 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroCLIP: A Multimodal Contrastive Learning Method for rTMS-treated Methamphetamine Addiction Analysis
Jul 27, 2025Methamphetamine dependence poses a significant global health challenge, yet its assessment and the evaluation of treatments like repetitive transcranial magnetic stimulation (rTMS) frequently depend on subjective self-reports, which may introduce uncertainties. While objective neuroimaging modalities such as electroencephalography (EEG) and functional near-infrared spectroscopy (fNIRS) offer alternatives, their individual limitations and the reliance on conventional, often hand-crafted, feature extraction can compromise the reliability of derived biomarkers. To overcome these limitations, we propose NeuroCLIP, a novel deep learning framework integrating simultaneously recorded EEG and fNIRS data through a progressive learning strategy. This approach offers a robust and trustworthy biomarker for methamphetamine addiction. Validation experiments show that NeuroCLIP significantly improves discriminative capabilities among the methamphetamine-dependent individuals and healthy controls compared to models using either EEG or only fNIRS alone. Furthermore, the proposed framework facilitates objective, brain-based evaluation of rTMS treatment efficacy, demonstrating measurable shifts in neural patterns towards healthy control profiles after treatment. Critically, we establish the trustworthiness of the multimodal data-driven biomarker by showing its strong correlation with psychometrically validated craving scores. These findings suggest that biomarker derived from EEG-fNIRS data via NeuroCLIP offers enhanced robustness and reliability over single-modality approaches, providing a valuable tool for addiction neuroscience research and potentially improving clinical assessments.
Retrieve, Annotate, Evaluate, Repeat: Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation
Sep 18, 2024



Evaluating production-level retrieval systems at scale is a crucial yet challenging task due to the limited availability of a large pool of well-trained human annotators. Large Language Models (LLMs) have the potential to address this scaling issue and offer a viable alternative to humans for the bulk of annotation tasks. In this paper, we propose a framework for assessing the product search engines in a large-scale e-commerce setting, leveraging Multimodal LLMs for (i) generating tailored annotation guidelines for individual queries, and (ii) conducting the subsequent annotation task. Our method, validated through deployment on a large e-commerce platform, demonstrates comparable quality to human annotations, significantly reduces time and cost, facilitates rapid problem discovery, and provides an effective solution for production-level quality control at scale.
What should I wear to a party in a Greek taverna? Evaluation for Conversational Agents in the Fashion Domain
Aug 13, 2024



Large language models (LLMs) are poised to revolutionize the domain of online fashion retail, enhancing customer experience and discovery of fashion online. LLM-powered conversational agents introduce a new way of discovery by directly interacting with customers, enabling them to express in their own ways, refine their needs, obtain fashion and shopping advice that is relevant to their taste and intent. For many tasks in e-commerce, such as finding a specific product, conversational agents need to convert their interactions with a customer to a specific call to different backend systems, e.g., a search system to showcase a relevant set of products. Therefore, evaluating the capabilities of LLMs to perform those tasks related to calling other services is vital. However, those evaluations are generally complex, due to the lack of relevant and high quality datasets, and do not align seamlessly with business needs, amongst others. To this end, we created a multilingual evaluation dataset of 4k conversations between customers and a fashion assistant in a large e-commerce fashion platform to measure the capabilities of LLMs to serve as an assistant between customers and a backend engine. We evaluate a range of models, showcasing how our dataset scales to business needs and facilitates iterative development of tools.
Grounding Natural Language Instructions: Can Large Language Models Capture Spatial Information?
