 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the Causal Effects of Natural Logic Features in Transformer-Based NLI Models
Paper and Code

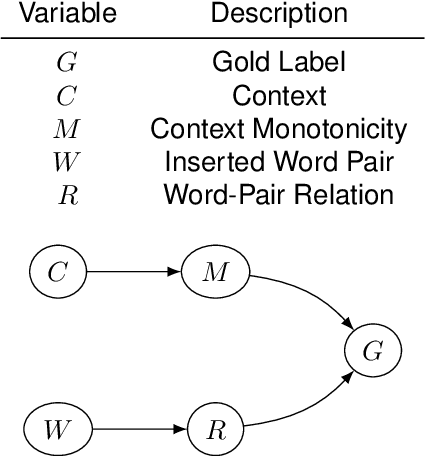
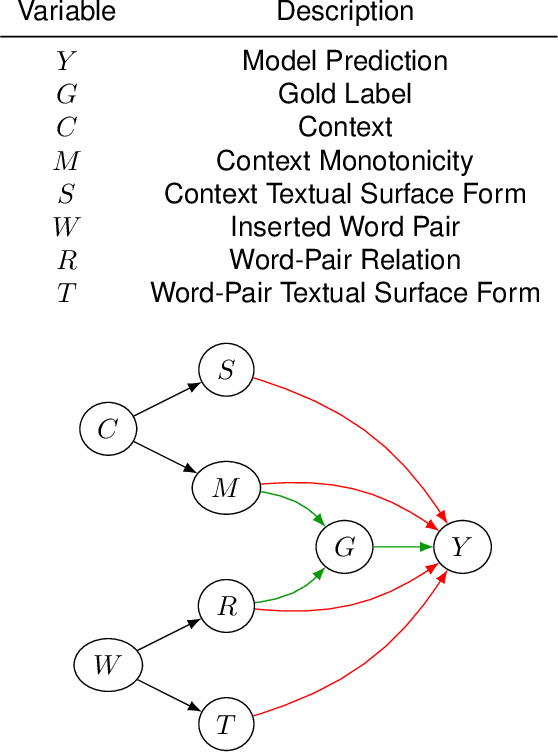

Rigorous evaluation of the causal effects of semantic features on language model predictions can be hard to achieve for natural language reasoning problems. However, this is such a desirable form of analysis from both an interpretability and model evaluation perspective, that it is valuable to investigate specific patterns of reasoning with enough structure and regularity to identify and quantify systematic reasoning failures in widely-used models. In this vein, we pick a portion of the NLI task for which an explicit causal diagram can be systematically constructed: the case where across two sentences (the premise and hypothesis), two related words/terms occur in a shared context. In this work, we apply causal effect estimation strategies to measure the effect of context interventions (whose effect on the entailment label is mediated by the semantic monotonicity characteristic) and interventions on the inserted word-pair (whose effect on the entailment label is mediated by the relation between these words). Extending related work on causal analysis of NLP models in different settings, we perform an extensive interventional study on the NLI task to investigate robustness to irrelevant changes and sensitivity to impactful changes of Transformers. The results strongly bolster the fact that similar benchmark accuracy scores may be observed for models that exhibit very different behaviour. Moreover, our methodology reinforces previously suspected biases from a causal perspective, including biases in favour of upward-monotone contexts and ignoring the effects of negation markers.