 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Radar-Camera Depth Estimation
Jun 05, 2025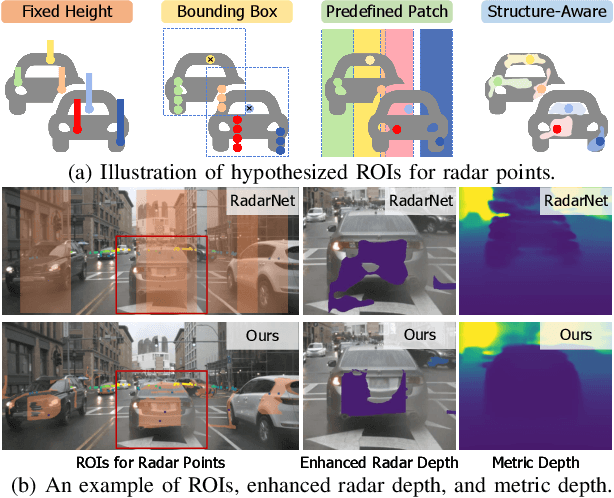
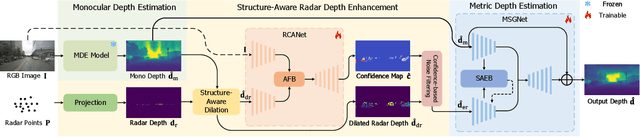
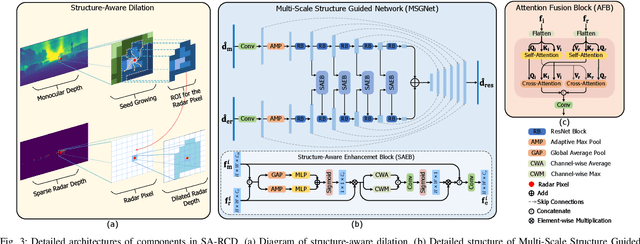
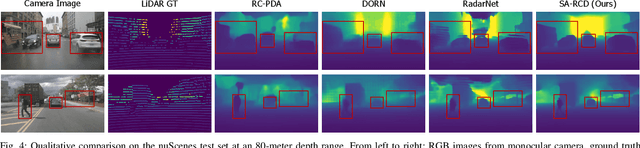
Monocular depth estimation aims to determine the depth of each pixel from an RGB image captured by a monocular camera. The development of deep learning has significantly advanced this field by facilitating the learning of depth features from some well-annotated datasets \cite{Geiger_Lenz_Stiller_Urtasun_2013,silberman2012indoor}. Eigen \textit{et al.} \cite{eigen2014depth} first introduce a multi-scale fusion network for depth regression. Following this, subsequent improvements have come from reinterpreting the regression task as a classification problem \cite{bhat2021adabins,Li_Wang_Liu_Jiang_2022}, incorporating additional priors \cite{shao2023nddepth,yang2023gedepth}, and developing more effective objective function \cite{xian2020structure,Yin_Liu_Shen_Yan_2019}. Despite these advances, generalizing to unseen domains remains a challenge. Recently, several methods have employed affine-invariant loss to enable multi-dataset joint training \cite{MiDaS,ZeroDepth,guizilini2023towards,Dany}. Among them, Depth Anything \cite{Dany} has shown leading performance in zero-shot monocular depth estimation. While it struggles to estimate accurate metric depth due to the lack of explicit depth cues, it excels at extracting structural information from unseen images, producing structure-detailed monocular depth.