Sep 17, 2021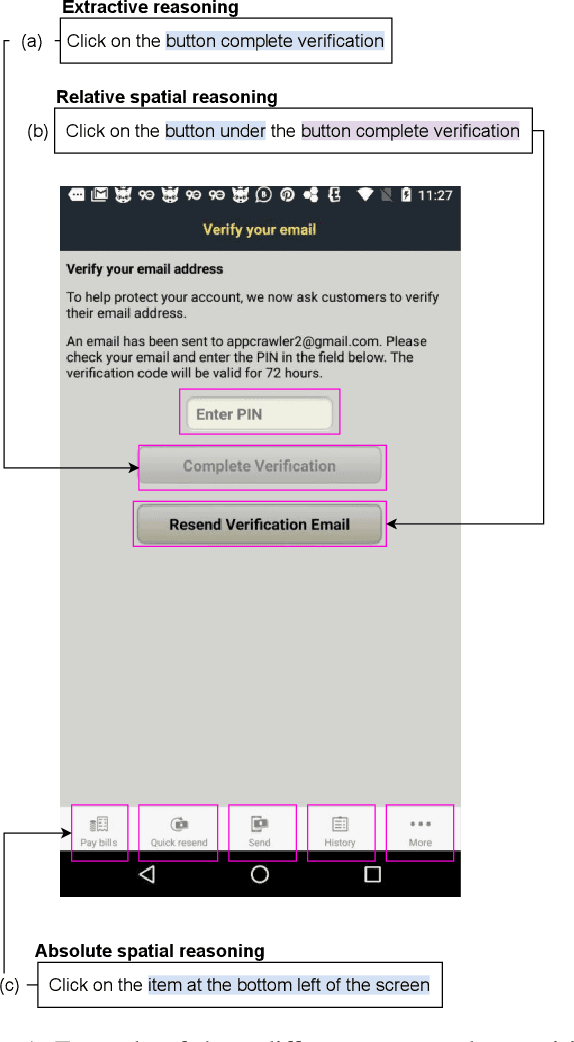
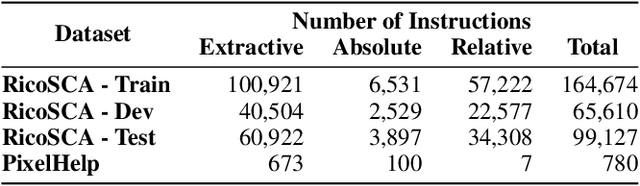
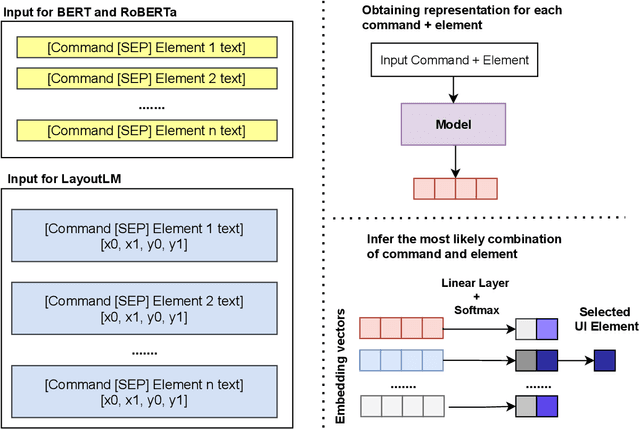
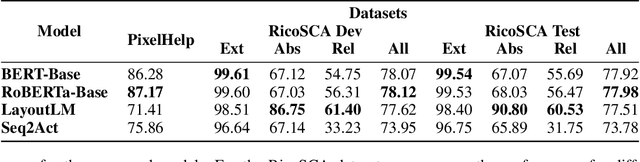
Models designed for intelligent process automation are required to be capable of grounding user interface elements. This task of interface element grounding is centred on linking instructions in natural language to their target referents. Even though BERT and similar pre-trained language models have excelled in several NLP tasks, their use has not been widely explored for the UI grounding domain. This work concentrates on testing and probing the grounding abilities of three different transformer-based models: BERT, RoBERTa and LayoutLM. Our primary focus is on these models' spatial reasoning skills, given their importance in this domain. We observe that LayoutLM has a promising advantage for applications in this domain, even though it was created for a different original purpose (representing scanned documents): the learned spatial features appear to be transferable to the UI grounding setting, especially as they demonstrate the ability to discriminate between target directions in natural language instructions.
