 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers and the representation of biomedical background knowledge
Feb 04, 2022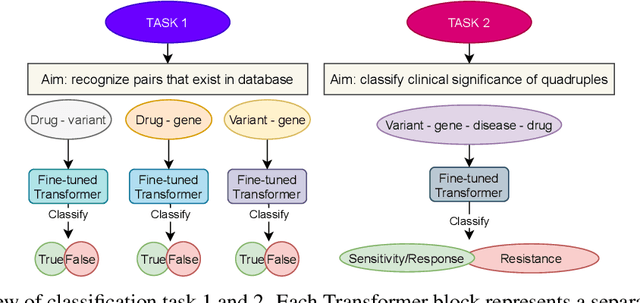

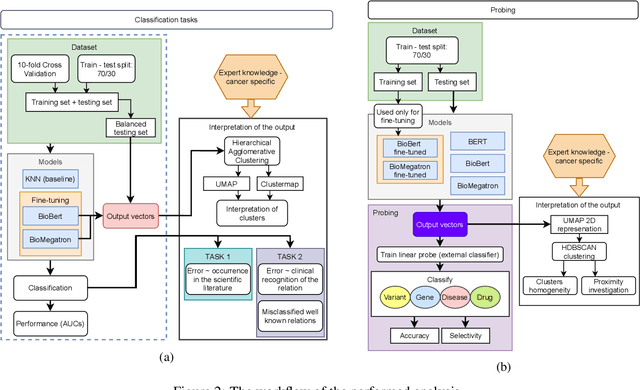
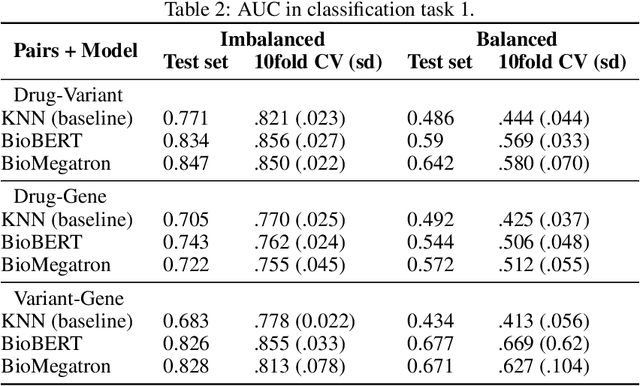
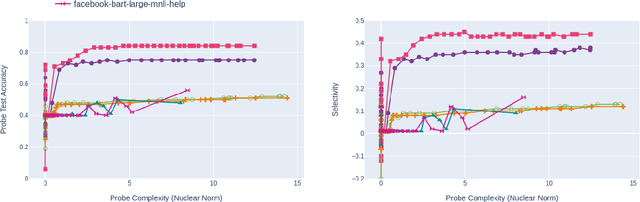
BioBERT and BioMegatron are Transformers models adapted for the biomedical domain based on publicly available biomedical corpora. As such, they have the potential to encode large-scale biological knowledge. We investigate the encoding and representation of biological knowledge in these models, and its potential utility to support inference in cancer precision medicine - namely, the interpretation of the clinical significance of genomic alterations. We compare the performance of different transformer baselines; we use probing to determine the consistency of encodings for distinct entities; and we use clustering methods to compare and contrast the internal properties of the embeddings for genes, variants, drugs and diseases. We show that these models do indeed encode biological knowledge, although some of this is lost in fine-tuning for specific tasks. Finally, we analyse how the models behave with regard to biases and imbalances in the dataset.
