 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the Causal Effects of Natural Logic Features in Transformer-Based NLI Models
Apr 03, 2024
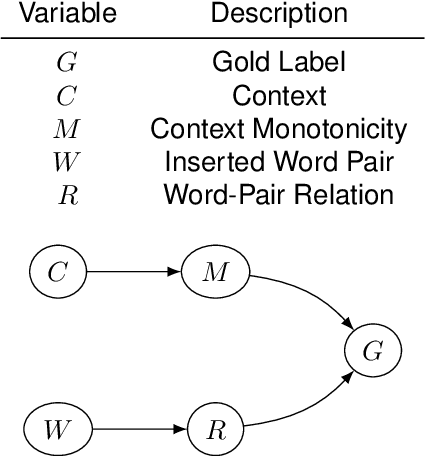
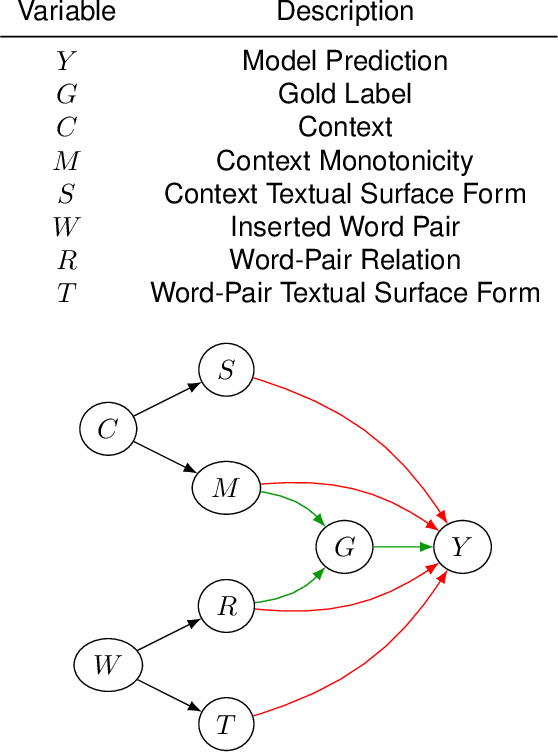

Rigorous evaluation of the causal effects of semantic features on language model predictions can be hard to achieve for natural language reasoning problems. However, this is such a desirable form of analysis from both an interpretability and model evaluation perspective, that it is valuable to investigate specific patterns of reasoning with enough structure and regularity to identify and quantify systematic reasoning failures in widely-used models. In this vein, we pick a portion of the NLI task for which an explicit causal diagram can be systematically constructed: the case where across two sentences (the premise and hypothesis), two related words/terms occur in a shared context. In this work, we apply causal effect estimation strategies to measure the effect of context interventions (whose effect on the entailment label is mediated by the semantic monotonicity characteristic) and interventions on the inserted word-pair (whose effect on the entailment label is mediated by the relation between these words). Extending related work on causal analysis of NLP models in different settings, we perform an extensive interventional study on the NLI task to investigate robustness to irrelevant changes and sensitivity to impactful changes of Transformers. The results strongly bolster the fact that similar benchmark accuracy scores may be observed for models that exhibit very different behaviour. Moreover, our methodology reinforces previously suspected biases from a causal perspective, including biases in favour of upward-monotone contexts and ignoring the effects of negation markers.
Estimating the Causal Effects of Natural Logic Features in Neural NLI Models
May 15, 2023Rigorous evaluation of the causal effects of semantic features on language model predictions can be hard to achieve for natural language reasoning problems. However, this is such a desirable form of analysis from both an interpretability and model evaluation perspective, that it is valuable to zone in on specific patterns of reasoning with enough structure and regularity to be able to identify and quantify systematic reasoning failures in widely-used models. In this vein, we pick a portion of the NLI task for which an explicit causal diagram can be systematically constructed: in particular, the case where across two sentences (the premise and hypothesis), two related words/terms occur in a shared context. In this work, we apply causal effect estimation strategies to measure the effect of context interventions (whose effect on the entailment label is mediated by the semantic monotonicity characteristic) and interventions on the inserted word-pair (whose effect on the entailment label is mediated by the relation between these words.). Following related work on causal analysis of NLP models in different settings, we adapt the methodology for the NLI task to construct comparative model profiles in terms of robustness to irrelevant changes and sensitivity to impactful changes.