Evaluating for Diversity in Question Generation over Text
Aug 17, 2020
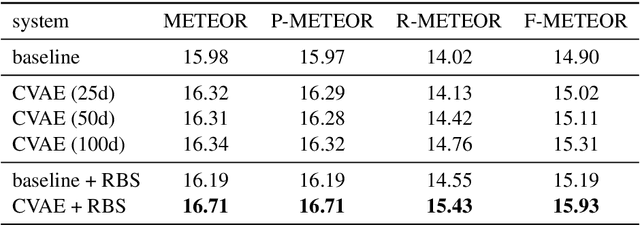
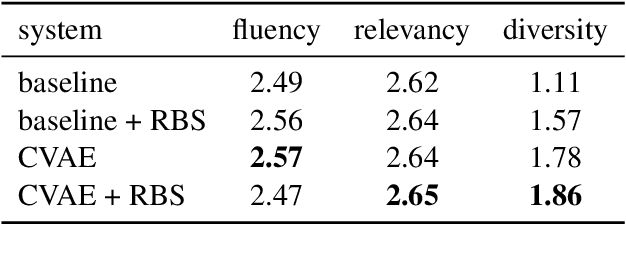
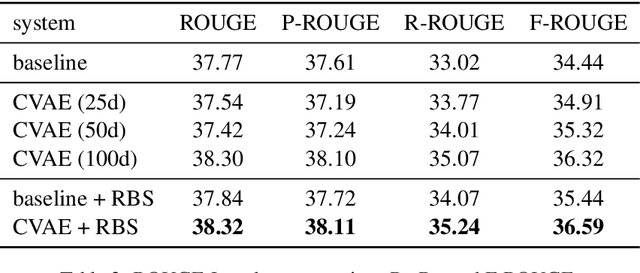
Generating diverse and relevant questions over text is a task with widespread applications. We argue that commonly-used evaluation metrics such as BLEU and METEOR are not suitable for this task due to the inherent diversity of reference questions, and propose a scheme for extending conventional metrics to reflect diversity. We furthermore propose a variational encoder-decoder model for this task. We show through automatic and human evaluation that our variational model improves diversity without loss of quality, and demonstrate how our evaluation scheme reflects this improvement.
On the Bayes-optimality of F-measure maximizers
Mar 06, 2015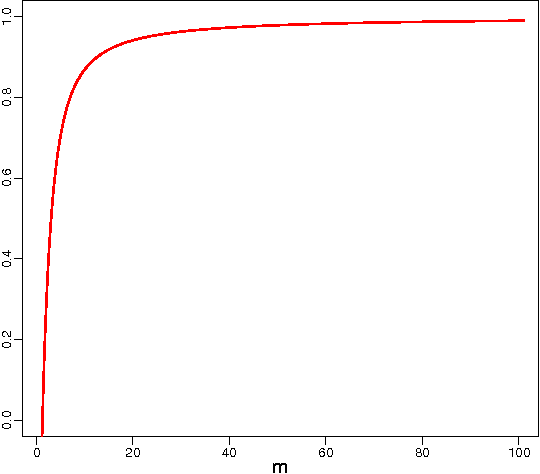

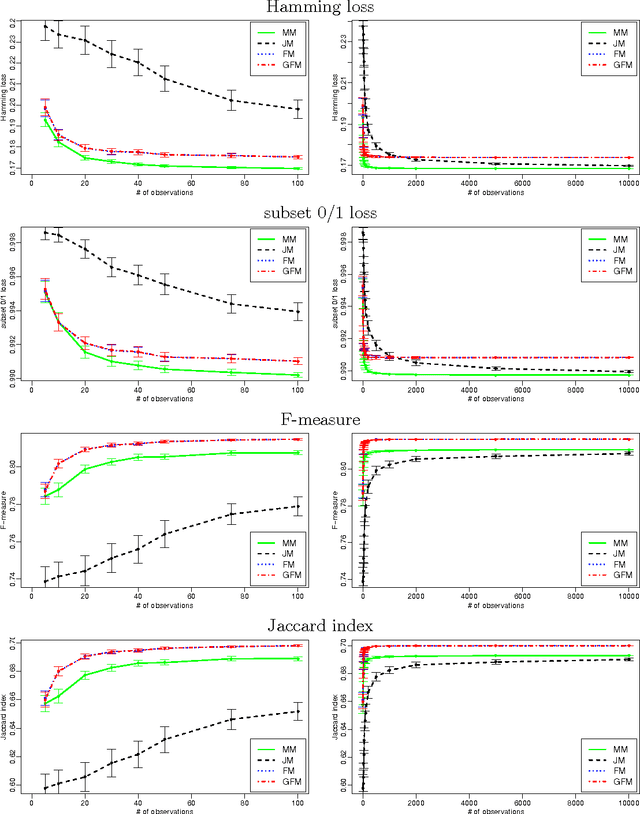
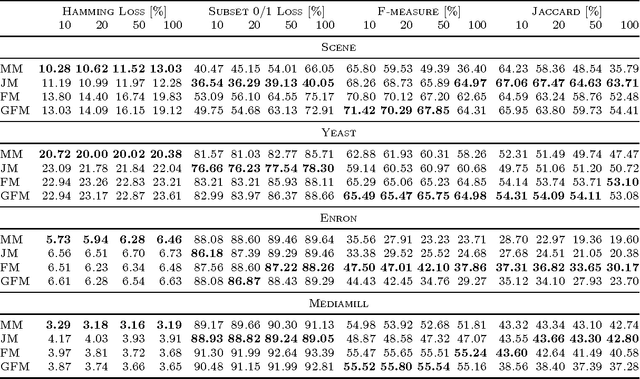
The F-measure, which has originally been introduced in information retrieval, is nowadays routinely used as a performance metric for problems such as binary classification, multi-label classification, and structured output prediction. Optimizing this measure is a statistically and computationally challenging problem, since no closed-form solution exists. Adopting a decision-theoretic perspective, this article provides a formal and experimental analysis of different approaches for maximizing the F-measure. We start with a Bayes-risk analysis of related loss functions, such as Hamming loss and subset zero-one loss, showing that optimizing such losses as a surrogate of the