Decomposing Natural Logic Inferences in Neural NLI
Dec 15, 2021
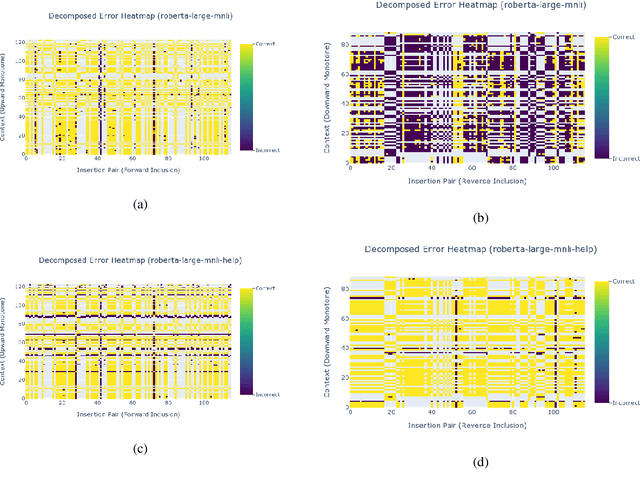
In the interest of interpreting neural NLI models and their reasoning strategies, we carry out a systematic probing study which investigates whether these models capture the crucial semantic features central to natural logic: monotonicity and concept inclusion. Correctly identifying valid inferences in downward-monotone contexts is a known stumbling block for NLI performance, subsuming linguistic phenomena such as negation scope and generalized quantifiers. To understand this difficulty, we emphasize monotonicity as a property of a context and examine the extent to which models capture monotonicity information in the contextual embeddings which are intermediate to their decision making process. Drawing on the recent advancement of the probing paradigm, we compare the presence of monotonicity features across various models. We find that monotonicity information is notably weak in the representations of popular NLI models which achieve high scores on benchmarks, and observe that previous improvements to these models based on fine-tuning strategies have introduced stronger monotonicity features together with their improved performance on challenge sets.
Grounding Natural Language Instructions: Can Large Language Models Capture Spatial Information?
Sep 17, 2021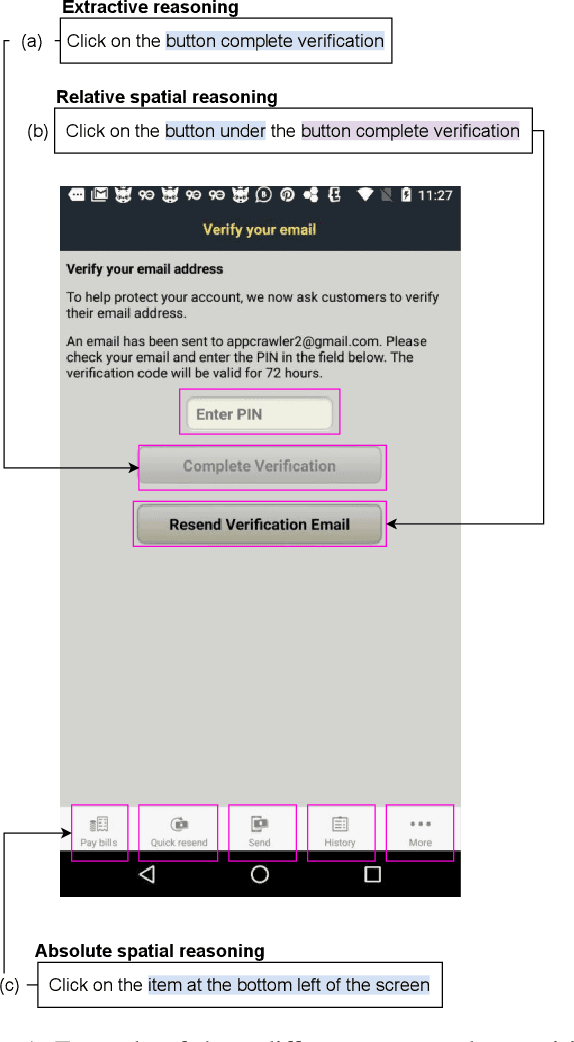
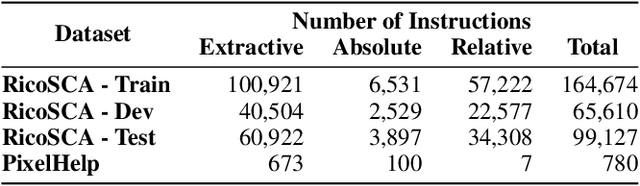
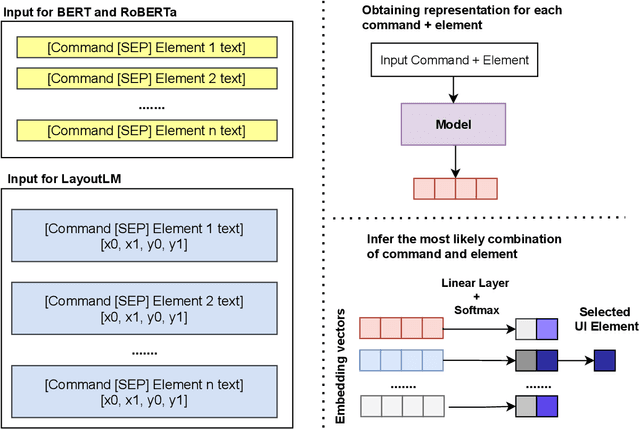
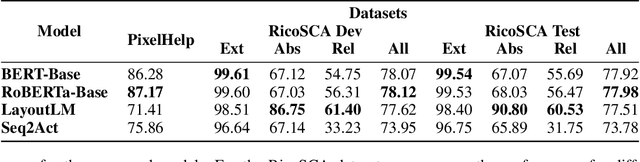
Models designed for intelligent process automation are required to be capable of grounding user interface elements. This task of interface element grounding is centred on linking instructions in natural language to their target referents. Even though BERT and similar pre-trained language models have excelled in several NLP tasks, their use has not been widely explored for the UI grounding domain. This work concentrates on testing and probing the grounding abilities of three different transformer-based