 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Right Model for the Job: An Evaluation of Legal Multi-Label Classification Baselines
Jan 22, 2024Multi-Label Classification (MLC) is a common task in the legal domain, where more than one label may be assigned to a legal document. A wide range of methods can be applied, ranging from traditional ML approaches to the latest Transformer-based architectures. In this work, we perform an evaluation of different MLC methods using two public legal datasets, POSTURE50K and EURLEX57K. By varying the amount of training data and the number of labels, we explore the comparative advantage offered by different approaches in relation to the dataset properties. Our findings highlight DistilRoBERTa and LegalBERT as performing consistently well in legal MLC with reasonable computational demands. T5 also demonstrates comparable performance while offering advantages as a generative model in the presence of changing label sets. Finally, we show that the CrossEncoder exhibits potential for notable macro-F1 score improvements, albeit with increased computational costs.
Context-Aware Classification of Legal Document Pages
Apr 25, 2023



For many business applications that require the processing, indexing, and retrieval of professional documents such as legal briefs (in PDF format etc.), it is often essential to classify the pages of any given document into their corresponding types beforehand. Most existing studies in the field of document image classification either focus on single-page documents or treat multiple pages in a document independently. Although in recent years a few techniques have been proposed to exploit the context information from neighboring pages to enhance document page classification, they typically cannot be utilized with large pre-trained language models due to the constraint on input length. In this paper, we present a simple but effective approach that overcomes the above limitation. Specifically, we enhance the input with extra tokens carrying sequential information about previous pages - introducing recurrence - which enables the usage of pre-trained Transformer models like BERT for context-aware page classification. Our experiments conducted on two legal datasets in English and Portuguese respectively show that the proposed approach can significantly improve the performance of document page classification compared to the non-recurrent setup as well as the other context-aware baselines.
Determinantal Beam Search
Jun 21, 2021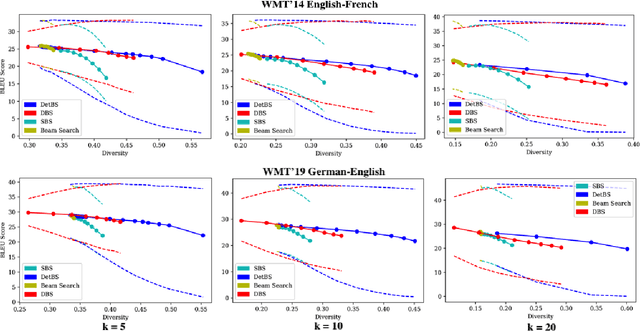


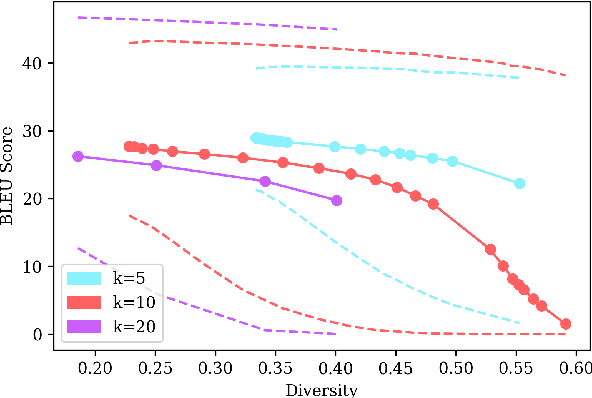
Beam search is a go-to strategy for decoding neural sequence models. The algorithm can naturally be viewed as a subset optimization problem, albeit one where the corresponding set function does not reflect interactions between candidates. Empirically, this leads to sets often exhibiting high overlap, e.g., strings may differ by only a single word. Yet in use-cases that call for multiple solutions, a diverse or representative set is often desired. To address this issue, we propose a reformulation of beam search, which we call determinantal beam search. Determinantal beam search has a natural relationship to determinantal point processes (DPPs), models over sets that inherently encode intra-set interactions. By posing iterations in beam search as a series of subdeterminant maximization problems, we can turn the algorithm into a diverse subset selection process. In a case study, we use the string subsequence kernel to explicitly encourage n-gram coverage in text generated from a sequence model. We observe that our algorithm offers competitive performance against other diverse set generation strategies in the context of language generation, while providing a more general approach to optimizing for diversity.
Searching for Search Errors in Neural Morphological Inflection
Feb 16, 2021
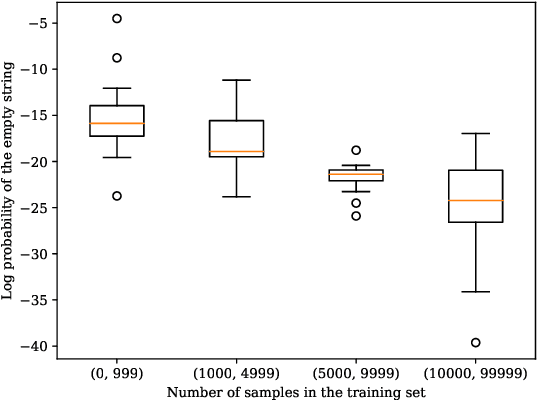

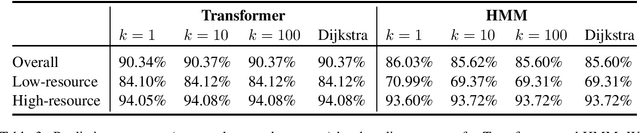
Neural sequence-to-sequence models are currently the predominant choice for language generation tasks. Yet, on word-level tasks, exact inference of these models reveals the empty string is often the global optimum. Prior works have speculated this phenomenon is a result of the inadequacy of neural models for language generation. However, in the case of morphological inflection, we find that the empty string is almost never the most probable solution under the model. Further, greedy search often finds the global optimum. These observations suggest that the poor calibration of many neural models may stem from characteristics of a specific subset of tasks rather than general ill-suitedness of such models for language generation.