COV19IR : COVID-19 Domain Literature Information Retrieval
Nov 08, 2022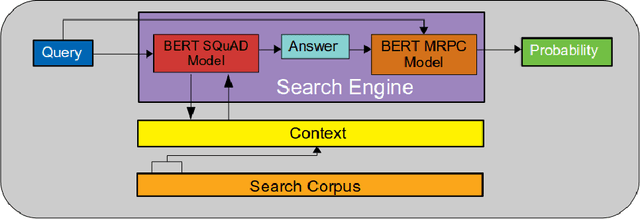
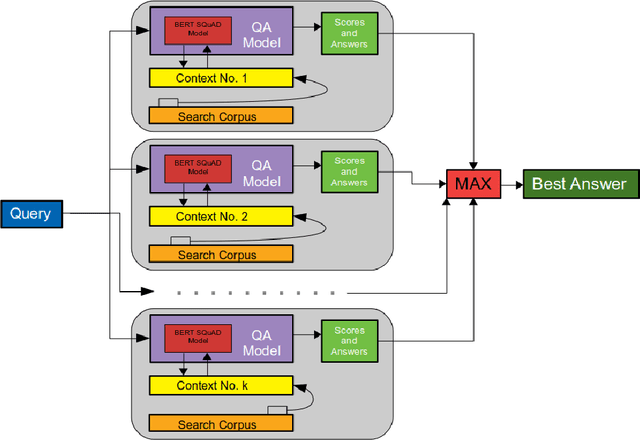
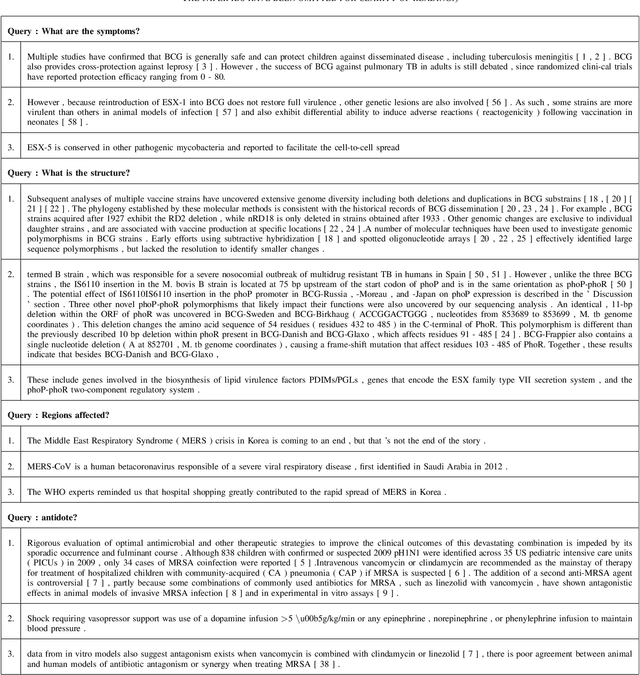
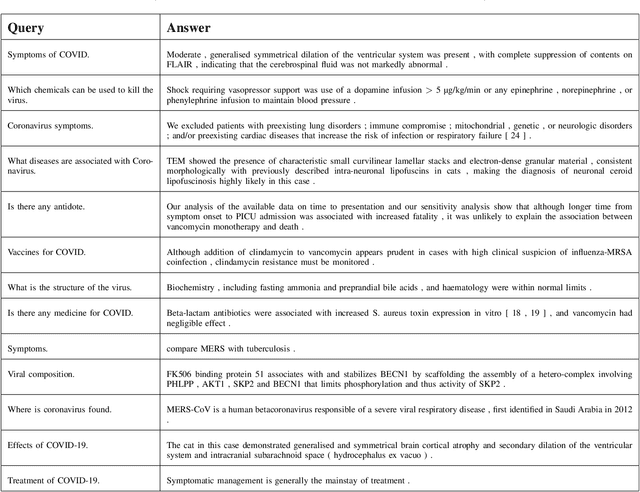
Increasing number of COVID-19 research literatures cause new challenges in effective literature screening and COVID-19 domain knowledge aware Information Retrieval. To tackle the challenges, we demonstrate two tasks along withsolutions, COVID-19 literature retrieval, and question answering. COVID-19 literature retrieval task screens matching COVID-19 literature documents for textual user query, and COVID-19 question answering task predicts proper text fragments from text corpus as the answer of specific COVID-19 related questions. Based on transformer neural network, we provided solutions to implement the tasks on CORD-19 dataset, we display some examples to show the effectiveness of our proposed solutions.