models: BERT, RoBERTa and LayoutLM. Our primary focus is on these models' spatial reasoning skills, given their importance in this domain. We observe that LayoutLM has a promising advantage for applications in this domain, even though it was created for a different original purpose (representing scanned documents): the learned spatial features appear to be transferable to the UI grounding setting, especially as they demonstrate the ability to discriminate between target directions in natural language instructions.
Hybrid Autoregressive Solver for Scalable Abductive Natural Language Inference
Jul 25, 2021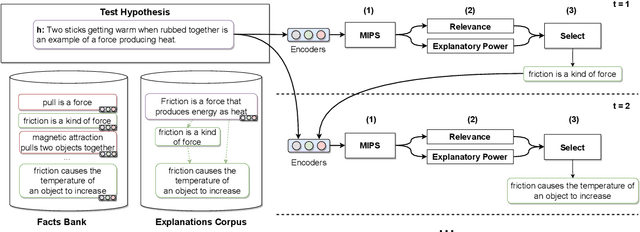

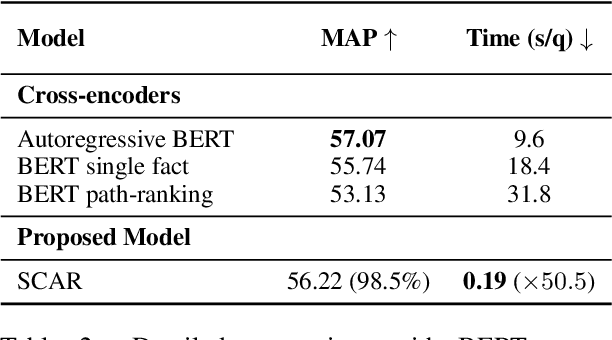
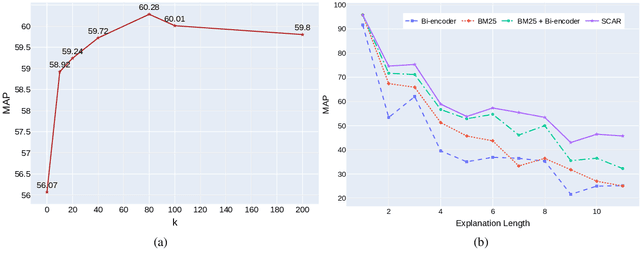
Regenerating natural language explanations for science questions is a challenging task for evaluating complex multi-hop and abductive inference capabilities. In this setting, Transformers trained on human-annotated explanations achieve state-of-the-art performance when adopted as cross-encoder architectures. However, while much attention has been devoted to the quality of the constructed explanations, the problem of performing abductive inference at scale is still under-studied. As intrinsically not scalable, the cross-encoder architectural paradigm is not suitable for efficient multi-hop inference on massive facts banks. To maximise both accuracy and inference time, we propose a hybrid abductive solver that autoregressively combines a dense bi-encoder with a sparse model of explanatory power, computed leveraging explicit patterns in the explanations. Our experiments demonstrate that the proposed framework can achieve performance comparable with the state-of-the-art cross-encoder while being $\approx 50$ times faster and scalable to corpora of millions of facts. Moreover, we study the impact of the hybridisation on semantic drift and science question answering without additional training, showing that it boosts the quality of the explanations and contributes to improved downstream inference performance.
