 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrow Up and Merge: Scaling Strategies for Efficient Language Adaptation
Dec 11, 2025Achieving high-performing language models which include medium- and lower-resource languages remains a challenge. Massively multilingual models still underperform compared to language-specific adaptations, especially at smaller model scales. In this work, we investigate scaling as an efficient strategy for adapting pretrained models to new target languages. Through comprehensive scaling ablations with approximately FLOP-matched models, we test whether upscaling an English base model enables more effective and resource-efficient adaptation than standard continued pretraining. We find that, once exposed to sufficient target-language data, larger upscaled models can match or surpass the performance of smaller models continually pretrained on much more data, demonstrating the benefits of scaling for data efficiency. Scaling also helps preserve the base model's capabilities in English, thus reducing catastrophic forgetting. Finally, we explore whether such scaled, language-specific models can be merged to construct modular and flexible multilingual systems. We find that while merging remains less effective than joint multilingual training, upscaled merges perform better than smaller ones. We observe large performance differences across merging methods, suggesting potential for improvement through merging approaches specialized for language-level integration.
How Good is Your Wikipedia?
Nov 08, 2024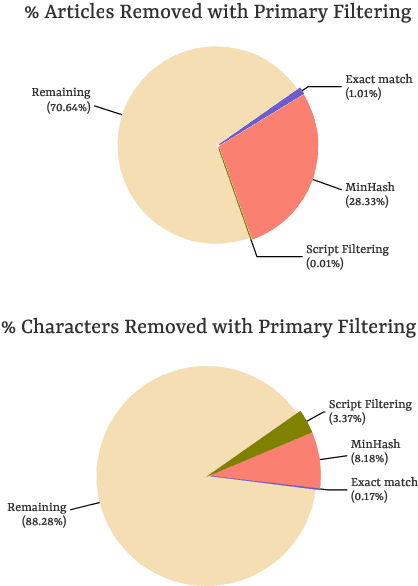

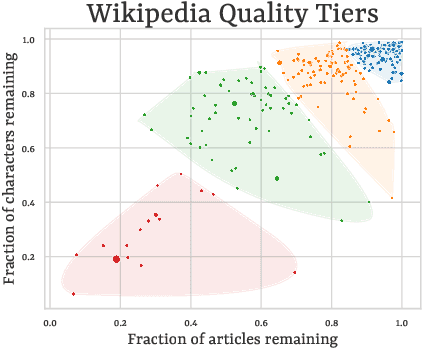
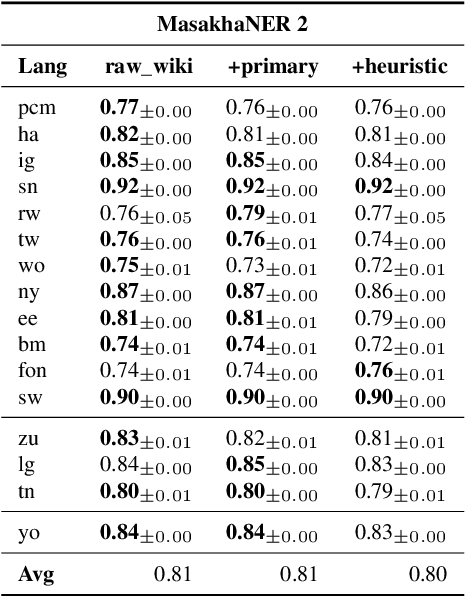
Wikipedia's perceived high quality and broad language coverage have established it as a fundamental resource in multilingual NLP. In the context of low-resource languages, however, these quality assumptions are increasingly being scrutinised. This paper critically examines the data quality of Wikipedia in a non-English setting by subjecting it to various quality filtering techniques, revealing widespread issues such as a high percentage of one-line articles and duplicate articles. We evaluate the downstream impact of quality filtering on Wikipedia and find that data quality pruning is an effective means for resource-efficient training without hurting performance, especially for low-resource languages. Moreover, we advocate for a shift in perspective from seeking a general definition of data quality towards a more language- and task-specific one. Ultimately, we aim for this study to serve as a guide to using Wikipedia for pretraining in a multilingual setting.
CreoleVal: Multilingual Multitask Benchmarks for Creoles
Oct 30, 2023Creoles represent an under-explored and marginalized group of languages, with few available resources for NLP research. While the genealogical ties between Creoles and other highly-resourced languages imply a significant potential for transfer learning, this potential is hampered due to this lack of annotated data. In this work we present CreoleVal, a collection of benchmark datasets spanning 8 different NLP tasks, covering up to 28 Creole languages; it is an aggregate of brand new development datasets for machine comprehension, relation classification, and machine translation for Creoles, in addition to a practical gateway to a handful of preexisting benchmarks. For each benchmark, we conduct baseline experiments in a zero-shot setting in order to further ascertain the capabilities and limitations of transfer learning for Creoles. Ultimately, the goal of CreoleVal is to empower research on Creoles in NLP and computational linguistics. We hope this resource will contribute to technological inclusion for Creole language users around the globe.
A Large-Scale Comparison of Historical Text Normalization Systems
Apr 03, 2019