F-measure leads to a high worst-case regret. Subsequently, we perform a similar type of analysis for F-measure maximizing algorithms, showing that such algorithms are approximate, while relying on additional assumptions regarding the statistical distribution of the binary response variables. Furthermore, we present a new algorithm which is not only computationally efficient but also Bayes-optimal, regardless of the underlying distribution. To this end, the algorithm requires only a quadratic (with respect to the number of binary responses) number of parameters of the joint distribution. We illustrate the practical performance of all analyzed methods by means of experiments with multi-label classification problems.
Label Ranking with Abstention: Predicting Partial Orders by Thresholding Probability Distributions (Extended Abstract)
Dec 02, 2011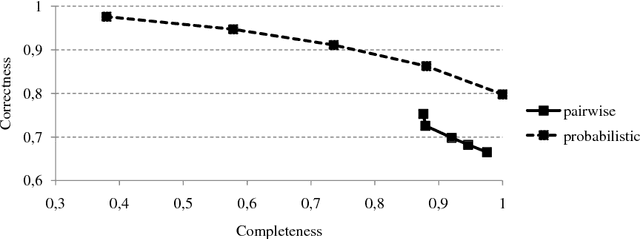
We consider an extension of the setting of label ranking, in which the learner is allowed to make predictions in the form of partial instead of total orders. Predictions of that kind are interpreted as a partial abstention: If the learner is not sufficiently certain regarding the relative order of two alternatives, it may abstain from this decision and instead declare these alternatives as being incomparable. We propose a new method for learning to predict partial orders that improves on an existing approach, both theoretically and empirically. Our method is based on the idea of thresholding the probabilities of pairwise preferences between labels as induced by a predicted (parameterized) probability distribution on the set of all rankings.