Active entailment encoding for explanation tree construction using parsimonious generation of hard negatives
Aug 02, 2022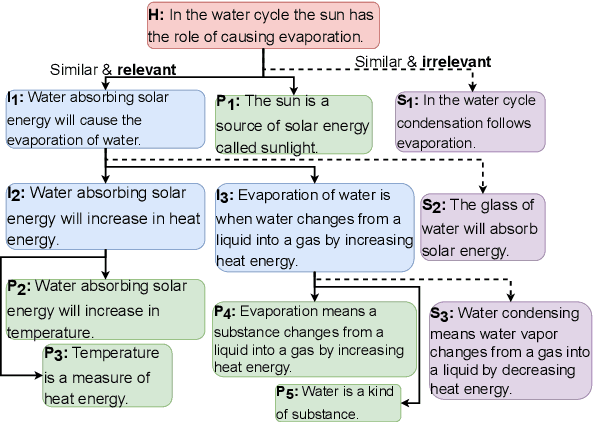
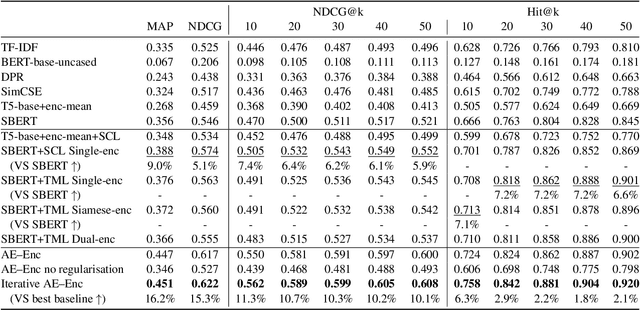
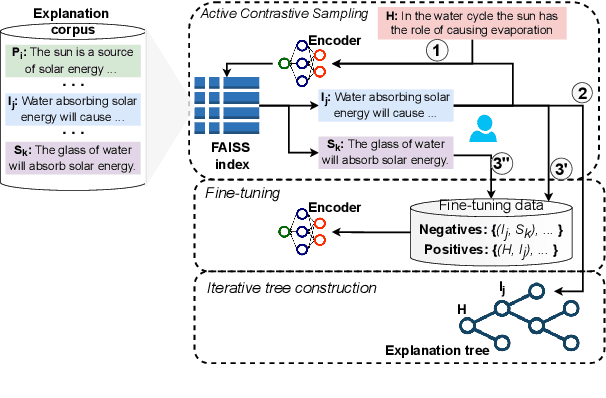
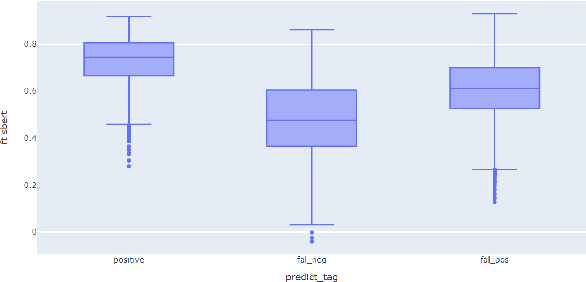
Entailment trees have been proposed to simulate the human reasoning process of explanation generation in the context of open--domain textual question answering. However, in practice, manually constructing these explanation trees proves a laborious process that requires active human involvement. Given the complexity of capturing the line of reasoning from question to the answer or from claim to premises, the issue arises of how to assist the user in efficiently constructing multi--level entailment trees given a large set of available facts. In this paper, we frame the construction of entailment trees as a sequence of active premise selection steps, i.e., for each intermediate node in an explanation tree, the expert needs to annotate positive and negative examples of premise facts from a large candidate list. We then iteratively fine--tune pre--trained Transformer models with the resulting positive and tightly controlled negative samples and aim to balance the encoding of semantic relationships and explanatory entailment relationships. Experimental evaluation confirms the measurable efficiency gains of the proposed active fine--tuning method in facilitating entailment trees construction: up to 20\% improvement in explanatory premise selection when compared against several alternatives.
