance simultaneously. Different from previous approaches, WNTM models the distribution over topics for each word instead of learning topics for each document, which successfully enhance the semantic density of data space without importing too much time or space complexity. Meanwhile, the rich contextual information preserved in the word-word space also guarantees its sensitivity in identifying rare topics with convincing quality. Furthermore, employing the same Gibbs sampling with LDA makes WNTM easily to be extended to various application scenarios. Extensive validations on both short and normal texts testify the outperformance of WNTM as compared to baseline methods. And finally we also demonstrate its potential in precisely discovering newly emerging topics or unexpected events in Weibo at pretty early stages.