 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive entailment encoding for explanation tree construction using parsimonious generation of hard negatives
Aug 02, 2022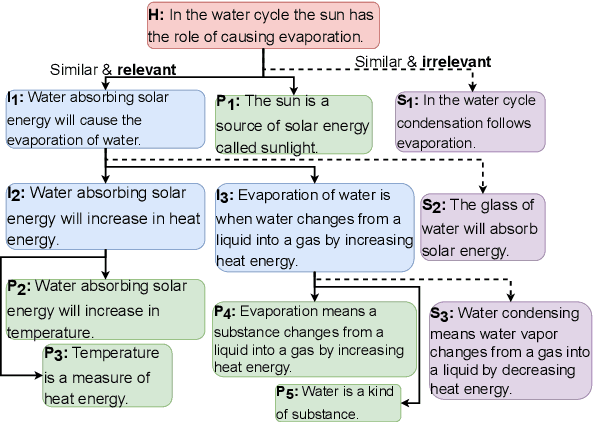
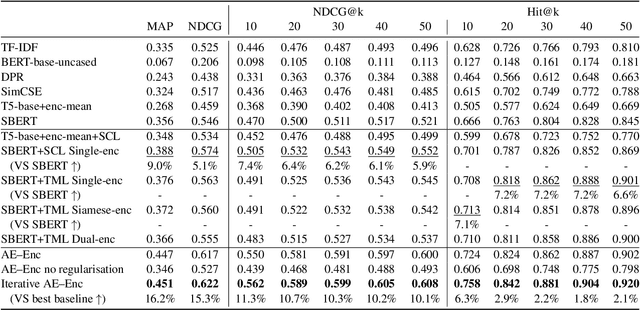
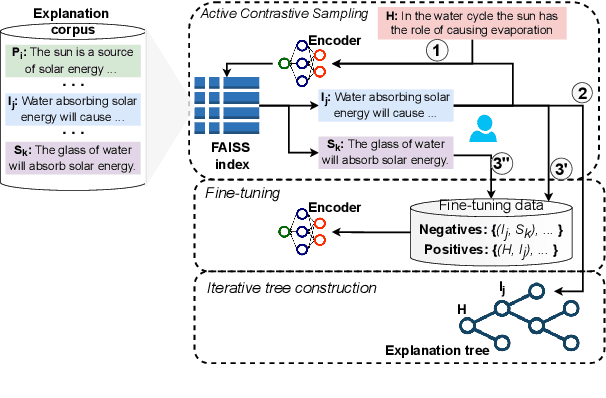
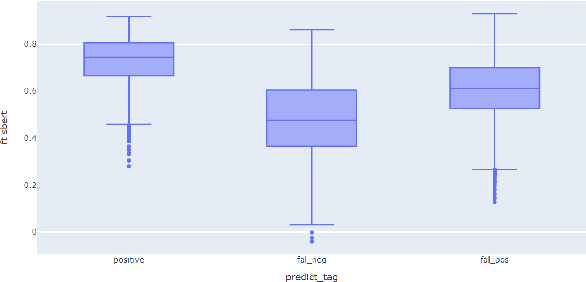
Entailment trees have been proposed to simulate the human reasoning process of explanation generation in the context of open--domain textual question answering. However, in practice, manually constructing these explanation trees proves a laborious process that requires active human involvement. Given the complexity of capturing the line of reasoning from question to the answer or from claim to premises, the issue arises of how to assist the user in efficiently constructing multi--level entailment trees given a large set of available facts. In this paper, we frame the construction of entailment trees as a sequence of active premise selection steps, i.e., for each intermediate node in an explanation tree, the expert needs to annotate positive and negative examples of premise facts from a large candidate list. We then iteratively fine--tune pre--trained Transformer models with the resulting positive and tightly controlled negative samples and aim to balance the encoding of semantic relationships and explanatory entailment relationships. Experimental evaluation confirms the measurable efficiency gains of the proposed active fine--tuning method in facilitating entailment trees construction: up to 20\% improvement in explanatory premise selection when compared against several alternatives.
Biologically-informed deep learning models for cancer: fundamental trends for encoding and interpreting oncology data
Jul 02, 2022



