 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Natural Language Instructions: Can Large Language Models Capture Spatial Information?
Sep 17, 2021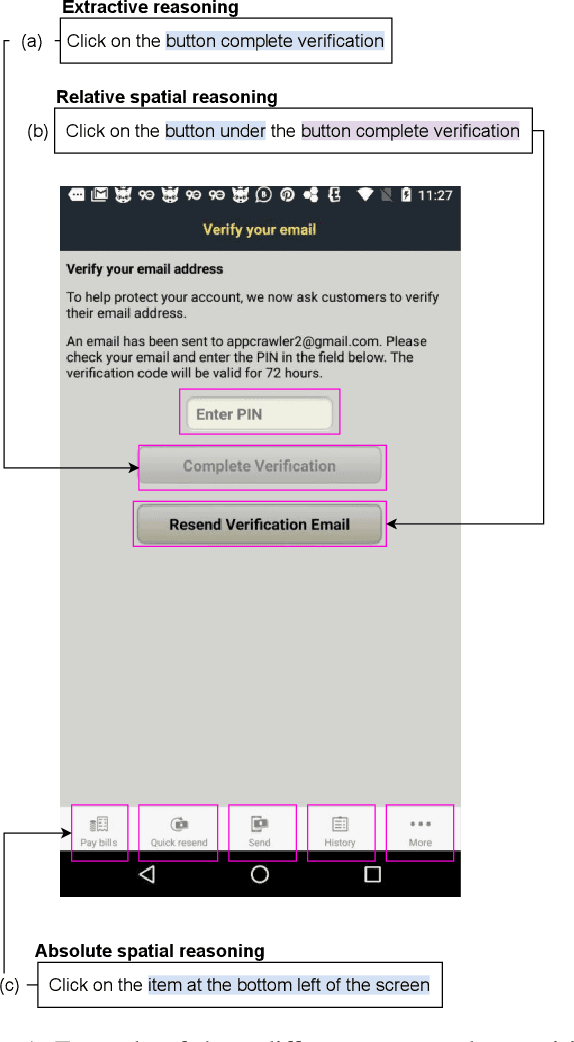
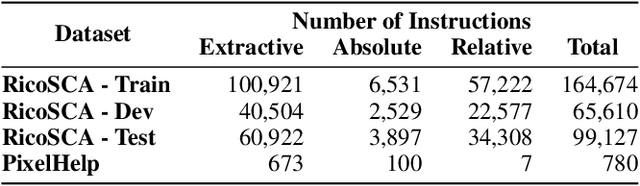
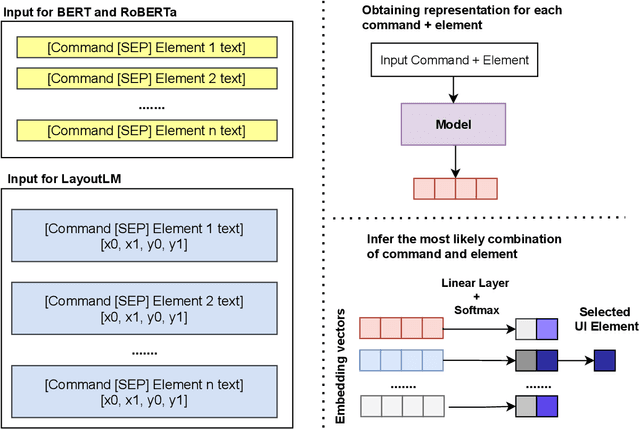
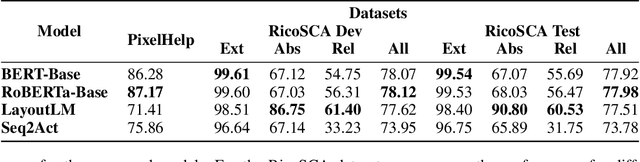
Models designed for intelligent process automation are required to be capable of grounding user interface elements. This task of interface element grounding is centred on linking instructions in natural language to their target referents. Even though BERT and similar pre-trained language models have excelled in several NLP tasks, their use has not been widely explored for the UI grounding domain. This work concentrates on testing and probing the grounding abilities of three different transformer-based models: BERT, RoBERTa and LayoutLM. Our primary focus is on these models' spatial reasoning skills, given their importance in this domain. We observe that LayoutLM has a promising advantage for applications in this domain, even though it was created for a different original purpose (representing scanned documents): the learned spatial features appear to be transferable to the UI grounding setting, especially as they demonstrate the ability to discriminate between target directions in natural language instructions.
