 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Right Model for the Job: An Evaluation of Legal Multi-Label Classification Baselines
Jan 22, 2024Multi-Label Classification (MLC) is a common task in the legal domain, where more than one label may be assigned to a legal document. A wide range of methods can be applied, ranging from traditional ML approaches to the latest Transformer-based architectures. In this work, we perform an evaluation of different MLC methods using two public legal datasets, POSTURE50K and EURLEX57K. By varying the amount of training data and the number of labels, we explore the comparative advantage offered by different approaches in relation to the dataset properties. Our findings highlight DistilRoBERTa and LegalBERT as performing consistently well in legal MLC with reasonable computational demands. T5 also demonstrates comparable performance while offering advantages as a generative model in the presence of changing label sets. Finally, we show that the CrossEncoder exhibits potential for notable macro-F1 score improvements, albeit with increased computational costs.
A Framework for Monitoring and Retraining Language Models in Real-World Applications
Nov 17, 2023

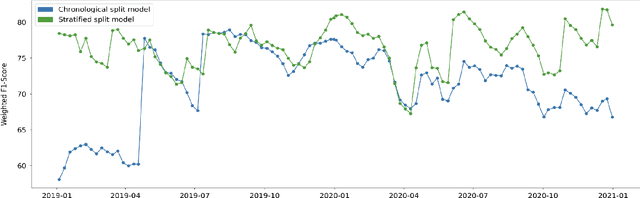
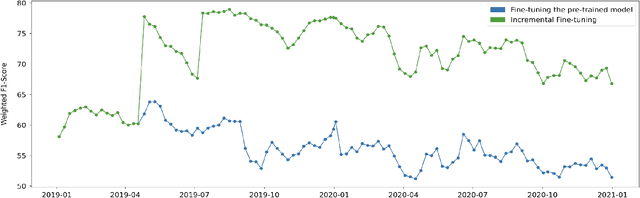
In the Machine Learning (ML) model development lifecycle, training candidate models using an offline holdout dataset and identifying the best model for the given task is only the first step. After the deployment of the selected model, continuous model monitoring and model retraining is required in many real-world applications. There are multiple reasons for retraining, including data or concept drift, which may be reflected on the model performance as monitored by an appropriate metric. Another motivation for retraining is the acquisition of increasing amounts of data over time, which may be used to retrain and improve the model performance even in the absence of drifts. We examine the impact of various retraining decision points on crucial factors, such as model performance and resource utilization, in the context of Multilabel Classification models. We explain our key decision points and propose a reference framework for designing an effective model retraining strategy.
Named Entity Recognition in the Legal Domain using a Pointer Generator Network
Dec 17, 2020

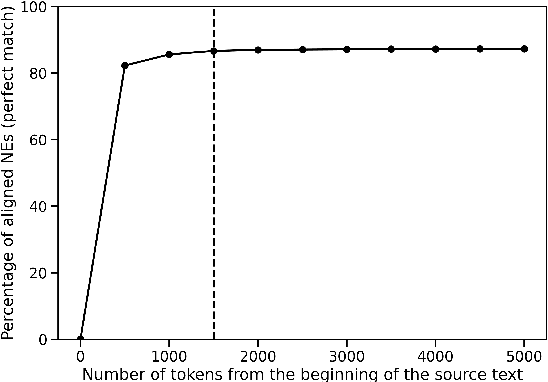

Named Entity Recognition (NER) is the task of identifying and classifying named entities in unstructured text. In the legal domain, named entities of interest may include the case parties, judges, names of courts, case numbers, references to laws etc. We study the problem of legal NER with noisy text extracted from PDF files of filed court cases from US courts. The "gold standard" training data for NER systems provide annotation for each token of the text with the corresponding entity or non-entity label. We work with only partially complete training data, which differ from the gold standard NER data in that the exact location of the entities in the text is unknown and the entities may contain typos and/or OCR mistakes. To overcome the challenges of our noisy training data, e.g. text extraction errors and/or typos and unknown label indices, we formulate the NER task as a text-to-text sequence generation task and train a pointer generator network to generate the entities in the document rather than label them. We show that the pointer generator can be effective for NER in the absence of gold standard data and outperforms the common NER neural network architectures in long legal documents.