Interventional Probing in High Dimensions: An NLI Case Study
Apr 20, 2023Probing strategies have been shown to detect the presence of various linguistic features in large language models; in particular, semantic features intermediate to the "natural logic" fragment of the Natural Language Inference task (NLI). In the case of natural logic, the relation between the intermediate features and the entailment label is explicitly known: as such, this provides a ripe setting for interventional studies on the NLI models' representations, allowing for stronger causal conjectures and a deeper critical analysis of interventional probing methods. In this work, we carry out new and existing representation-level interventions to investigate the effect of these semantic features on NLI classification: we perform amnesic probing (which removes features as directed by learned linear probes) and introduce the mnestic probing variation (which forgets all dimensions except the probe-selected ones). Furthermore, we delve into the limitations of these methods and outline some pitfalls have been obscuring the effectivity of interventional probing studies.
Systematicity, Compositionality and Transitivity of Deep NLP Models: a Metamorphic Testing Perspective
Apr 26, 2022
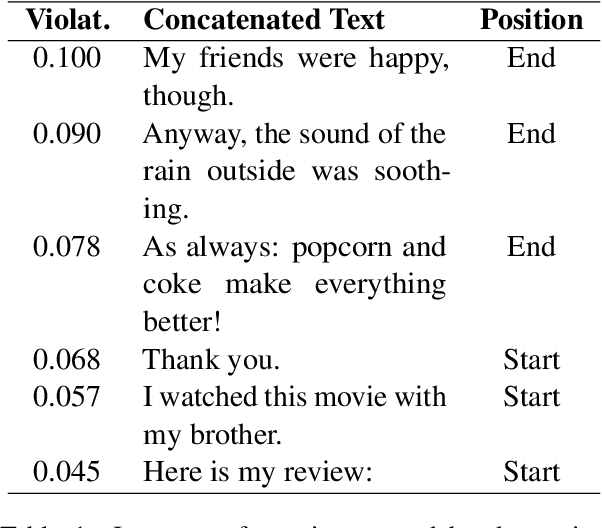


Metamorphic testing has recently been used to check the safety of neural NLP models. Its main advantage is that it does not rely on a ground truth to generate test cases. However, existing studies are mostly concerned with robustness-like metamorphic relations, limiting the scope of linguistic properties they can test. We propose three new classes of metamorphic relations, which address the properties of systematicity, compositionality and transitivity. Unlike robustness, our relations are defined over multiple source inputs, thus increasing the number of test cases that we can produce by a polynomial factor. With them, we test the internal consistency of state-of-the-art NLP models, and show that they do not always behave according to their expected linguistic properties. Lastly, we introduce a novel graphical notation that efficiently summarises the inner structure of metamorphic relations.
