 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model as an Annotator: Unsupervised Context-aware Quality Phrase Generation
Paper and Code
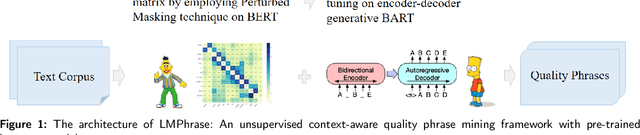
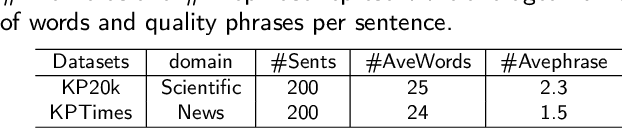
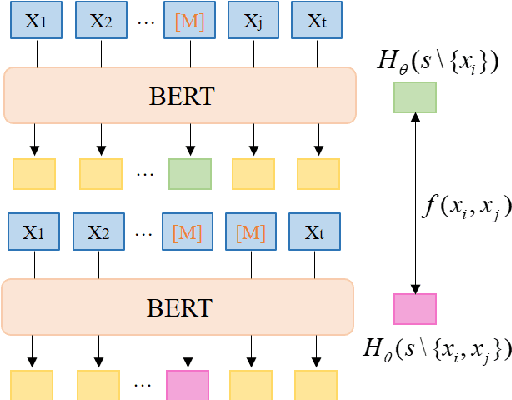

Phrase mining is a fundamental text mining task that aims to identify quality phrases from context. Nevertheless, the scarcity of extensive gold labels datasets, demanding substantial annotation efforts from experts, renders this task exceptionally challenging. Furthermore, the emerging, infrequent, and domain-specific nature of quality phrases presents further challenges in dealing with this task. In this paper, we propose LMPhrase, a novel unsupervised context-aware quality phrase mining framework built upon large pre-trained language models (LMs). Specifically, we first mine quality phrases as silver labels by employing a parameter-free probing technique called Perturbed Masking on the pre-trained language model BERT (coined as Annotator). In contrast to typical statistic-based or distantly-supervised methods, our silver labels, derived from large pre-trained language models, take into account rich contextual information contained in the LMs. As a result, they bring distinct advantages in preserving informativeness, concordance, and completeness of quality phrases. Secondly, training a discriminative span prediction model heavily relies on massive annotated data and is likely to face the risk of overfitting silver labels. Alternatively, we formalize phrase tagging task as the sequence generation problem by directly fine-tuning on the Sequence-to-Sequence pre-trained language model BART with silver labels (coined as Generator). Finally, we merge the quality phrases from both the Annotator and Generator as the final predictions, considering their complementary nature and distinct characteristics. Extensive experiments show that our LMPhrase consistently outperforms all the existing competitors across two different granularity phrase mining tasks, where each task is tested on two different domain datasets.