 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGem: Gaussian Mixture Model Embeddings for Numerical Feature Distributions
Oct 09, 2024Embeddings are now used to underpin a wide variety of data management tasks, including entity resolution, dataset search and semantic type detection. Such applications often involve datasets with numerical columns, but there has been more emphasis placed on the semantics of categorical data in embeddings than on the distinctive features of numerical data. In this paper, we propose a method called Gem (Gaussian mixture model embeddings) that creates embeddings that build on numerical value distributions from columns. The proposed method specializes a Gaussian Mixture Model (GMM) to identify and cluster columns with similar value distributions. We introduce a signature mechanism that generates a probability matrix for each column, indicating its likelihood of belonging to specific Gaussian components, which can be used for different applications, such as to determine semantic types. Finally, we generate embeddings for three numerical data properties: distributional, statistical, and contextual. Our core method focuses solely on numerical columns without using table names or neighboring columns for context. However, the method can be combined with other types of evidence, and we later integrate attribute names with the Gaussian embeddings to evaluate the method's contribution to improving overall performance. We compare Gem with several baseline methods for numeric only and numeric + context tasks, showing that Gem consistently outperforms the baselines on four benchmark datasets.
Active entailment encoding for explanation tree construction using parsimonious generation of hard negatives
Aug 02, 2022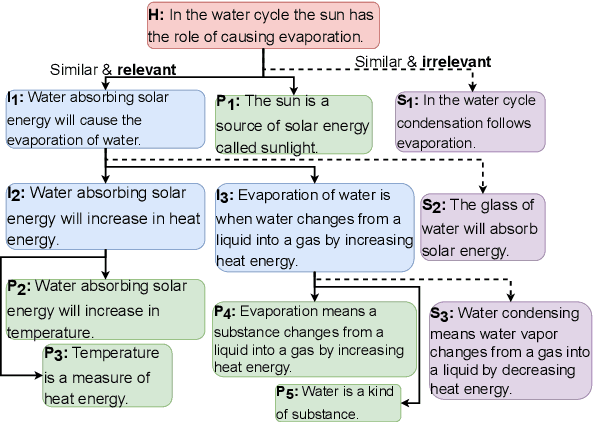
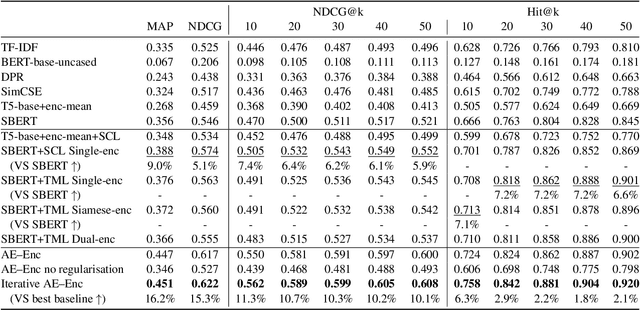
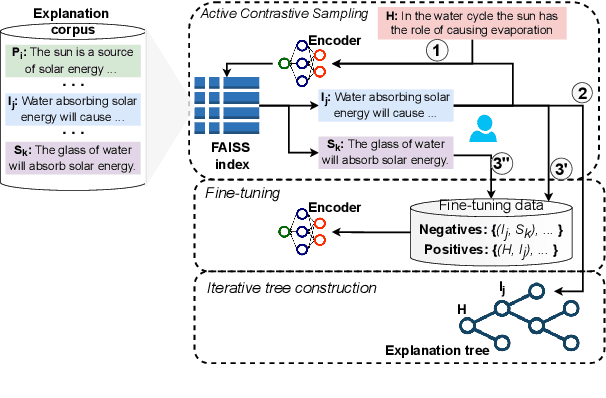
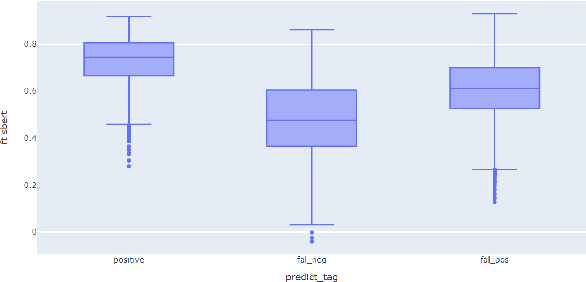
Entailment trees have been proposed to simulate the human reasoning process of explanation generation in the context of open--domain textual question answering. However, in practice, manually constructing these explanation trees proves a laborious process that requires active human involvement. Given the complexity of capturing the line of reasoning from question to the answer or from claim to premises, the issue arises of how to assist the user in efficiently constructing multi--level entailment trees given a large set of available facts. In this paper, we frame the construction of entailment trees as a sequence of active premise selection steps, i.e., for each intermediate node in an explanation tree, the expert needs to annotate positive and negative examples of premise facts from a large candidate list. We then iteratively fine--tune pre--trained Transformer models with the resulting positive and tightly controlled negative samples and aim to balance the encoding of semantic relationships and explanatory entailment relationships. Experimental evaluation confirms the measurable efficiency gains of the proposed active fine--tuning method in facilitating entailment trees construction: up to 20\% improvement in explanatory premise selection when compared against several alternatives.