Transformers and the representation of biomedical background knowledge
Feb 04, 2022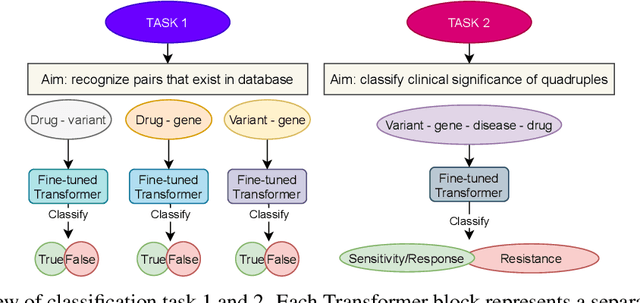

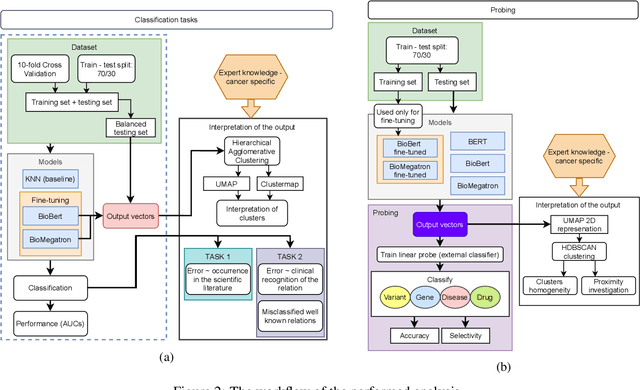
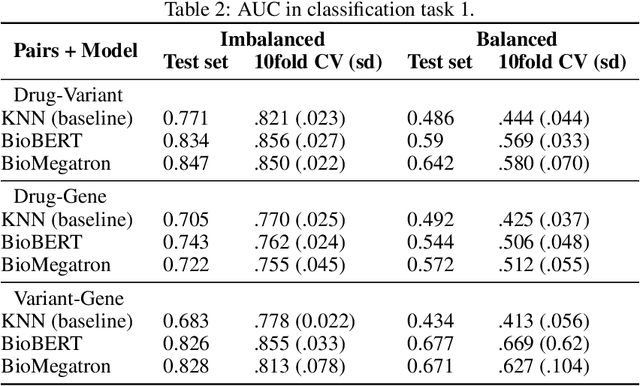
BioBERT and BioMegatron are Transformers models adapted for the biomedical domain based on publicly available biomedical corpora. As such, they have the potential to encode large-scale biological knowledge. We investigate the encoding and representation of biological knowledge in these models, and its potential utility to support inference in cancer precision medicine - namely, the interpretation of the clinical significance of genomic alterations. We compare the performance of different transformer baselines; we use probing to determine the consistency of encodings for distinct entities; and we use clustering methods to compare and contrast the internal properties of the embeddings for genes, variants, drugs and diseases. We show that these models do indeed encode biological knowledge, although some of this is lost in fine-tuning for specific tasks. Finally, we analyse how the models behave with regard to biases and imbalances in the dataset.
PhysNLU: A Language Resource for Evaluating Natural Language Understanding and Explanation Coherence in Physics
Jan 12, 2022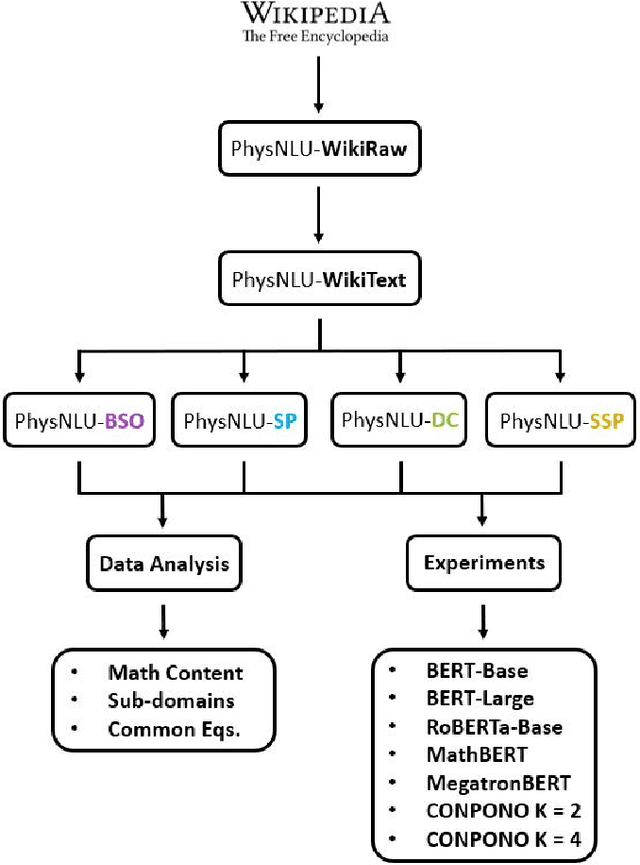
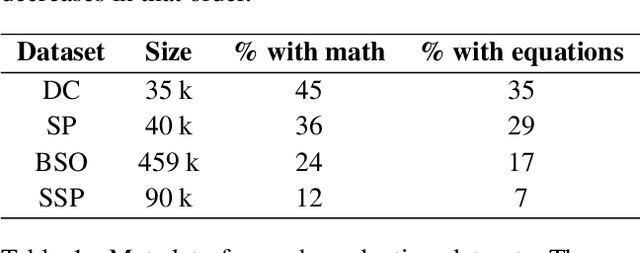