Decomposing Natural Logic Inferences in Neural NLI
Dec 15, 2021
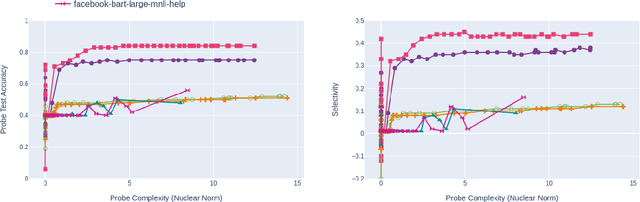
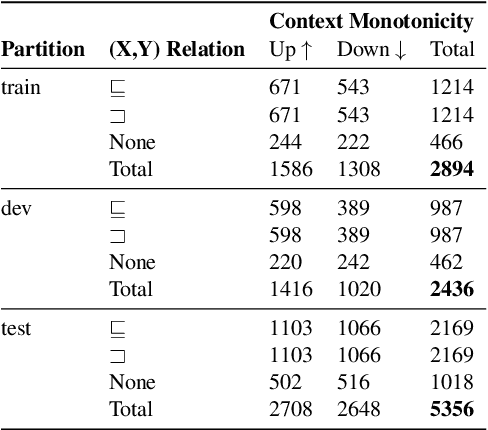
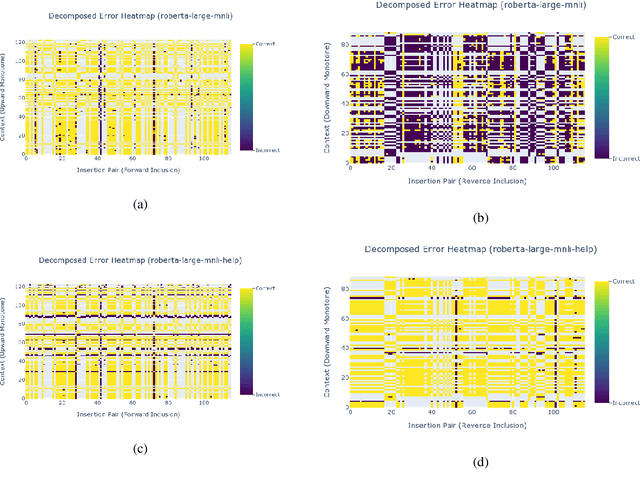
In the interest of interpreting neural NLI models and their reasoning strategies, we carry out a systematic probing study which investigates whether these models capture the crucial semantic features central to natural logic: monotonicity and concept inclusion. Correctly identifying valid inferences in downward-monotone contexts is a known stumbling block for NLI performance, subsuming linguistic phenomena such as negation scope and generalized quantifiers. To understand this difficulty, we emphasize monotonicity as a property of a context and examine the extent to which models capture monotonicity information in the contextual embeddings which are intermediate to their decision making process. Drawing on the recent advancement of the probing paradigm, we compare the presence of monotonicity features across various models. We find that monotonicity information is notably weak in the representations of popular NLI models which achieve high scores on benchmarks, and observe that previous improvements to these models based on fine-tuning strategies have introduced stronger monotonicity features together with their improved performance on challenge sets.
Grounding Natural Language Instructions: Can Large Language Models Capture Spatial Information?
Sep 17, 2021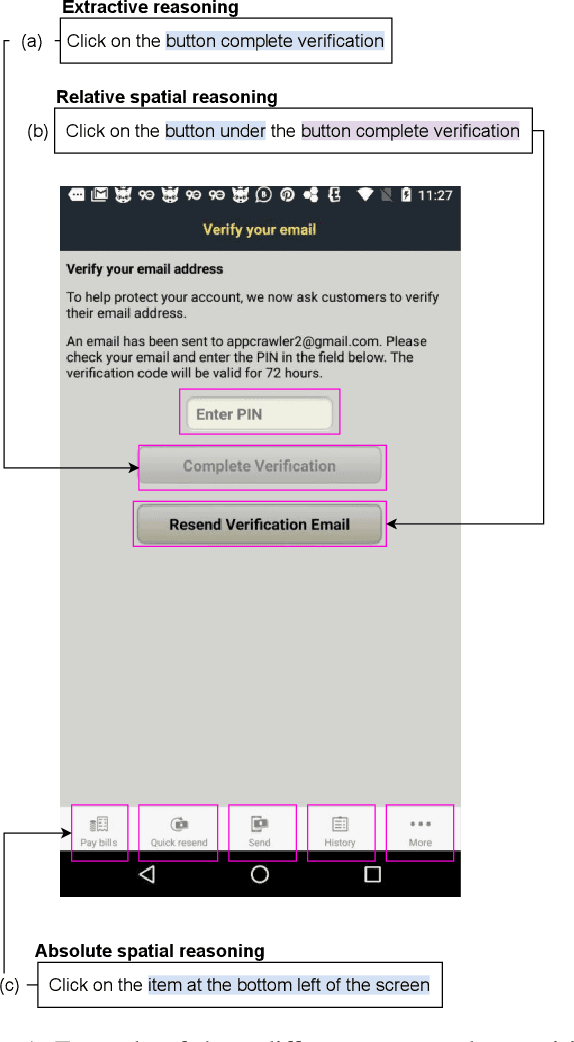
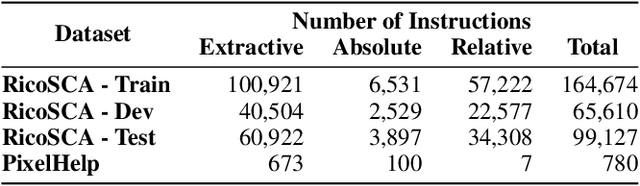
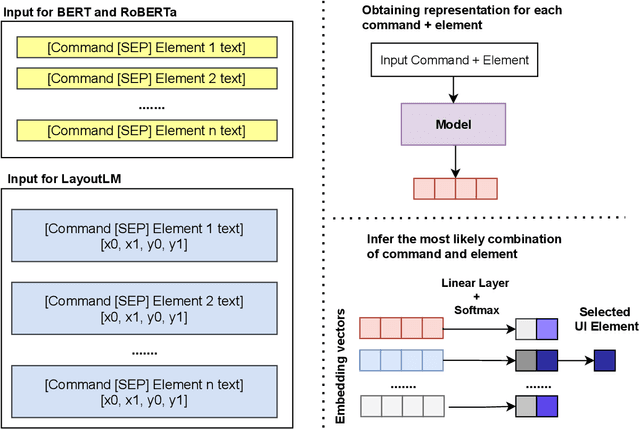
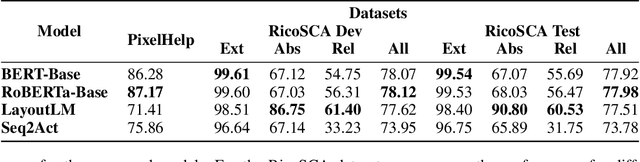