Metareview-informed Explainable Cytokine Storm Detection during CAR-T cell Therapy
Jun 20, 2022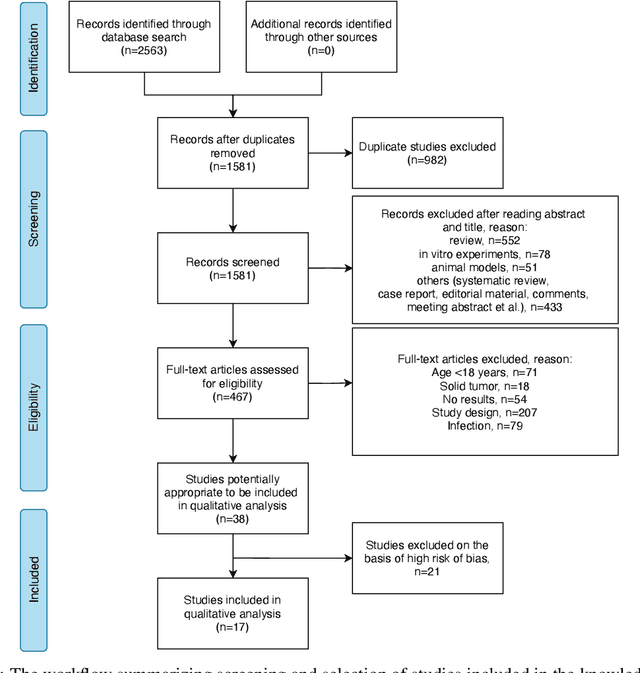
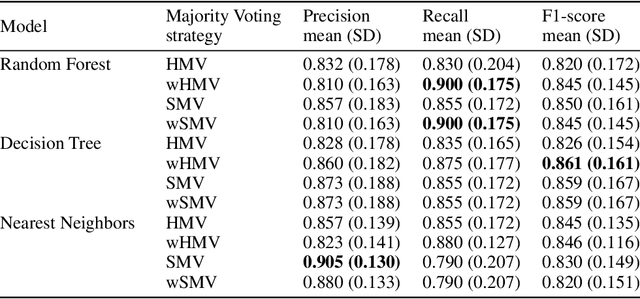
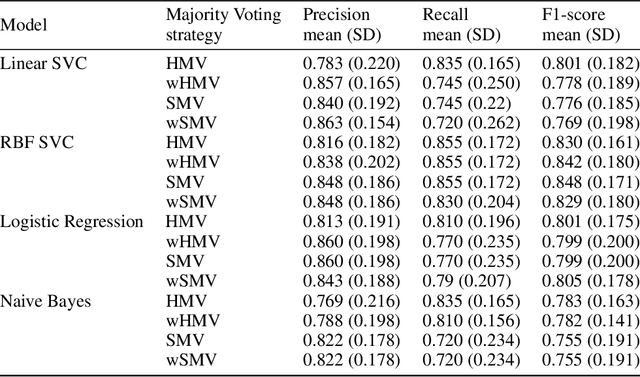
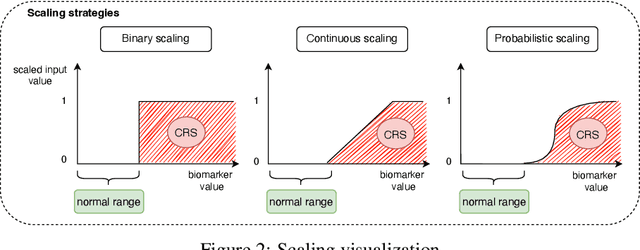
Cytokine release syndrome (CRS), also known as cytokine storm, is one of the most consequential adverse effects of chimeric antigen receptor therapies that have shown promising results in cancer treatment. When emerging, CRS could be identified by the analysis of specific cytokine and chemokine profiles that tend to exhibit similarities across patients. In this paper, we exploit these similarities using machine learning algorithms and set out to pioneer a meta--review informed method for the identification of CRS based on specific cytokine peak concentrations and evidence from previous clinical studies. We argue that such methods could support clinicians in analyzing suspect cytokine profiles by matching them against CRS knowledge from past clinical studies, with the ultimate aim of swift CRS diagnosis. During evaluation with real--world CRS clinical data, we emphasize the potential of our proposed method of producing interpretable results, in addition to being effective in identifying the onset of cytokine storm.