In order for language models to aid physics research, they must first encode representations of mathematical and natural language discourse which lead to coherent explanations, with correct ordering and relevance of statements. We present a collection of datasets developed to evaluate the performance of language models in this regard, which measure capabilities with respect to sentence ordering, position, section prediction, and discourse coherence. Analysis of the data reveals equations and sub-disciplines which are most common in physics discourse, as well as the sentence-level frequency of equations and expressions. We present baselines which demonstrate how contemporary language models are challenged by coherence related tasks in physics, even when trained on mathematical natural language objectives.
Encoding Explanatory Knowledge for Zero-shot Science Question Answering
May 19, 2021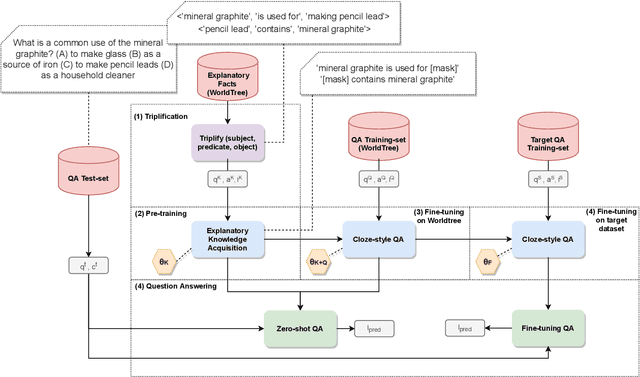
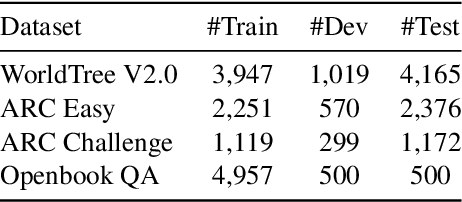

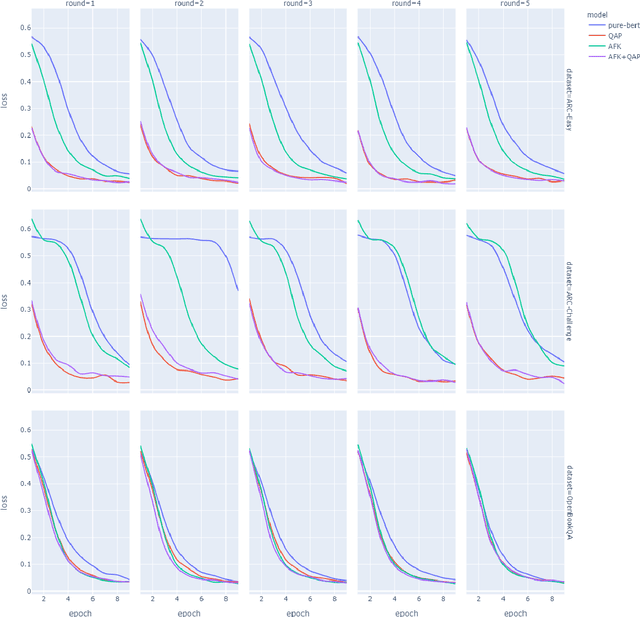
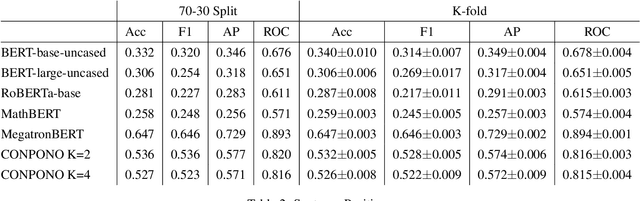
This paper describes N-XKT (Neural encoding based on eXplanatory Knowledge Transfer), a novel method for the automatic transfer of explanatory knowledge through neural encoding mechanisms. We demonstrate that N-XKT is able to improve accuracy and generalization on science Question Answering (QA). Specifically, by leveraging facts from background explanatory knowledge corpora, the N-XKT model shows a clear improvement on zero-shot QA. Furthermore, we show that N-XKT can be fine-tuned on a target QA dataset, enabling faster convergence and more accurate results. A systematic analysis is conducted to quantitatively analyze the performance of the N-XKT model and the impact of different categories of knowledge on the zero-shot generalization task.