Models designed for intelligent process automation are required to be capable of grounding user interface elements. This task of interface element grounding is centred on linking instructions in natural language to their target referents. Even though BERT and similar pre-trained language models have excelled in several NLP tasks, their use has not been widely explored for the UI grounding domain. This work concentrates on testing and probing the grounding abilities of three different transformer-based models: BERT, RoBERTa and LayoutLM. Our primary focus is on these models' spatial reasoning skills, given their importance in this domain. We observe that LayoutLM has a promising advantage for applications in this domain, even though it was created for a different original purpose (representing scanned documents): the learned spatial features appear to be transferable to the UI grounding setting, especially as they demonstrate the ability to discriminate between target directions in natural language instructions.
Supporting Context Monotonicity Abstractions in Neural NLI Models
May 17, 2021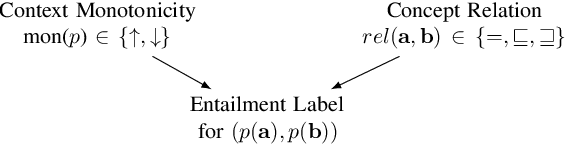

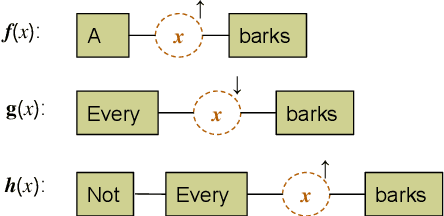

Natural language contexts display logical regularities with respect to substitutions of related concepts: these are captured in a functional order-theoretic property called monotonicity. For a certain class of NLI problems where the resulting entailment label depends only on the context monotonicity and the relation between the substituted concepts, we build on previous techniques that aim to improve the performance of NLI models for these problems, as consistent performance across both upward and downward monotone contexts still seems difficult to attain even for state-of-the-art models. To this end, we reframe the problem of context monotonicity classification to make it compatible with transformer-based pre-trained NLI models and add this task to the training pipeline. Furthermore, we introduce a sound and complete simplified monotonicity logic formalism which describes our treatment of contexts as abstract units. Using the notions in our formalism, we adapt targeted challenge sets to investigate whether an intermediate context monotonicity classification task can aid NLI models' performance on examples exhibiting monotonicity reasoning.