In this paper we provide a structured literature analysis focused on Deep Learning (DL) models used to support inference in cancer biology with a particular emphasis on multi-omics analysis. The work focuses on how existing models address the need for better dialogue with prior knowledge, biological plausibility and interpretability, fundamental properties in the biomedical domain. We discuss the recent evolutionary arch of DL models in the direction of integrating prior biological relational and network knowledge to support better generalisation (e.g. pathways or Protein-Protein-Interaction networks) and interpretability. This represents a fundamental functional shift towards models which can integrate mechanistic and statistical inference aspects. We discuss representational methodologies for the integration of domain prior knowledge in such models. The paper also provides a critical outlook into contemporary methods for explainability and interpretabiltiy. This analysis points in the direction of a convergence between encoding prior knowledge and improved interpretability.
Assessing the communication gap between AI models and healthcare professionals: explainability, utility and trust in AI-driven clinical decision-making
Apr 13, 2022



This paper contributes with a pragmatic evaluation framework for explainable Machine Learning (ML) models for clinical decision support. The study revealed a more nuanced role for ML explanation models, when these are pragmatically embedded in the clinical context. Despite the general positive attitude of healthcare professionals (HCPs) towards explanations as a safety and trust mechanism, for a significant set of participants there were negative effects associated with confirmation bias, accentuating model over-reliance and increased effort to interact with the model. Also, contradicting one of its main intended functions, standard explanatory models showed limited ability to support a critical understanding of the limitations of the model. However, we found new significant positive effects which repositions the role of explanations within a clinical context: these include reduction of automation bias, addressing ambiguous clinical cases (cases where HCPs were not certain about their decision) and support of less experienced HCPs in the acquisition of new domain knowledge.
Transformers and the representation of biomedical background knowledge
Feb 04, 2022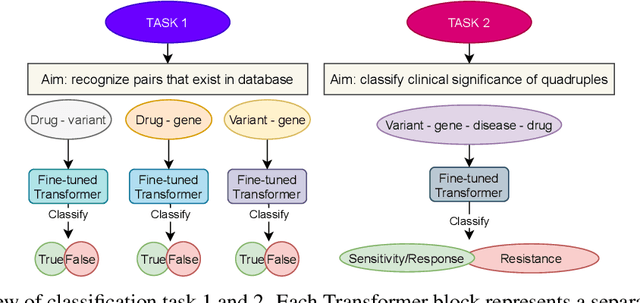

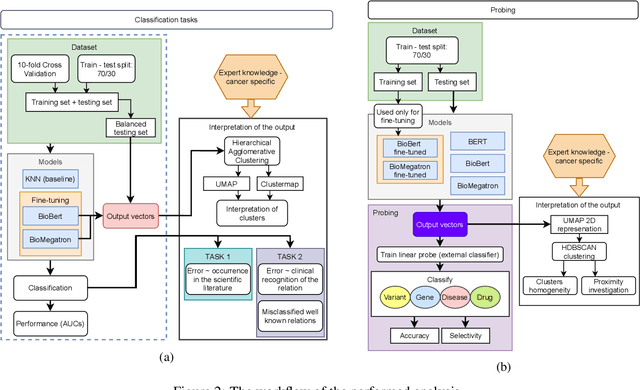
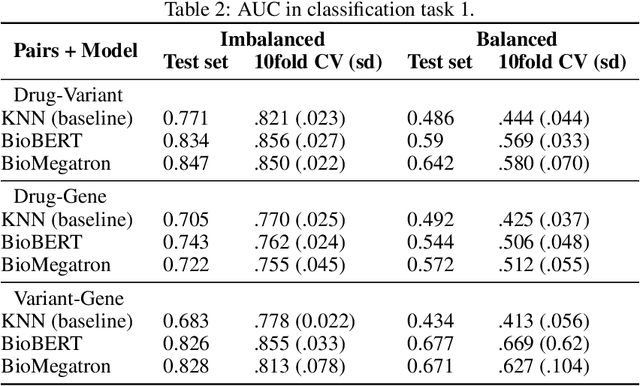
BioBERT and BioMegatron are Transformers models adapted for the biomedical domain based on publicly available biomedical corpora. As such, they have the potential to encode large-scale biological knowledge. We investigate the encoding and representation of biological knowledge in these models, and its potential utility to support inference in cancer precision medicine - namely, the interpretation of the clinical significance of genomic alterations. We compare the performance of different transformer baselines; we use probing to determine the consistency of encodings for distinct entities; and we use clustering methods to compare and contrast the internal properties of the embeddings for genes, variants, drugs and diseases. We show that these models do indeed encode biological knowledge, although some of this is lost in fine-tuning for specific tasks. Finally, we analyse how the models behave with regard to biases and imbalances in the dataset.