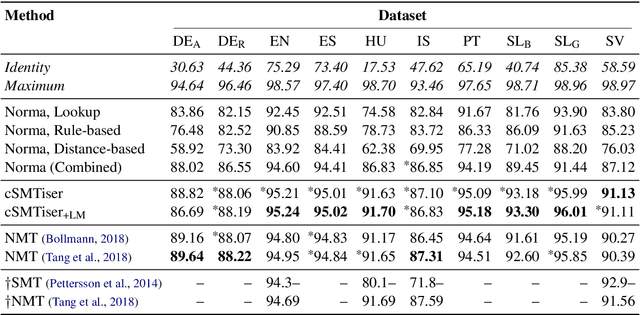

There is no consensus on the state-of-the-art approach to historical text normalization. Many techniques have been proposed, including rule-based methods, distance metrics, character-based statistical machine translation, and neural encoder--decoder models, but studies have used different datasets, different evaluation methods, and have come to different conclusions. This paper presents the largest study of historical text normalization done so far. We critically survey the existing literature and report experiments on eight languages, comparing systems spanning all categories of proposed normalization techniques, analysing the effect of training data quantity, and using different evaluation methods. The datasets and scripts are made publicly available.
Few-Shot and Zero-Shot Learning for Historical Text Normalization
Mar 12, 2019
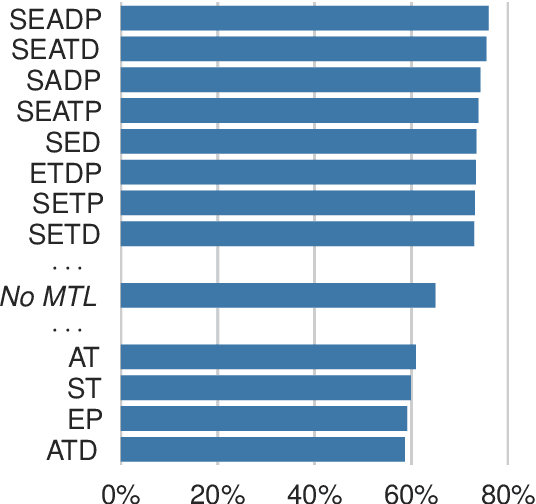
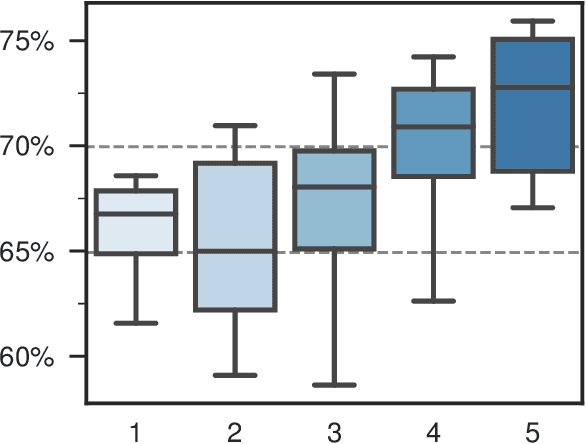
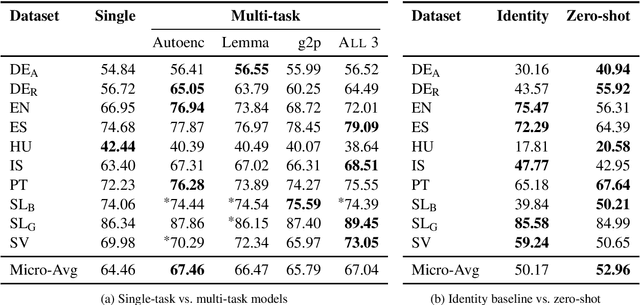
Historical text normalization often relies on small training datasets. Recent work has shown that multi-task learning can sometimes lead to significant improvements by exploiting synergies with related datasets, but there has been no systematic study of multi-task learning strategies across different datasets from different languages. This paper evaluates 63 multi-task learning strategies for sequence-to-sequence-based historical text normalization across ten datasets from eight languages, using autoencoding, grapheme-to-phoneme mapping, and lemmatization as auxiliary tasks. We observe consistent, significant improvements across languages when training data for the target task is limited, but minimal or no improvements when training data is abundant. Finally, we show that zero-shot learning outperforms the simple, but relatively strong, identity baseline.
Improving historical spelling normalization with bi-directional LSTMs and multi-task learning
Oct 25, 2016


Natural-language processing of historical documents is complicated by the abundance of variant spellings and lack of annotated data. A common approach is to normalize the spelling of historical words to modern forms. We explore the suitability of a deep neural network architecture for this task, particularly a deep bi-LSTM network applied on a character level. Our model compares well to previously established normalization algorithms when evaluated on a diverse set of texts from Early New High German. We show that multi-task learning with additional normalization data can improve our model's performance further.