 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartFreeEdit: Mask-Free Spatial-Aware Image Editing with Complex Instruction Understanding
Apr 17, 2025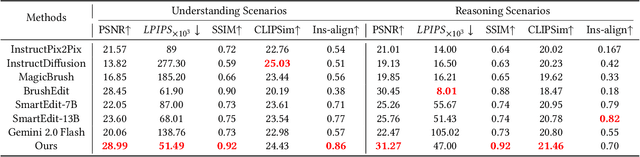

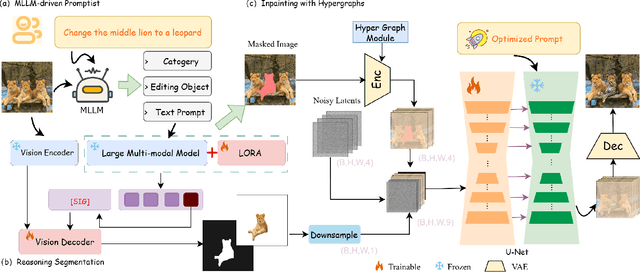
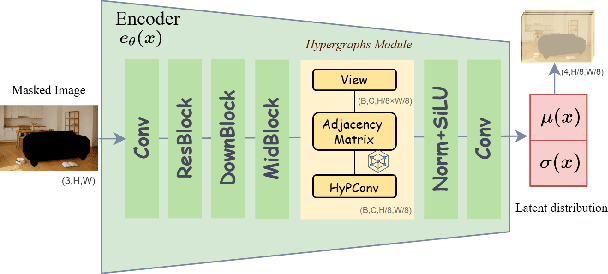
Recent advancements in image editing have utilized large-scale multimodal models to enable intuitive, natural instruction-driven interactions. However, conventional methods still face significant challenges, particularly in spatial reasoning, precise region segmentation, and maintaining semantic consistency, especially in complex scenes. To overcome these challenges, we introduce SmartFreeEdit, a novel end-to-end framework that integrates a multimodal large language model (MLLM) with a hypergraph-enhanced inpainting architecture, enabling precise, mask-free image editing guided exclusively by natural language instructions. The key innovations of SmartFreeEdit include:(1)the introduction of region aware tokens and a mask embedding paradigm that enhance the spatial understanding of complex scenes;(2) a reasoning segmentation pipeline designed to optimize the generation of editing masks based on natural language instructions;and (3) a hypergraph-augmented inpainting module that ensures the preservation of both structural integrity and semantic coherence during complex edits, overcoming the limitations of local-based image generation. Extensive experiments on the Reason-Edit benchmark demonstrate that SmartFreeEdit surpasses current state-of-the-art methods across multiple evaluation metrics, including segmentation accuracy, instruction adherence, and visual quality preservation, while addressing the issue of local information focus and improving global consistency in the edited image. Our project will be available at https://github.com/smileformylove/SmartFreeEdit.