Supporting Context Monotonicity Abstractions in Neural NLI Models
May 17, 2021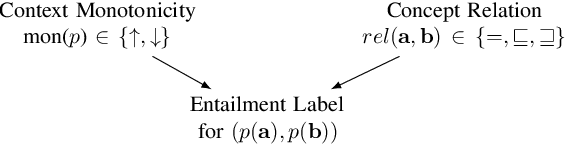

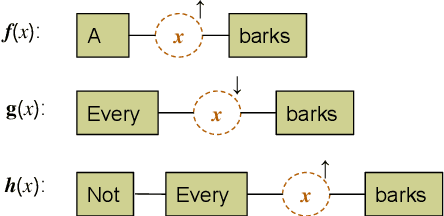

Natural language contexts display logical regularities with respect to substitutions of related concepts: these are captured in a functional order-theoretic property called monotonicity. For a certain class of NLI problems where the resulting entailment label depends only on the context monotonicity and the relation between the substituted concepts, we build on previous techniques that aim to improve the performance of NLI models for these problems, as consistent performance across both upward and downward monotone contexts still seems difficult to attain even for state-of-the-art models. To this end, we reframe the problem of context monotonicity classification to make it compatible with transformer-based pre-trained NLI models and add this task to the training pipeline. Furthermore, we introduce a sound and complete simplified monotonicity logic formalism which describes our treatment of contexts as abstract units. Using the notions in our formalism, we adapt targeted challenge sets to investigate whether an intermediate context monotonicity classification task can aid NLI models' performance on examples exhibiting monotonicity reasoning.
$\partial$-Explainer: Abductive Natural Language Inference via Differentiable Convex Optimization
May 07, 2021
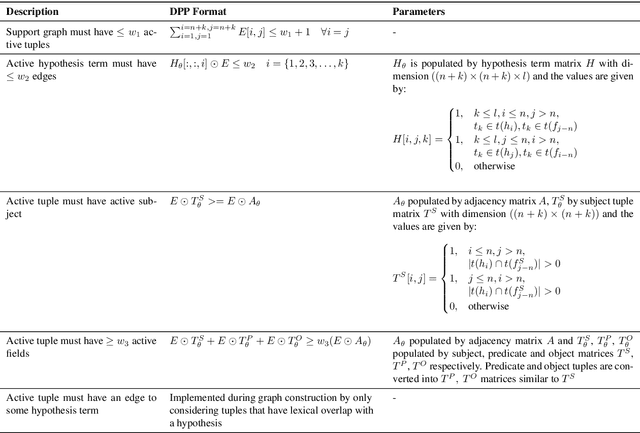
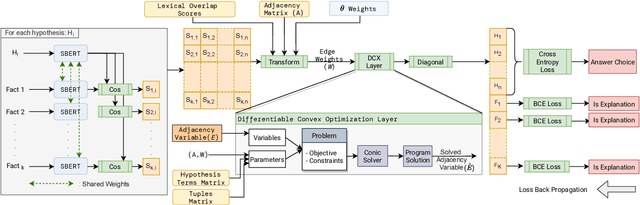
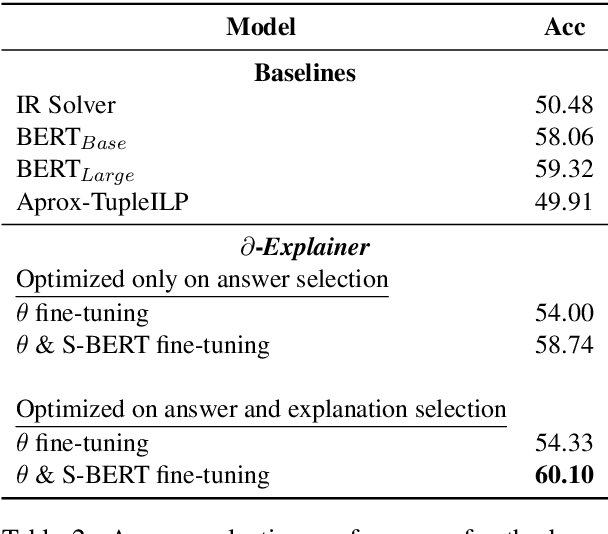
Constrained optimization solvers with Integer Linear programming (ILP) have been the cornerstone for explainable natural language inference during its inception. ILP based approaches provide a way to encode explicit and controllable assumptions casting natural language inference as an abductive reasoning problem, where the solver constructs a plausible explanation for a given hypothesis. While constrained based solvers provide explanations, they are often limited by the use of explicit constraints and cannot be integrated as part of broader deep neural architectures. In contrast, state-of-the-art transformer-based models can learn from data and implicitly encode complex constraints. However, these models are intrinsically black boxes. This paper presents a novel framework named $\partial$-Explainer (Diff-Explainer) that combines the best of both worlds by casting the constrained optimization as part of a deep neural network via differentiable convex optimization and fine-tuning pre-trained transformers for downstream explainable NLP tasks. To demonstrate the efficacy of the framework, we transform the constraints presented by TupleILP and integrate them with sentence embedding transformers for the task of explainable science QA. Our experiments show up to $\approx 10\%$ improvement over non-differentiable solver while still providing explanations for supporting its inference.