Multi-Fusion Chinese WordNet (MCW) : Compound of Machine Learning and Manual Correction
Feb 05, 2020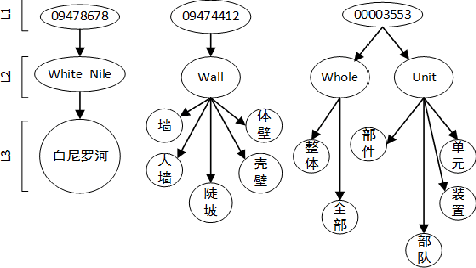
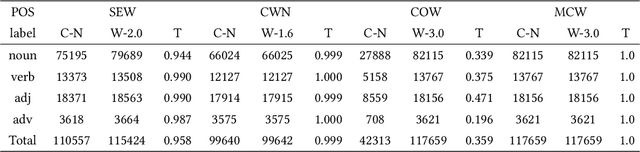
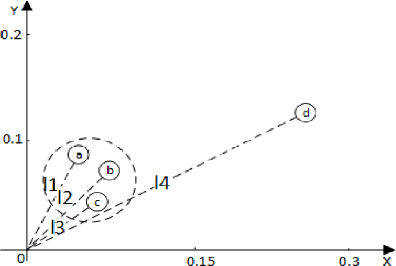
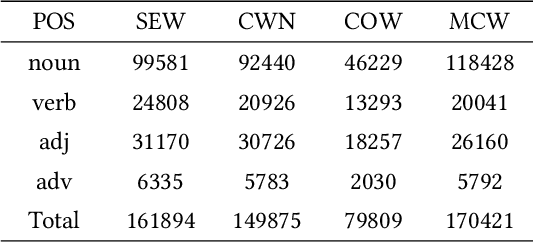
Princeton WordNet (PWN) is a lexicon-semantic network based on cognitive linguistics, which promotes the development of natural language processing. Based on PWN, five Chinese wordnets have been developed to solve the problems of syntax and semantics. They include: Northeastern University Chinese WordNet (NEW), Sinica Bilingual Ontological WordNet (BOW), Southeast University Chinese WordNet (SEW), Taiwan University Chinese WordNet (CWN), Chinese Open WordNet (COW). By using them, we found that these word networks have low accuracy and coverage, and cannot completely portray the semantic network of PWN. So we decided to make a new Chinese wordnet called Multi-Fusion Chinese Wordnet (MCW) to make up those shortcomings. The key idea is to extend the SEW with the help of Oxford bilingual dictionary and Xinhua bilingual dictionary, and then correct it. More specifically, we used machine learning and manual adjustment in our corrections. Two standards were formulated to help our work. We conducted experiments on three tasks including relatedness calculation, word similarity and word sense disambiguation for the comparison of lemma's accuracy, at the same time, coverage also was compared. The results indicate that MCW can benefit from coverage and accuracy via our method. However, it still has room for improvement, especially with lemmas. In the future, we will continue to enhance the accuracy of MCW and expand the concepts in it.