Cost-effective Variational Active Entity Resolution
Nov 20, 2020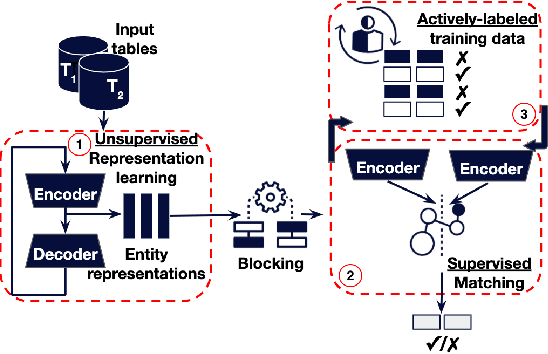
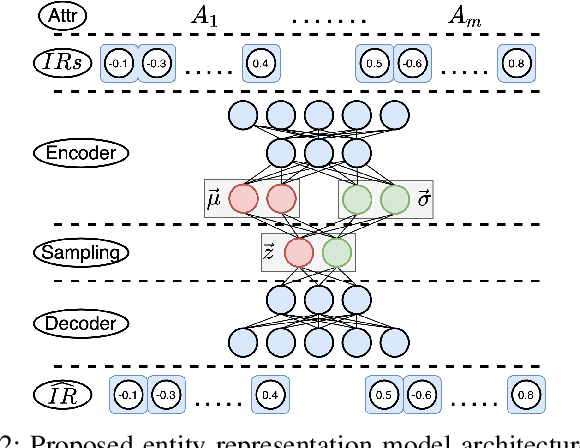
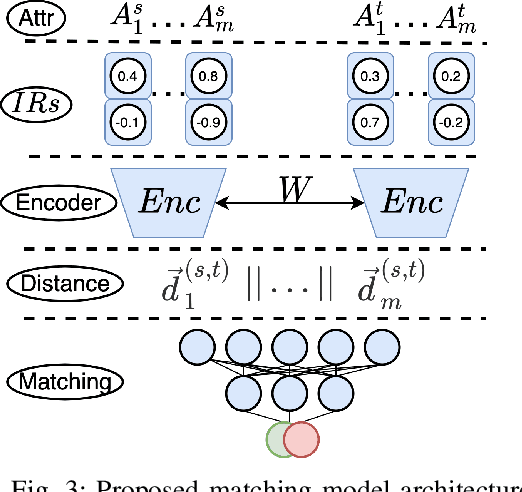
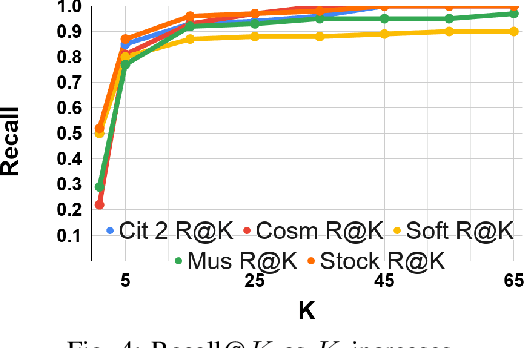
Accurately identifying different representations of the same real-world entity is an integral part of data cleaning and many methods have been proposed to accomplish it. The challenges of this entity resolution task that demand so much research attention are often rooted in the task-specificity and user-dependence of the process. Adopting deep learning techniques has the potential to lessen these challenges. In this paper, we set out to devise an entity resolution method that builds on the robustness conferred by deep autoencoders to reduce human-involvement costs. Specifically, we reduce the cost of training deep entity resolution models by performing unsupervised representation learning. This unveils a transferability property of the resulting model that can further reduce the cost of applying the approach to new datasets by means of transfer learning. Finally, we reduce the cost of labelling training data through an active learning approach that builds on the properties conferred by the use of deep autoencoders. Empirical evaluation confirms the accomplishment of our cost-reduction desideratum while achieving comparable effectiveness with state-of-the-art alternatives.