SCRAM: Spatially Coherent Randomized Attention Maps
May 24, 2019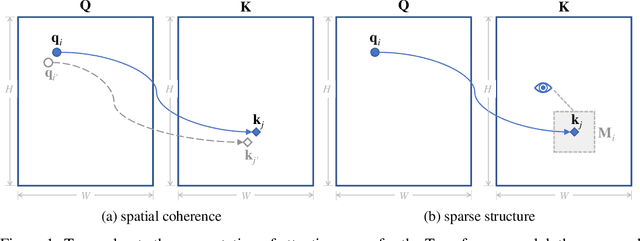
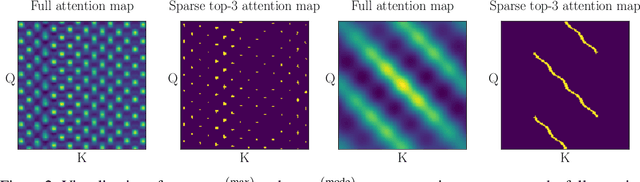
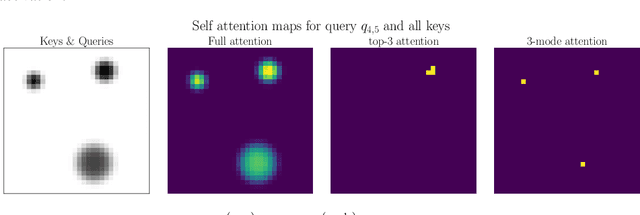
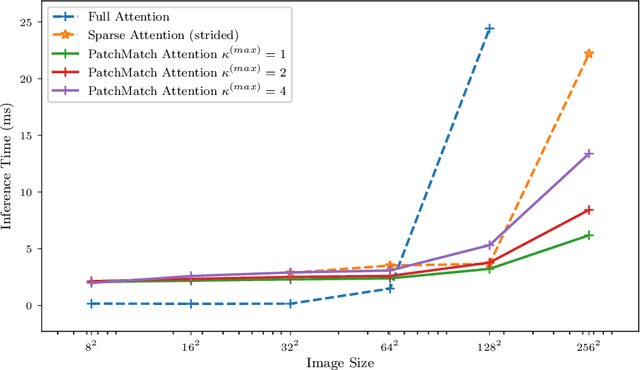
Attention mechanisms and non-local mean operations in general are key ingredients in many state-of-the-art deep learning techniques. In particular, the Transformer model based on multi-head self-attention has recently achieved great success in natural language processing and computer vision. However, the vanilla algorithm computing the Transformer of an image with n pixels has O(n^2) complexity, which is often painfully slow and sometimes prohibitively expensive for large-scale image data. In this paper, we propose a fast randomized algorithm --- SCRAM --- that only requires O(n log(n)) time to produce an image attention map. Such a dramatic acceleration is attributed to our insight that attention maps on real-world images usually exhibit (1) spatial coherence and (2) sparse structure. The central idea of SCRAM is to employ PatchMatch, a randomized correspondence algorithm, to quickly pinpoint the most compatible key (argmax) for each query first, and then exploit that knowledge to design a sparse approximation to non-local mean operations. Using the argmax (mode) to dynamically construct the sparse approximation distinguishes our algorithm from all of the existing sparse approximate methods and makes it very efficient. Moreover, SCRAM is a broadly applicable approximation to any non-local mean layer in contrast to some other sparse approximations that can only approximate self-attention. Our preliminary experimental results suggest that SCRAM is indeed promising for speeding up or scaling up the computation of attention maps in the Transformer.