Does My Representation Capture X? Probe-Ably
Apr 12, 2021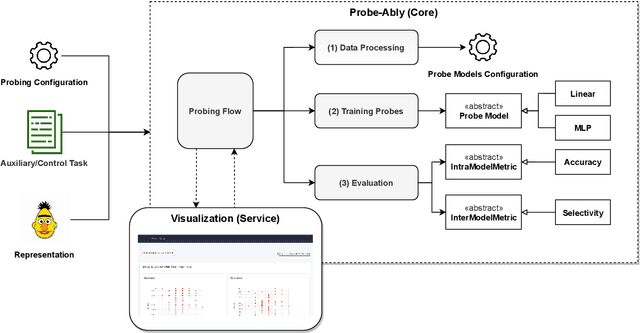
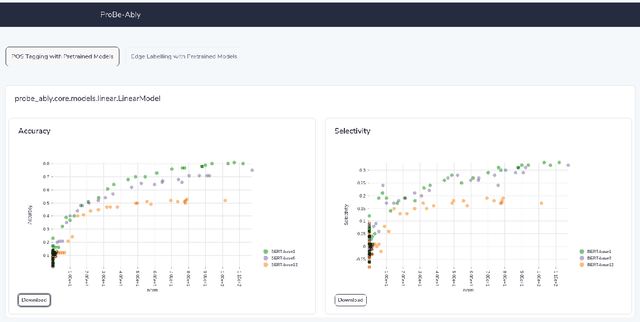
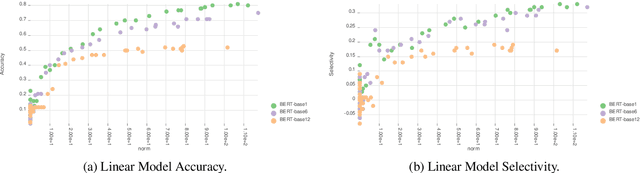
Probing (or diagnostic classification) has become a popular strategy for investigating whether a given set of intermediate features is present in the representations of neural models. Naive probing studies may have misleading results, but various recent works have suggested more reliable methodologies that compensate for the possible pitfalls of probing. However, these best practices are numerous and fast-evolving. To simplify the process of running a set of probing experiments in line with suggested methodologies, we introduce Probe-Ably: an extendable probing framework which supports and automates the application of probing methods to the user's inputs
Natural Language Premise Selection: Finding Supporting Statements for Mathematical Text
Apr 30, 2020


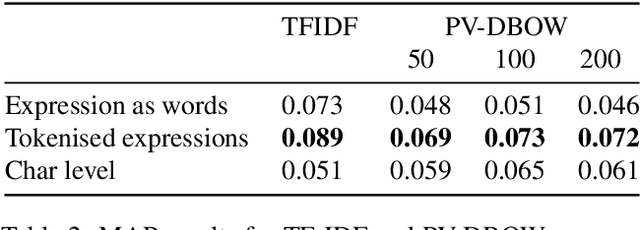
Mathematical text is written using a combination of words and mathematical expressions. This combination, along with a specific way of structuring sentences makes it challenging for state-of-art NLP tools to understand and reason on top of mathematical discourse. In this work, we propose a new NLP task, the natural premise selection, which is used to retrieve supporting definitions and supporting propositions that are useful for generating an informal mathematical proof for a particular statement. We also make available a dataset, NL-PS, which can be used to evaluate different approaches for the natural premise selection task. Using different baselines, we demonstrate the underlying interpretation challenges associated with the task.