Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating for Diversity in Question Generation over Text
Paper and Code
Aug 17, 2020
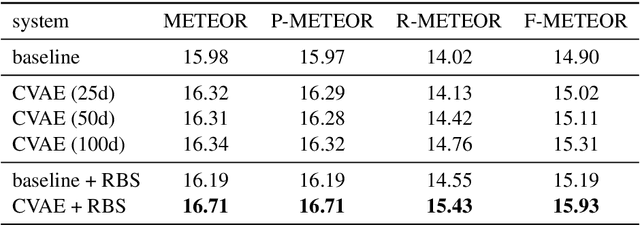
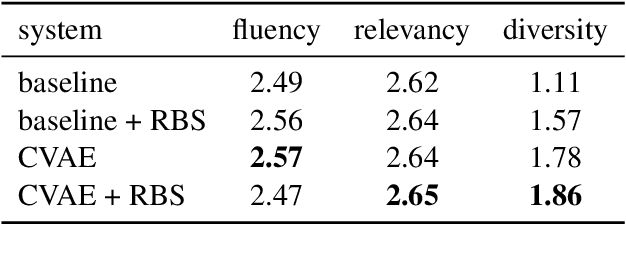
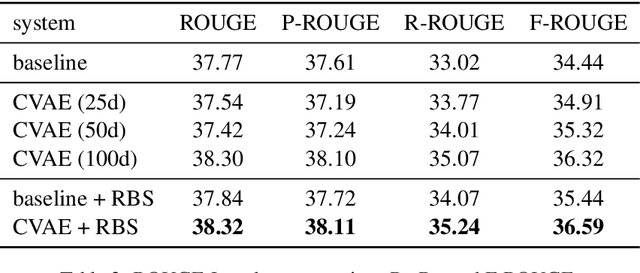
Generating diverse and relevant questions over text is a task with widespread applications. We argue that commonly-used evaluation metrics such as BLEU and METEOR are not suitable for this task due to the inherent diversity of reference questions, and propose a scheme for extending conventional metrics to reflect diversity. We furthermore propose a variational encoder-decoder model for this task. We show through automatic and human evaluation that our variational model improves diversity without loss of quality, and demonstrate how our evaluation scheme reflects this improvement.
View paper on