$\partial$-Explainer: Abductive Natural Language Inference via Differentiable Convex Optimization
May 07, 2021
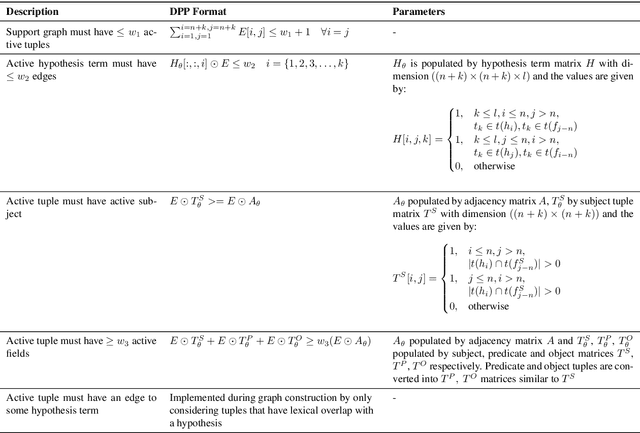
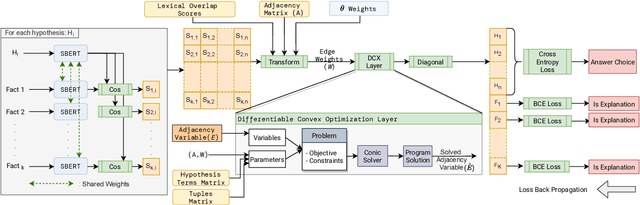
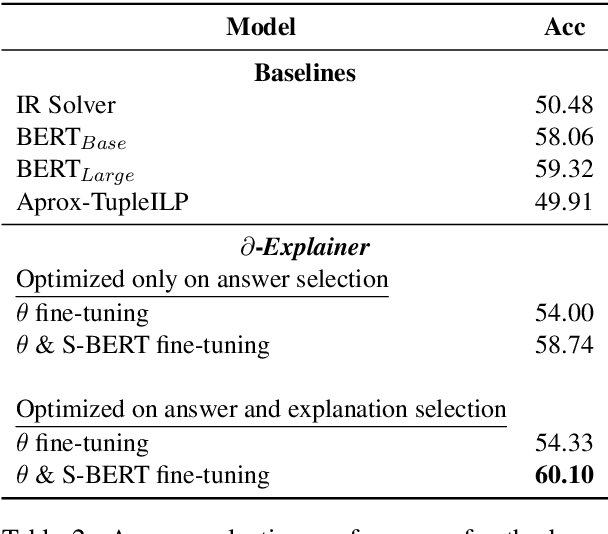
Constrained optimization solvers with Integer Linear programming (ILP) have been the cornerstone for explainable natural language inference during its inception. ILP based approaches provide a way to encode explicit and controllable assumptions casting natural language inference as an abductive reasoning problem, where the solver constructs a plausible explanation for a given hypothesis. While constrained based solvers provide explanations, they are often limited by the use of explicit constraints and cannot be integrated as part of broader deep neural architectures. In contrast, state-of-the-art transformer-based models can learn from data and implicitly encode complex constraints. However, these models are intrinsically black boxes. This paper presents a novel framework named $\partial$-Explainer (Diff-Explainer) that combines the best of both worlds by casting the constrained optimization as part of a deep neural network via differentiable convex optimization and fine-tuning pre-trained transformers for downstream explainable NLP tasks. To demonstrate the efficacy of the framework, we transform the constraints presented by TupleILP and integrate them with sentence embedding transformers for the task of explainable science QA. Our experiments show up to $\approx 10\%$ improvement over non-differentiable solver while still providing explanations for supporting its inference.
Does My Representation Capture X? Probe-Ably
Apr 12, 2021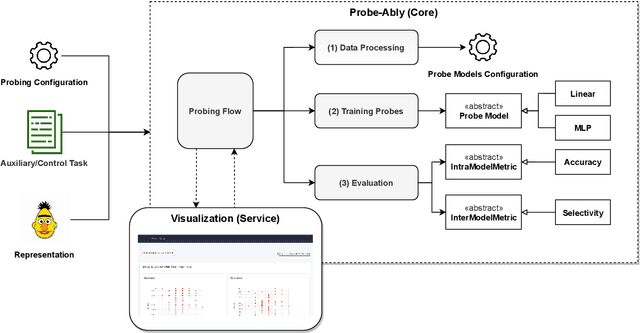
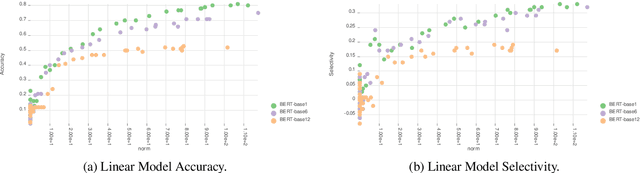
Probing (or diagnostic classification) has become a popular strategy for investigating whether a given set of intermediate features is present in the representations of neural models. Naive probing studies may have misleading results, but various recent works have suggested more reliable methodologies that compensate for the possible pitfalls of probing. However, these best practices are numerous and fast-evolving. To simplify the process of running a set of probing experiments in line with suggested methodologies, we introduce Probe-Ably: an extendable probing framework which supports and automates the application of probing methods to the user's inputs