 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIYKYK: Using language models to decode extremist cryptolects
Jun 05, 2025Extremist groups develop complex in-group language, also referred to as cryptolects, to exclude or mislead outsiders. We investigate the ability of current language technologies to detect and interpret the cryptolects of two online extremist platforms. Evaluating eight models across six tasks, our results indicate that general purpose LLMs cannot consistently detect or decode extremist language. However, performance can be significantly improved by domain adaptation and specialised prompting techniques. These results provide important insights to inform the development and deployment of automated moderation technologies. We further develop and release novel labelled and unlabelled datasets, including 19.4M posts from extremist platforms and lexicons validated by human experts.
Interpreting Graph Neural Networks for NLP With Differentiable Edge Masking
Oct 01, 2020Graph neural networks (GNNs) have become a popular approach to integrating structural inductive biases into NLP models. However, there has been little work on interpreting them, and specifically on understanding which parts of the graphs (e.g. syntactic trees or co-reference structures) contribute to a prediction. In this work, we introduce a post-hoc method for interpreting the predictions of GNNs which identifies unnecessary edges. Given a trained GNN model, we learn a simple classifier that, for every edge in every layer, predicts if that edge can be dropped. We demonstrate that such a classifier can be trained in a fully differentiable fashion, employing stochastic gates and encouraging sparsity through the expected $L_0$ norm. We use our technique as an attribution method to analyze GNN models for two tasks -- question answering and semantic role labeling -- providing insights into the information flow in these models. We show that we can drop a large proportion of edges without deteriorating the performance of the model, while we can analyse the remaining edges for interpreting model predictions.
Evaluating for Diversity in Question Generation over Text
Aug 17, 2020
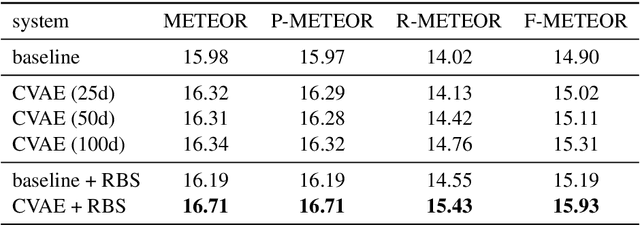
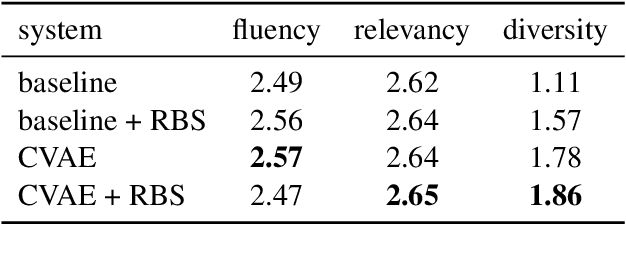
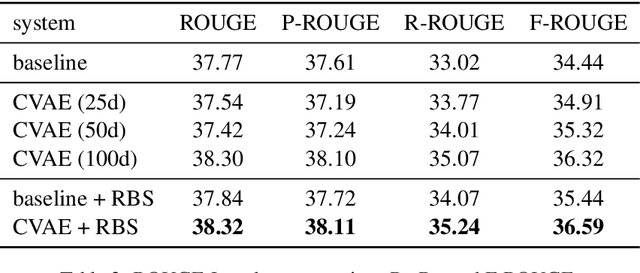
Generating diverse and relevant questions over text is a task with widespread applications. We argue that commonly-used evaluation metrics such as BLEU and METEOR are not suitable for this task due to the inherent diversity of reference questions, and propose a scheme for extending conventional metrics to reflect diversity. We furthermore propose a variational encoder-decoder model for this task. We show through automatic and human evaluation that our variational model improves diversity without loss of quality, and demonstrate how our evaluation scheme reflects this improvement.
Cross-Lingual Dependency Parsing with Late Decoding for Truly Low-Resource Languages
Jan 06, 2017



In cross-lingual dependency annotation projection, information is often lost during transfer because of early decoding. We present an end-to-end graph-based neural network dependency parser that can be trained to reproduce matrices of edge scores, which can be directly projected across word alignments. We show that our approach to cross-lingual dependency parsing is not only simpler, but also achieves an absolute improvement of 2.25% averaged across 10 languages compared to the previous state of the art.