 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIYKYK: Using language models to decode extremist cryptolects
Jun 05, 2025Extremist groups develop complex in-group language, also referred to as cryptolects, to exclude or mislead outsiders. We investigate the ability of current language technologies to detect and interpret the cryptolects of two online extremist platforms. Evaluating eight models across six tasks, our results indicate that general purpose LLMs cannot consistently detect or decode extremist language. However, performance can be significantly improved by domain adaptation and specialised prompting techniques. These results provide important insights to inform the development and deployment of automated moderation technologies. We further develop and release novel labelled and unlabelled datasets, including 19.4M posts from extremist platforms and lexicons validated by human experts.
Improving Neural Model Performance through Natural Language Feedback on Their Explanations
Apr 18, 2021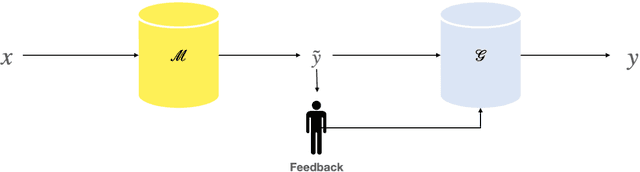


A class of explainable NLP models for reasoning tasks support their decisions by generating free-form or structured explanations, but what happens when these supporting structures contain errors? Our goal is to allow users to interactively correct explanation structures through natural language feedback. We introduce MERCURIE - an interactive system that refines its explanations for a given reasoning task by getting human feedback in natural language. Our approach generates graphs that have 40% fewer inconsistencies as compared with the off-the-shelf system. Further, simply appending the corrected explanation structures to the output leads to a gain of 1.2 points on accuracy on defeasible reasoning across all three domains. We release a dataset of over 450k graphs for defeasible reasoning generated by our system at https://tinyurl.com/mercurie .